我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
在 EC2 上的 Amazon EMR 上使用实例队列架构容错应用程序
组织依靠 EC2 集群上的 Amazon EMR 来使用 Apache Spark、Apache Hive 和 Trino 等框架处理大规模数据负载。电视广告或计划外促销等活动可能会导致计算容量需求增加,因此必须进行有效的容量规划,以确保您的工作负载不会达到容量限制或作业失败。
一种常见的场景是使用一致的亚马逊弹性计算云(Amazon EC2)实例类型(例如,集群的单一实例大小和系列)在 Amazon EMR 上每天运行 Spark 作业。尽管这可能很好地维持基准,但峰值可能会触发自动扩展,这缩小了尝试停止和重新启动更大的 EMR 集群时容量可用性的机会,因为特定的按需实例池可能缺乏满足需求的容量。
在这篇文章中,我们展示了如何通过分析 EMR 工作负载和实施针对您的工作负载模式量身定制的策略来优化容量。我们将逐步评估工作负载的历史计算使用量,并结合使用多种策略来降低 Amazon EMR 启动特定 EC2 实例类型时出现容量不足异常 (ICE) 的可能性。我们实施灵活的实例队列策略以减少对特定实例类型的依赖,并使用 Amazon EC2 按需容量预留 (ODCR) 来处理可预测的稳定状态工作负载。采用这种方法可以帮助防止由于容量限制而导致的任务失败,同时优化集群的成本和性能。
解决方案概述
Amazon EMR 中的实例队列为管理集群内的 EC2 实例提供了一种灵活而可靠的方式。此功能允许您为按需实例和竞价型实例指定目标容量,为每个队列选择最多五个 EC2 实例类型(使用亚马逊云科技命令行接口 [亚马逊云科技 CLI] 和带有分配策略的 API 时,可选择 30 个),并在不同的可用区中使用多个子网。重要的是,实例队列支持使用 ODCR,使您能够将 EMR 集群与预先购买的 EC2 容量保持一致。您可以将实例队列配置为首选或需要容量预留,从而确保 EMR 集群高效使用您的预留容量。
EMR 工作负载模式通常分为两类:稳定和可变(尖峰)。在以下各节中,我们将探讨如何使用实例队列提供的各种选项针对每种模式进行优化,首先是稳定的工作负载,然后处理可变的工作负载。
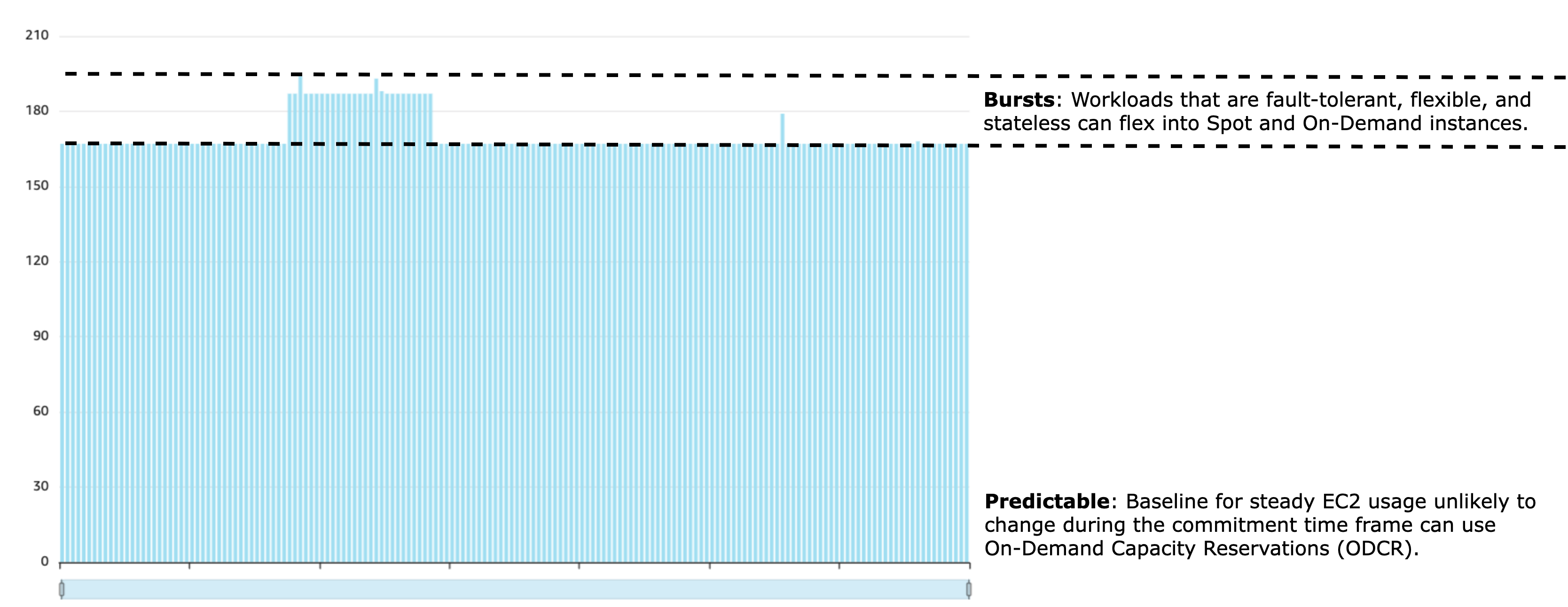
稳定的工作负载是指具有可预测资源利用模式的工作负载;例如,制药提供商每天需要处理 21 TB 的研究数据、患者记录和其他信息。工作负载是一致的,需要每天在长时间运行的持久集群上可靠地运行。对于需要高可靠性和有保障容量的关键业务运营,我们建议在容量规划中预留基准容量。我们演示了以下步骤:
- 使用亚马逊云科技成本和使用情况报告 (亚马逊云科技 CUR) 来估算现有工作负载的基准。
- 使用 ODCR 预留基准容量。
- 将 Amazon EMR 配置为使用目标 ODCR。
尖峰工作负载是由处理需求的不可预测且通常是显著的波动所定义的。这些激增可能由各种因素(例如批处理、实时数据流或季节性业务波动)触发,这些因素会触发 Amazon EMR 请求更多容量以满足需求。我们通过使用实例和可用区域灵活性来解决资源分配问题,具体步骤如下:
- 通过 EMR 实例队列引入 EC2 实例灵活性。
- 通过 EMR 实例队列的智能子网选择实现弹性。
- 使用托管扩展来自动管理向内和向外扩展。
稳定的工作负载
在本节中,我们将演示如何定义您的基准、配置 Amazon Identity and Access Management (IAM) 权限、创建 ODCR、将您的预留与容量组关联以及如何配置 Amazon EMR 以使用目标 ODCR。您可以选择混合型 ODCR 策略,例如,一个持续时间较短的 ODCR 支持启动 EMR 集群,另一个持续时间更长的 ODCR,根据基准容量预留支持您的任务节点。
估算基线
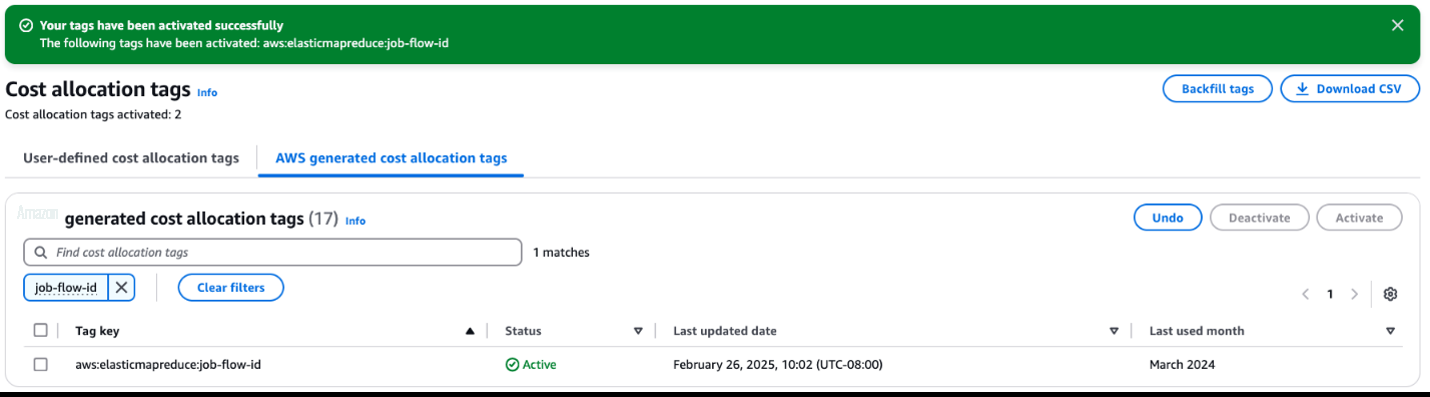
确保激活亚马逊云科技生成的成本分配标签 aws:elasticmapreduce:job-flow-id。这使得亚马逊云科技 CUR resource_tags_aws_elasticmapreduce_job_flow_id 中的字段可以填充 EMR 集群 ID,并由解决方案中的 SQL 查询使用。要从亚马逊云科技账单控制台激活成本分配标签,请完成以下步骤:
- 在亚马逊云科技账单和成本管理控制台上,选择导航窗格中的成本分配标签。
- 在亚马逊云科技生成的成本分配标签下,选择
aws:elasticmapreduce:job-flow-id标签。 - 选择 "激活"。
标签最多可能需要 24 小时才能激活。欲了解更多信息,请参阅此处。
激活标签后,您可以使用亚马逊云科技 CUR 在 Amazon Athena 上执行以下查询,以查找 EMR 集群 ID 使用的计算资源与使用时间表的对比。更多详情,请参阅使用 Amazon Athena 查询成本和使用量报告。使用您的 CUR 表名称、EMR 集群 ID、所需时间戳和亚马逊云科技账户 ID 更新以下查询,然后在 Athena 上运行查询:
例如,前面的查询筛选了给定账户和 EMR 集群在 6 个月内每小时的实例使用量,以生成下图。您可以以 CSV 格式导出结果并分析数据。现在,您可以直观地显示工作负载的基线和突发量,您可以定义 EMR 集群的策略和配置。
创建 ODCR 以保留基准容量
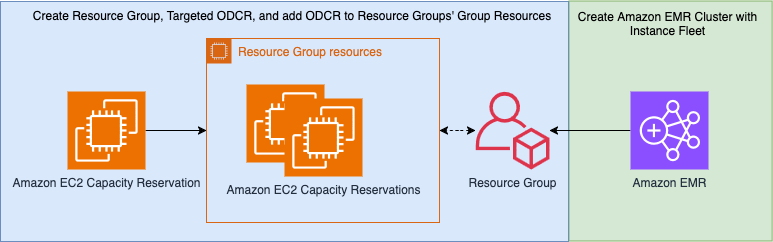
ODCR 可以是开放的,也可以是有针对性的:
- 使用开放的 ODCR,新实例和具有匹配属性(例如操作系统或实例类型)的现有实例将首先使用容量预留属性运行。
- 对于目标 ODCR,实例必须与 ODCR 规范的属性相匹配,而 ODCR 是专门针对启动的。如果您有多个并发 EMR 集群消耗 EC2 实例共享按需池中的容量,则推荐使用此方法。大于目标 ODCR 数量的 EMR 集群将退回到同一可用区内的按需实例。
在此示例中,我们在 us-east-1a 可用区使用具有 EMR 实例队列的目标 ODCR。下图说明了工作流程。
完成以下步骤:
- 使用创建容量预留亚马逊云科技 CLI 命令创建 ODCR 并记下输出中的
CapacityReservationArn值:
我们得到以下输出:
您可以使用 Amazon CloudWatch 监控 ODCR 的使用情况,并针对未使用容量触发警报。有关更多详细信息,请参阅使用 CloudWatch 指标监控容量预留使用情况。
- 创建一个名为的资源组
EMRSparkSteadyStateGroup并记下输出中的GroupArn值:
我们得到以下输出:
- 使用以下代码将容量预留关联到资源组。您可以将多个容量预留关联到一个资源组。
- 作为有效管理和清理的优秀实践,请
Purpose=EMR-Spark-Steady-State为新创建的 ODCR 和资源组创建标签。
使用 ODCR 实现 Amazon EMR
完成以下步骤,创建标有特定目标 ODCR 的 EMR 集群:
- 在使用容量预留之前,向 EMR 服务角色添加所需的权限。有了这些权限,您可以使用组名称的特定亚马逊资源名称 (ARN) 锁定资源,该资源将使用以下代码创建:
- 将 EMR 集群配置为在实例队列中使用 ODCR。我们使用
CapacityReservationOptions参数来配置 EMR 集群,如以下示例所示:
以下分步细分说明了在确定目标容量预留优先顺序时,Amazon EMR 的决策过程,从核心节点预置到任务节点分配:
- 集群配置启动:
- 用户选择替代最低价格分配策略。
- 用户在启动请求中指定目标容量预留。
- 核心节点配置:
- Amazon EMR 会评估所有具有定向容量预留的 EC2 实例容量池,并选择价格最低且容量足以容纳所有请求的核心节点的容量池。
- 如果任何具有定向预留的池都没有足够的容量,Amazon EMR 将重新评估所有指定的 EC2 实例容量池,并选择价格最低且具有足够容量供核心节点使用的池。可用的开放容量预留将自动应用。
- 可用区域选择:
- 获取核心容量后,Amazon EMR 会锁定集群的可用区域。
- 主节点和任务节点配置:
- Amazon EMR 会评估该可用区内主队列和任务队列的 EC2 实例容量池。首先,Amazon EMR 会评估请求中指定的目标 ODCR 的所有矿池,默认按最低价格排序。
- 根据有序列表,Amazon EMR 会从每个实例池未使用的目标 ODCR 中启动尽可能多的容量,直到请求得到满足。
- 如果未使用的目标 ODCR 尚未满足请求,Amazon EMR 会继续默认按最低价格顺序向按需池启动剩余容量。
有关分配策略的更多详情,请参阅舰队等分配策略或针对目标 ODCR 的 Amazon EMR 支持。
棘手的工作负载
尖峰工作负载是由处理需求的不可预测且通常是显著的波动所定义的,这些波动是由诸如不频繁但资源密集型的定期批处理任务等因素触发的。例如,地理信息系统实时处理来自数百万用户的位置数据,以提供最新的交通信息、计算路线和建议兴趣点。用户位置数据不断生成,但是在高峰时段或特殊事件期间,数据量可能会急剧增加,如下图所示。此图表按小时显示已用资源(Amazon EC2)的数量;从集群扩展到等待任务时的 1 到节点的峰值不等。
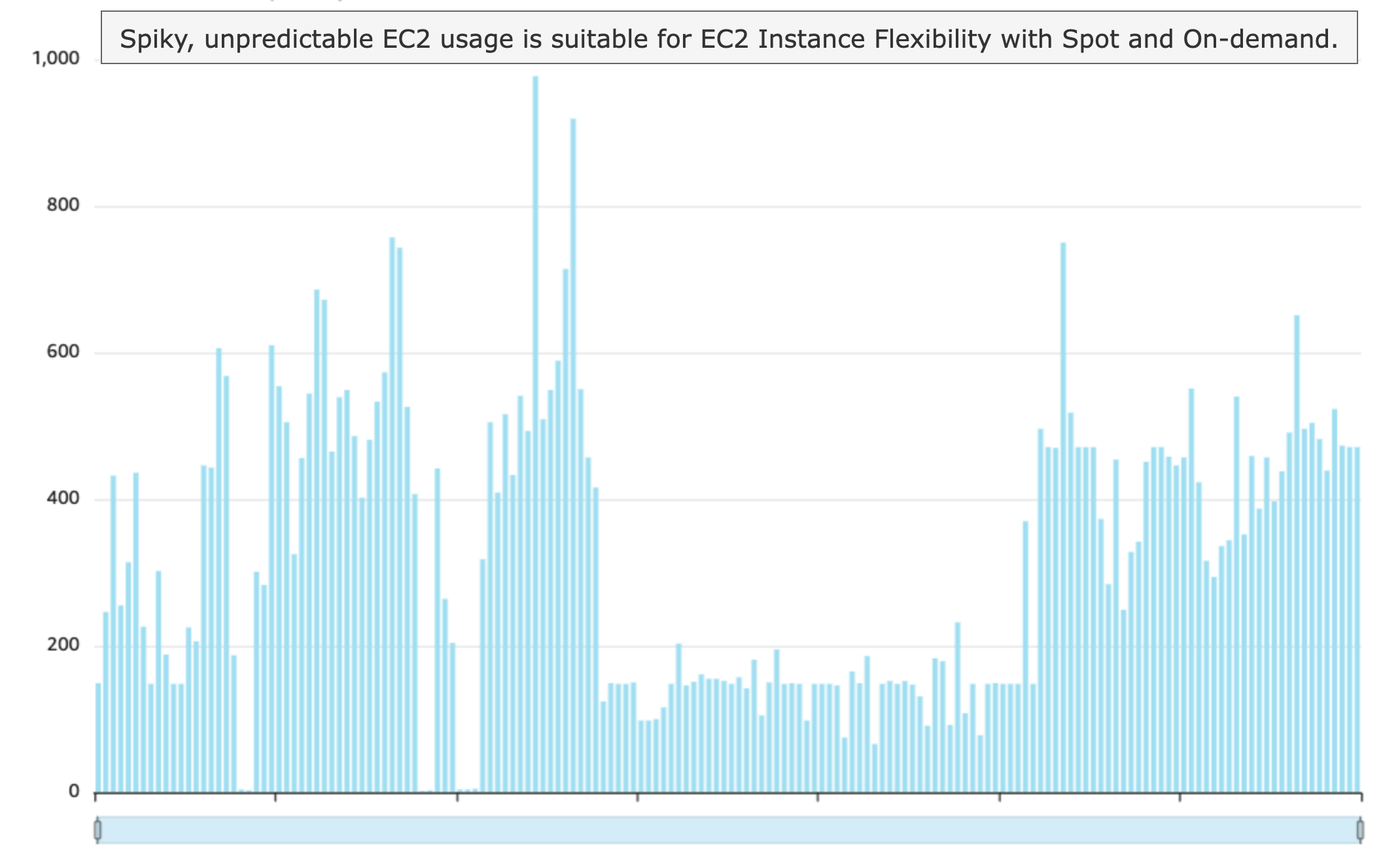
如果您正在运行高峰工作负载,但实例类型、系列和可用区域的灵活性有限,则当可用容量无法满足集群的扩展要求时,您可能会遇到 ICE 错误。为了解决这个问题,我们探索了一组创建 EMR 集群的优秀实践,以最大限度地提高可用性和平衡性价比。尽管高峰工作负载给资源管理带来了独特的挑战,但配置 EMR 实例队列提供了强大的解决方案。通过使用不同的实例类型、优先级分配策略、可用区灵活性和托管扩展,组织可以创建强大、经济实惠的基础设施,能够处理不可预测的工作负载模式。此配置具有以下优点:
- 提高可用性 — 通过多样化实例类型和使用多个可用区,集群缓解了容量不足的问题
- 节省成本 — 分配策略可降低成本,同时最大限度地减少中断
- 应对尖峰工作负载的弹性 — 优先生成实例可在不同的需求下实现无缝扩展
- 优化性能 — 托管扩展可动态调整资源以有效满足工作负载需求
通过优先分配策略引入 EC2 实例灵活性和实例队列
Amazon EMR 通过实例队列部署支持灵活的实例。实例队列为您提供有关实例配置的更多选择和情报。现在,您可以使用亚马逊云科技 CLI 或 Amazon CloudFormation 提供最多 30 种实例类型以及相应的加权容量和竞价出价(包括竞价区块)的列表。在创建集群时,Amazon EMR 将自动为这些实例类型预置按需和竞价容量。这可以使快速获得和维护集群所需的容量变得更加简单、更具成本效益。2024 年 8 月,Amazon EMR 推出了优先分配策略,通过实例队列增强实例灵活性。此功能允许您为实例类型指定优先级,从而使 Amazon EMR 能够首先为优先级最高的实例分配容量。该策略有助于节省成本并缩短启动集群所需的时间,即使在容量有限的情况下也是如此。更多详情,请参阅 Amazon EMR 支持 EC2 实例的优先分配策略和容量优化优先分配策略。为了最大限度地提高高峰工作负载的成本效益和可用性,将新一代实例的性价比优势与上一代实例的更广泛可用性相结合。对于延迟要求严格的工作负载,调整实例大小以保持稳定的性能。这种方法利用了两代实例的优势,提供了灵活性和可靠性,降低了容量限制的可能性。对于按需节点,选择优先分配策略,因此集群会首先尝试使用新一代实例。配置实例队列时,按照反映性价比和可用性折衷的优先顺序排列实例,例如:
- 主节点 — m8g.12xlarge > m8g.16xlarge > m7g.12xlarge > m7g.16xlarge > m7g.16xlarge
- 核心节点 — r8g.8xlarge > r8g.12xlarge > r7g.8xlarge > r6g.16xlarge > r5.16xlarge > r5.16xlarge
- 任务节点 — r8g.8xlarge > r8g.12xlarge > r7g.8xlarge > r6g.16xlarge > r5.16xlarge > r5.16xlarge
对于竞价型实例,请确保选择容量优化的优先分配策略以减少中断。以下 CloudFormation 模板片段为例:
选择具有 EMR 实例队列的子网
创建集群时,在虚拟私有云 (VPC) 内指定多个 EC2 子网,每个子网对应不同的可用区。Amazon EMR 通过在集群启动时采用子网筛选来提供多子网(可用区域)选项,并选择一个具有足够可用 IP 地址的子网来成功启动所有实例队列。如果 Amazon EMR 找不到具有足够的 IP 地址来启动整个集群的子网,它将优先考虑至少可以启动核心和主实例队列的子网。
使用托管扩展
托管扩展是 Amazon EMR 的另一项强大功能,它会根据工作负载需求自动调整集群中的实例数量。这可确保您的集群在需求旺盛的时段向上扩展以满足处理要求,并在空闲时向下扩展以节省成本。通过托管扩展,您可以设置最小和最大扩展限制,从而控制成本,同时受益于经过优化的高效集群性能。
以下工作流程说明了使用实例队列和托管扩展配置的 Amazon EMR。
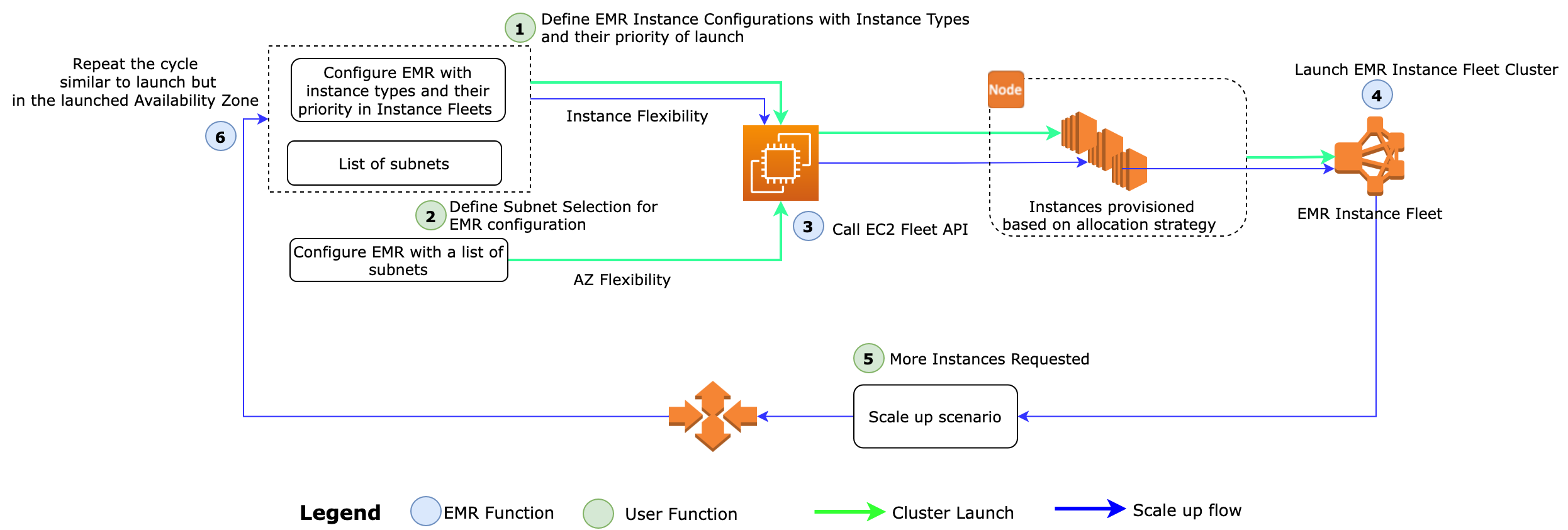
该工作流程包括以下步骤:
- 用户定义 EMR 实例配置和实例类型及其启动优先级。
- 用户为 Amazon EMR 配置选择子网以提供可用区域灵活性。
- Amazon EMR 调用 Amazon EC2 Fleet API 来根据分配策略预置实例。
- EMR 实例队列已启动。
- 重复该周期,在启动的可用区内扩展操作,以提供优化的性能和可扩展性。
结论
在这篇文章中,我们演示了如何通过分析 EMR 工作负载和实施针对您的工作负载模式量身定制的策略来优化容量。在实施上述任何策略时,请记住持续监控集群的性能,并根据您的特定工作负载模式和业务需求调整配置。使用正确的方法,可以将高峰工作负载的挑战转化为优化性能和节省成本的机会。
要有效管理既有基准需求又有意外峰值的工作负载,可以考虑在 Amazon EMR 中实施混合方法。使用 ODCR 实现稳定的基准容量,并使用 ODCR、按需和竞价型实例的战略组合配置实例队列,优先使用 ODCR。
用你自己的用例尝试这些策略,然后在评论中留下你的问题。
作者简介
 Deepmala Agarwal 担任亚马逊云科技数据专家解决方案架构师。她热衷于帮助客户在亚马逊云科技上构建可扩展、分布式和数据驱动的解决方案。工作之余,Deepmala 喜欢与家人共度时光、散步、听音乐、看电影和做饭!
Deepmala Agarwal 担任亚马逊云科技数据专家解决方案架构师。她热衷于帮助客户在亚马逊云科技上构建可扩展、分布式和数据驱动的解决方案。工作之余,Deepmala 喜欢与家人共度时光、散步、听音乐、看电影和做饭!
 Suba Palanisamy 是一名高级技术客户经理,帮助客户在亚马逊云科技上实现卓越运营。Suba 对数据和分析的所有事物都充满热情。她喜欢和家人一起旅行和玩棋盘游戏。
Suba Palanisamy 是一名高级技术客户经理,帮助客户在亚马逊云科技上实现卓越运营。Suba 对数据和分析的所有事物都充满热情。她喜欢和家人一起旅行和玩棋盘游戏。
 弗拉维奥·托雷斯是亚马逊云科技的首席技术客户经理。Flavio 帮助企业支持客户设计、部署和扩展弹性云应用程序。工作之余,他喜欢徒步旅行和烧烤。
弗拉维奥·托雷斯是亚马逊云科技的首席技术客户经理。Flavio 帮助企业支持客户设计、部署和扩展弹性云应用程序。工作之余,他喜欢徒步旅行和烧烤。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。