我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 SageMaker 中的合成数据增加欺诈交易
开发和训练成功的机器学习 (ML) 欺诈模型需要访问大量的高质量数据。获取这些数据具有挑战性,因为可用的数据集有时不够大或不够公正,无法有效地训练机器学习模型,并且可能需要大量的成本和时间。监管和隐私要求进一步防止数据使用或共享,即使在企业组织内部也是如此。授权使用和访问敏感数据的过程通常会延迟或使机器学习项目脱轨。或者,我们可以通过生成和使用合成数据来应对这些挑战。
合成数据描述了人工创建的数据集,这些数据集模仿了原始数据集中的内容和模式,以应对监管风险和合规性、时间和采购成本。合成数据生成器使用真实数据来学习相关的特征、相关性和模式,以便生成与最初采集的数据集的统计质量相匹配的所需数量的合成数据。
合成数据已在实验室环境中使用了
英国监管机构金融行为监管局(Financial Contrace Authority)
这是一篇由两部分组成的博客文章;我们在第一部分创建合成数据,并在
在这篇博客文章中,您将学习如何使用开源库
解决方案概述
本教程的目的是使用 名为
我们使用由
我们使用包括亚马逊 SageMaker 和 Amazon S3 在内的 亚马逊云科技 服务,使用云资源会产生费用。
设置开发环境
SageMaker 提供托管 Jupyter 笔记本实例,用于模型构建、训练和部署。
先决条件:
你必须拥有 亚马逊云科技 账户才能运行 SageMaker。你可以
有关设置 Jupyter 笔记本电脑工作环境的说明,请参阅亚马逊
第 1 步:设置您的亚马逊 SageMaker 实例
- 登录 亚马逊云科技 控制台并搜索 “SageMaker”。
- 选择 工作室 。
-
在左侧栏中选择
笔记本实例
,然后选择
创建笔记本实例
。
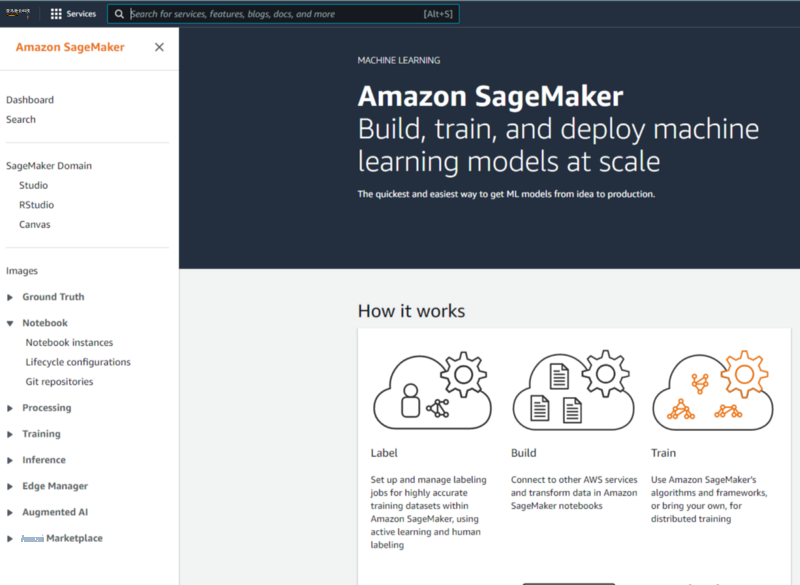
-
在下一页(如下图所示)中,根据需要选择虚拟机 (VM) 的配置,然后选择
创建笔记本实例
。请注意,我们使用了没有 GPU 和 5 GB 数据的 ML 优化虚拟机、运行亚马逊 Linux 2 的 ml.t3.medium 和 Jupyter Lab 3 内核。
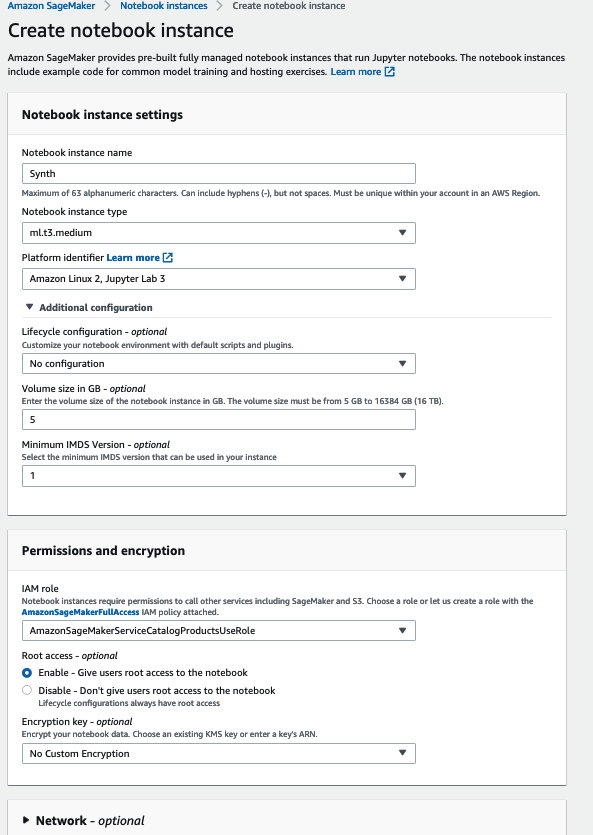
- 笔记本实例将在几分钟内准备就绪,可供您使用。
-
选择 “
打开 Jupyter
Lab” 进行启动。
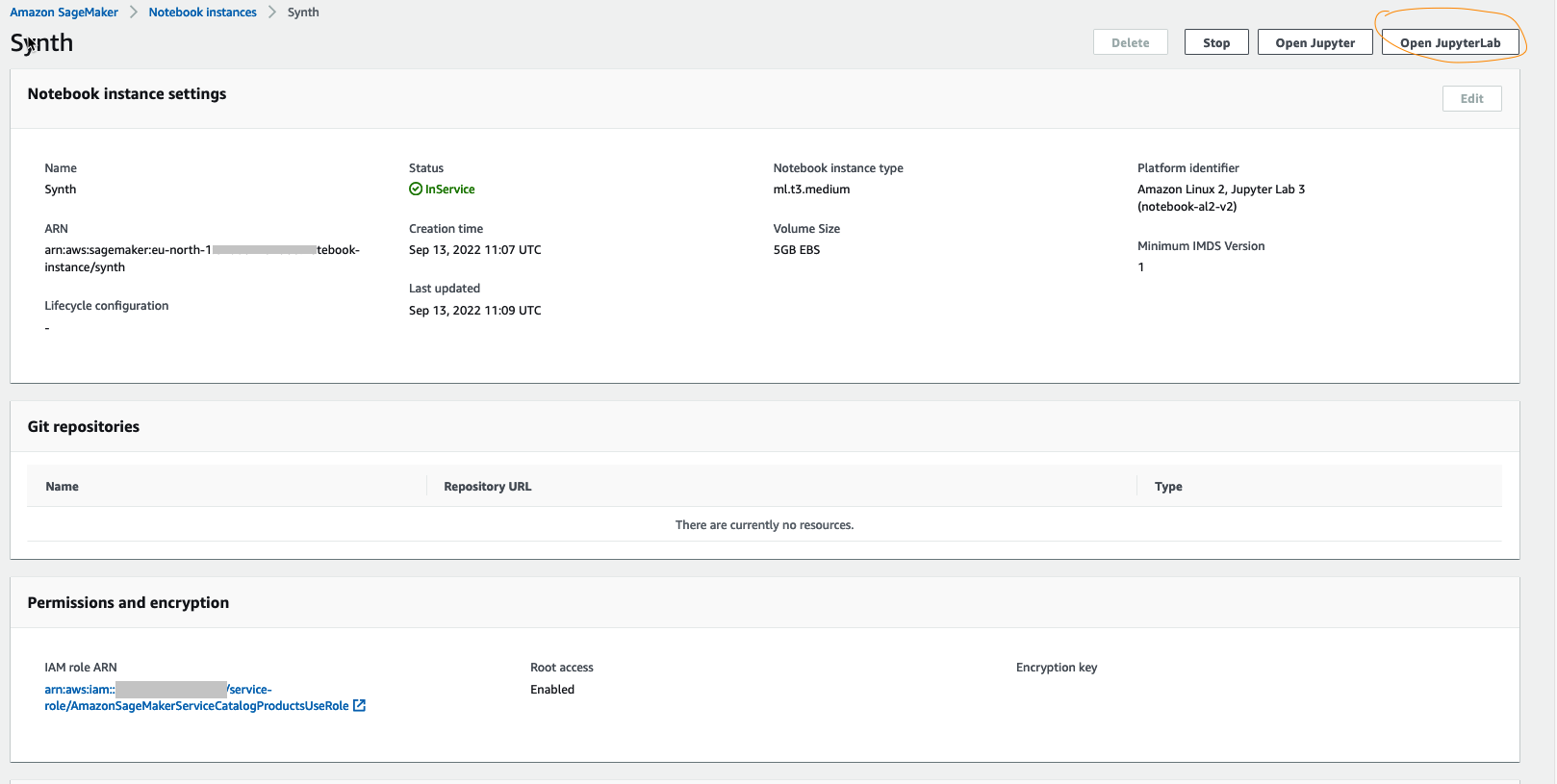
- 现在我们有了符合所需规格的 JupyterLab,我们将安装合成库。
步骤 2:下载或提取真实数据集以创建合成数据
如果您有 Kaggle 帐户,可以像我们在此处一样手动 从 Kaggle
如果你直接使用这些数据进行机器学习预测,模型可能总能学会预测 “不是欺诈”。由于欺诈案例很少见,因此模型在非欺诈案例中很容易获得更高的准确性。但是,由于检测欺诈案例是我们在本次练习中的目标,因此我们将使用基于真实数据建模的合成数据来增加欺诈类别的数量。
在 JupyterLab 中创建一个数据文件夹,然后将 Kaggle 数据文件上传到其中。这将允许您使用笔记本中的数据,因为 SageMaker
这个数据集是 144 MB
然后,你可以通过 pandas 库使用标准代码读取数据:
欺诈检测数据具有某些特征,即:
- 大类失衡(通常指非欺诈数据点)。
- 与隐私有关的问题(由于敏感数据的存在)。
- 一定程度的活力,因为恶意用户总是试图逃避系统监控欺诈性交易的检测。
- 可用的数据集非常大,通常没有标签。
现在您已经检查了数据集,让我们筛选少数群体(信用卡数据集中的 “欺诈” 类别)并根据需要进行转换。你可以从这个
当这个少数族裔数据集被合成并重新添加到原始数据集时,它允许生成一个更大的合成数据集来解决数据的不平衡问题。通过 使用新数据集
让我们综合一下新的欺诈数据集。
第 3 步:训练合成器并创建模型
既然您可以在 SageMaker 中随时获得数据,那么是时候使用我们的合成 GAN 模型了。
生成对抗网络 (GAN) 有两个部分:
生成 器 学会生成合理的数据。生成的实例成为鉴别器的负面训练示例。
鉴别器 学会区分生成器的虚假数据和真实数据。鉴别器会因为生成难以置信的结果而惩罚生成器。
当训练开始时,生成器会生成明显的虚假数据,鉴别器很快就会学会分辨出它是假的。随着训练的进展,生成器越来越接近于产生可以欺骗鉴别器的输出。最后,如果生成器训练顺利,则判别器在分辨真假差异方面会变得更糟。它开始将虚假数据归类为真实数据,其准确性降低了。
生成器和鉴别器都是神经网络。生成器输出直接连接到鉴别器输入。通过
步骤 4:从合成器采样合成数据
现在您已经构建并训练了模型,是时候通过向模型输入噪声来对所需数据进行采样了。这使您能够生成任意数量的合成数据。
在这种情况下,您生成的合成数据量等于实际数据量,因为这样可以更轻松地比较步骤 5 中相似的样本量。
我们可以选择对包含欺诈性交易的行进行抽样——与非合成欺诈数据结合使用时,将导致 “欺诈” 和 “非欺诈” 类别的平均分布。最初的
我们可以选择通过一种称为数据增强的过程对包含欺诈性交易的行进行向上采样——与非合成欺诈数据结合使用时,将导致 “欺诈” 和 “非欺诈” 类别的平均分布。
步骤 5:将合成数据与真实数据进行比较和评估
尽管此步骤是可选的,但您可以使用散点图对照实际数据对生成的合成数据进行定性可视化和评估。
这有助于我们通过调整参数、更改样本数量和进行其他转换来迭代模型,从而生成最准确的合成数据。这种准确性的本质始终取决于合成的目的
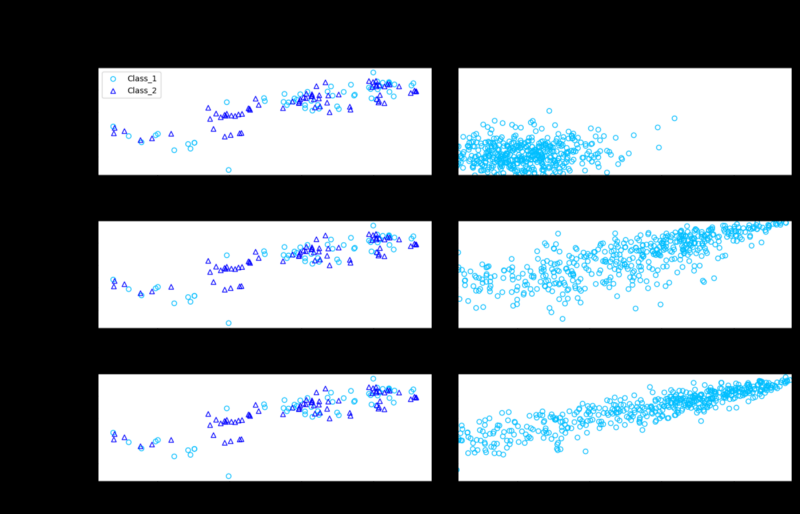
下图描绘了在整个培训步骤中实际欺诈和合成欺诈数据点的相似程度。这可以很好地对合成数据和实际数据之间的相似性进行定性检查,以及随着我们对其进行更长的时代(整个训练数据集通过算法传输),这种相似性会得到改善。请注意,随着我们运行更多的时代,合成数据模式集越来越接近原始数据。
步骤 6:清理
最后,在完成合成后停止笔记本实例,以避免意外成本。
结论
随着机器学习算法和编码框架的
你可以在这本
在这个由两
作者简介

*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。