我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 SageMaker Studio Lab 分析和可视化多机位事件
美国国家橄榄球联盟(NFL)是美国最受欢迎的体育联盟之一,也是
使用多个摄像机视图的动机来自于仅用一个视图捕捉撞击事件时信息的限制。在只有一个视角的情况下,一些玩家可能会互相遮挡或被场上的其他物体阻挡。因此,添加更多视角可以让我们的机器学习系统识别出更多在单个视图中看不见的影响。为了展示我们的融合过程的结果以及团队如何使用可视化工具来帮助评估模型性能,我们开发了一个代码库来直观地叠加多视图检测结果。此过程通过删除在多个视图中检测到的重复冲击来帮助确定单个玩家所经历的实际冲击次数。
在这篇文章中,我们使用了
为 57583_00008
2 的视频进行重复数据删除和可视化。你可以下载
先决条件
该解决方案需要以下内容:
-
亚马逊 SageMaker Studio La b 账户 -
用于下载数据的 Kaggle 账户
开始使用 SageMaker Studio Lab 并安装所需的软件包
你可以从
-
访问
aws 样本 GitHub 存储库 。 -
在
自述文件部分中,选择 打开 Studio 实验 室 。

这会将你重定向到你的 SageMaker Studio 实验室环境。
- 选择您的 CPU 计算类型,然后选择 “ 开始运行时 ” 。
- 运行时启动后,选择 “ 复制到项目 ” ,这将打开一个包含 Jupyter Lab 环境的新窗口。
现在你已经准备好使用笔记本了!
-
打开
fuse_and_visualize_multiview_impacts.ipynb 然后按照笔记本中的说明进行操作。
笔记本中的第一个单元安装了必要的 Python 包,例如熊猫和 OpenCV:
%pip install pandas
%pip install opencv-contrib-python-headless导入所有必要的 Python 包并设置 pandas 选项以获得更好的可视化体验:
import os
import cv2
import pandas as pd
import numpy as np
pd.set_option('mode.chained_assignment', None)我们使用熊猫来摄取和解析带有注释的头盔边框和冲击力的 CSV 文件。我们主要使用 NumPy 来操作数组和矩阵。我们使用 OpenCV 在 Python 中读取、写入和操作图像数据。
通过融合两个视图的结果来准备数据
为了将这两个视角融合在一起,我们以 Kaggle 竞赛
中的 train_labels.csv
为例,因为它包含来自终点区域和副线的真实影响。以下函数获取输入数据集并输出一个融合的数据框,该数据框已对输入数据集中的所有剧本进行重复数据消除:
def prep_data(df):
df['game_play'] = df['gameKey'].astype('str') + '_' + df['playID'].astype('str').str.zfill(6)
return df
def dedup_view(df, windows):
# define view
df = df.sort_values(by='frame')
view_columns = ['frame', 'left', 'width', 'top', 'height', 'video']
common_columns = ['game_play', 'label', 'view', 'impactType']
label_cleaned = df[view_columns + common_columns]
# rename columns
sideline_column_rename = {col: 'Sideline_' + col for col in view_columns}
endzone_column_rename = {col: 'Endzone_' + col for col in view_columns}
sideline_columns = list(sideline_column_rename.values())
# create two dataframes, one for sideline, one for endzone
label_endzone = label_cleaned.query('view == "Endzone"')
label_endzone.rename(columns=endzone_column_rename, inplace=True)
label_sideline = label_cleaned.query('view == "Sideline"')
label_sideline.rename(columns=sideline_column_rename, inplace=True)
# prepare sideline labels
label_sideline['is_dup'] = False
for columns in sideline_columns:
label_endzone[columns] = np.nan
label_endzone['is_dup'] = False
# iterrate endzone rows to find matches and dedup
for index, row in label_endzone.iterrows():
player = row['label']
frame = row['Endzone_frame']
impact_type = row['impactType']
sideline_row = label_sideline[(label_sideline['label'] == player) &
((label_sideline['Sideline_frame'] >= frame - windows // 2) &
(label_sideline['Sideline_frame'] <= frame + windows // 2 + 1)) &
(label_sideline['is_dup'] == False) &
(label_sideline['impactType'] == impact_type)]
if len(sideline_row) > 0:
sideline_index = sideline_row.index[0]
label_sideline['is_dup'].loc[sideline_index] = True
for col in sideline_columns:
label_endzone[col].loc[index] = sideline_row.iloc[0][col]
label_endzone['is_dup'].loc[index] = True
# calculate overlap perc
not_dup_sideline = label_sideline[label_sideline['is_dup'] == False]
final_output = pd.concat([not_dup_sideline, label_endzone])
return final_output
def fuse_df(raw_df, windows):
outputs = []
all_game_play = raw_df['game_play'].unique()
for game_play in all_game_play:
df = raw_df.query('game_play ==@game_play')
output = dedup_view(df, windows)
outputs.append(output)
output_df = pd.concat(outputs)
output_df['gameKey'] = output_df['game_play'].apply(lambda x: x.split('_')[0]).map(int)
output_df['playID'] = output_df['game_play'].apply(lambda x: x.split('_')[1]).map(int)
return output_df
要运行该函数,我们运行以下代码块来提供
train_labels.csv
数据的位置,然后进行数据准备以添加额外的列并仅提取影响行。
运行该函数后,我们将输出保存到名为 fused_df 的数据帧变量中。
# read the annotated impact data from train_labels.csv
ground_truth = pd.read_csv('train_labels.csv')
# prepare game_play column using pipe(prep_data) function in pandas then filter the dataframe for just rows with impacts
ground_truth = ground_truth.pipe(prep_data).query('impact == 1')
# loop over all the unique game_plays and deduplicate the impact results from sideline and endzone
fused_df = fuse_df(ground_truth, windows=30)
以下屏幕截图显示了基本真相。

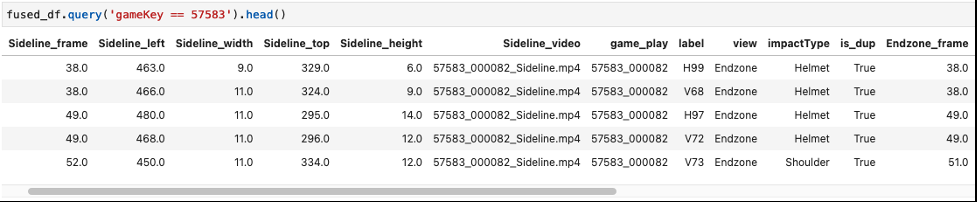
以下屏幕截图显示了融合后的数据框示例。
图形和视频代码
融合冲击结果后,我们使用生成的 f
used_df
将结果叠加 到我们的端区和副线视频上,并将这两个视图合并在一起。为此,我们使用以下函数,所需的输入是端区视频、副线视频、 f
used_df
数据帧的路径以及新生成的视频的最终输出路径。本节中使用的功能在 SageMaker Studio Lab 中使用的笔记本的降价部分中进行了描述。
def get_video_and_metadata(vid_path):
vid = cv2.VideoCapture(vid_path)
total_frame_number = vid.get(cv2.CAP_PROP_FRAME_COUNT)
width = int(vid.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = vid.get(cv2.CAP_PROP_FPS)
return vid, total_frame_number, width, height, fps
def overlay_impacts(frame, fused_df, game_key, play_id, frame_cnt, h1):
# look for duplicates
duplicates = fused_df.query(f"gameKey == {int(game_key)} and \
playID == {int(play_id)} and \
is_dup == True and \
Sideline_frame == @frame_cnt")
frame_has_impact = False
if len(duplicates) > 0:
for duplicate in duplicates.itertuples(index=False):
if frame_cnt == duplicate.Sideline_frame:
frame_has_impact = True
if frame_has_impact:
cv2.rectangle(frame, #frame to be edited
(int(duplicate.Sideline_left), int(duplicate.Sideline_top)), #(x,y) of top left corner
(int(duplicate.Sideline_left) + int(duplicate.Sideline_width), int(duplicate.Sideline_top) + int(duplicate.Sideline_height)), #(x,y) of bottom right corner
(0,0,255), #RED boxes
thickness=3)
cv2.rectangle(frame, #frame to be edited
(int(duplicate.Endzone_left), int(duplicate.Endzone_top)+ h1), #(x,y) of top left corner
(int(duplicate.Endzone_left) + int(duplicate.Endzone_width), int(duplicate.Endzone_top) + int(duplicate.Endzone_height) + h1), #(x,y) of bottom right corner
(0,0,255), #RED boxes
thickness=3)
cv2.line(frame, #frame to be edited
(int(duplicate.Sideline_left), int(duplicate.Sideline_top)), #(x,y) of point 1 in a line
(int(duplicate.Endzone_left), int(duplicate.Endzone_top) + h1), #(x,y) of point 2 in a line
(255, 255, 255), # WHITE lines
thickness=4)
else:
# if no duplicates, look for sideline then endzone and add to the view
sl_impacts = fused_df.query(f"gameKey == {int(game_key)} and \
playID == {int(play_id)} and \
is_dup == False and \
view == 'Sideline' and \
Sideline_frame == @frame_cnt")
if len(sl_impacts) > 0:
for impact in sl_impacts.itertuples(index=False):
if frame_cnt == impact.Sideline_frame:
frame_has_impact = True
if frame_has_impact:
cv2.rectangle(frame, #frame to be edited
(int(impact.Sideline_left), int(impact.Sideline_top)), #(x,y) of top left corner
(int(impact.Sideline_left) + int(impact.Sideline_width), int(impact.Sideline_top) + int(impact.Sideline_height)), #(x,y) of bottom right corner
(0, 255, 255), #YELLOW BOXES
thickness=3)
ez_impacts = fused_df.query(f"gameKey == {int(game_key)} and \
playID == {int(play_id)} and \
is_dup == False and \
view == 'Endzone' and \
Endzone_frame == @frame_cnt")
if len(ez_impacts) > 0:
for impact in ez_impacts.itertuples(index=False):
if frame_cnt == impact.Endzone_frame:
frame_has_impact = True
if frame_has_impact:
cv2.rectangle(frame, #frame to be edited
(int(impact.Endzone_left), int(impact.Endzone_top)+ h1), #(x,y) of top left corner
(int(impact.Endzone_left) + int(impact.Endzone_width), int(impact.Endzone_top) + int(impact.Endzone_height) + h1 ), #(x,y) of bottom right corner
(0, 255, 255), #YELLOW BOXES
thickness=3)
return frame, frame_has_impact
def generate_impact_video(ez_vid_path:str,
sl_vid_path:str,
fused_df:pd.DataFrame,
output_path:str,
freeze_impacts=True):
#define video codec to be used for
VIDEO_CODEC = "MP4V"
# parse game_key and play_id information from the name of the files
game_key = os.path.basename(ez_vid_path).split('_')[0] # parse game_key
play_id = os.path.basename(ez_vid_path).split('_')[1] # parse play_id
# get metadata such as total frame number, width, height and frames per second (FPS) from endzone (ez) and sideline (sl) videos
ez_vid, ez_total_frame_number, ez_width, ez_height, ez_fps = get_video_and_metadata(ez_vid_path)
sl_vid, sl_total_frame_number, sl_width, sl_height, sl_fps = get_video_and_metadata(sl_vid_path)
# define a video writer for the output video
output_video = cv2.VideoWriter(output_path, #output file name
cv2.VideoWriter_fourcc(*VIDEO_CODEC), #Video codec
ez_fps, #frames per second in the output video
(ez_width, ez_height+sl_height)) # frame size with stacking video vertically
# find shorter video and use the total frame number from the shorter video for the output video
total_frame_number = int(min(ez_total_frame_number, sl_total_frame_number))
# iterate through each frame from endzone and sideline
for frame_cnt in range(total_frame_number):
frame_has_impact = False
frame_near_impact = False
# reading frames from both endzone and sideline
ez_ret, ez_frame = ez_vid.read()
sl_ret, sl_frame = sl_vid.read()
# creating strings to be added to the output frames
img_name = f"Game key: {game_key}, Play ID: {play_id}, Frame: {frame_cnt}"
video_frame = f'{game_key}_{play_id}_{frame_cnt}'
if ez_ret == True and sl_ret == True:
h, w, c = ez_frame.shape
h1,w1,c1 = sl_frame.shape
if h != h1 or w != w1: # resize images if they're different
ez_frame = cv2.resize(ez_frame,(w1,h1))
frame = np.concatenate((sl_frame, ez_frame), axis=0) # stack the frames vertically
frame, frame_has_impact = overlay_impacts(frame, fused_df, game_key, play_id, frame_cnt, h1)
cv2.putText(frame, #image frame to be modified
img_name, #string to be inserted
(30, 30), #(x,y) location of the string
cv2.FONT_HERSHEY_SIMPLEX, #font
1, #scale
(255, 255, 255), #WHITE letters
thickness=2)
cv2.putText(frame, #image frame to be modified
str(frame_cnt), #frame count string to be inserted
(w1-75, h1-20), #(x,y) location of the string in the top view
cv2.FONT_HERSHEY_SIMPLEX, #font
1, #scale
(255, 255, 255), # WHITE letters
thickness=2)
cv2.putText(frame, #image frame to be modified
str(frame_cnt), #frame count string to be inserted
(w1-75, h1+h-20), #(x,y) location of the string in the bottom view
cv2.FONT_HERSHEY_SIMPLEX, #font
1, #scale
(255, 255, 255), # WHITE letters
thickness=2)
output_video.write(frame)
# Freeze for 60 frames on impacts
if frame_has_impact and freeze_impacts:
for _ in range(60):
output_video.write(frame)
else:
break
frame_cnt += 1
output_video.release()
return
要运行这些函数,我们可以提供如下代码所示的输入,它会生成一个名为
output.mp4
的视频 :
generate_impact_video('57583_000082_Endzone.mp4',
'57583_000082_Sideline.mp4',
fused_df,
'output.mp4')这将生成一个视频,如以下示例所示,其中红色边界框是在端点区域和边线视图中都存在的冲击力,而黄色边界框是在终点区域或副线的仅一个视图中发现的冲击。
结论
在这篇文章中,我们展示了NFL、Biocore和亚马逊云科技 ProServe团队如何共同努力,通过融合来自多个视图的结果来改善影响检测。这使团队能够调试和可视化模型的定性表现。这个过程可以很容易地扩展到三个或更多视图;在我们的项目中,我们使用了多达七种不同的视图。由于视野障碍,仅从一个视角观看视频来检测头盔碰撞可能很困难,但是从多个视角检测碰撞并将结果融合在一起,可以提高模型性能。
有关NFL球员健康与安全的更多信息,请访问
作者简介
 Chris Boomhower
是 亚马逊云科技 专业服务的机器学习工程师。Chris 在开发各个行业的有监督和无监督机器学习解决方案方面拥有 6 年以上的经验。如今,他的大部分时间都花在帮助体育、医疗保健和农业行业的客户设计和构建可扩展的端到端机器学习解决方案上。
Chris Boomhower
是 亚马逊云科技 专业服务的机器学习工程师。Chris 在开发各个行业的有监督和无监督机器学习解决方案方面拥有 6 年以上的经验。如今,他的大部分时间都花在帮助体育、医疗保健和农业行业的客户设计和构建可扩展的端到端机器学习解决方案上。
 Ben Fenker
是 亚马逊云科技 专业服务的高级数据科学家,曾帮助从体育到医疗保健再到制造业等行业的客户构建和部署机器学习解决方案。他拥有德克萨斯农工大学的物理学博士学位和6年的行业经验。Ben 喜欢棒球、阅读和抚养孩子。
Ben Fenker
是 亚马逊云科技 专业服务的高级数据科学家,曾帮助从体育到医疗保健再到制造业等行业的客户构建和部署机器学习解决方案。他拥有德克萨斯农工大学的物理学博士学位和6年的行业经验。Ben 喜欢棒球、阅读和抚养孩子。
 山姆·哈德尔斯顿
是Biocore LLC的首席数据科学家,他是美国国家橄榄球联盟数字运动员项目的技术主管。Biocore是一支由世界一流的工程师组成的团队,总部位于弗吉尼亚州夏洛茨维尔,为致力于了解和减少伤害的客户提供研究、测试、生物力学专业知识、建模和其他工程服务。
山姆·哈德尔斯顿
是Biocore LLC的首席数据科学家,他是美国国家橄榄球联盟数字运动员项目的技术主管。Biocore是一支由世界一流的工程师组成的团队,总部位于弗吉尼亚州夏洛茨维尔,为致力于了解和减少伤害的客户提供研究、测试、生物力学专业知识、建模和其他工程服务。
 贾维斯·李
是 亚马逊云科技 专业服务的高级数据科学家。他在 亚马逊云科技 工作了五年多,与客户合作解决机器学习和计算机视觉问题。工作之余,他喜欢骑自行车。
贾维斯·李
是 亚马逊云科技 专业服务的高级数据科学家。他在 亚马逊云科技 工作了五年多,与客户合作解决机器学习和计算机视觉问题。工作之余,他喜欢骑自行车。
 泰勒·穆伦巴赫
是 亚马逊云科技 专业服务的 ML 全球实践主管。他负责推动专业服务机器学习的战略方向,并确保客户通过采用机器学习技术实现变革性的业务成就。
泰勒·穆伦巴赫
是 亚马逊云科技 专业服务的 ML 全球实践主管。他负责推动专业服务机器学习的战略方向,并确保客户通过采用机器学习技术实现变革性的业务成就。
 Kevin Song
是 亚马逊云科技 专业服务的数据科学家。他拥有生物物理学博士学位,在构建计算机视觉和机器学习解决方案方面拥有超过5年的行业经验。
Kevin Song
是 亚马逊云科技 专业服务的数据科学家。他拥有生物物理学博士学位,在构建计算机视觉和机器学习解决方案方面拥有超过5年的行业经验。
 Betty Zh
ang 是一位数据科学家,在数据和技术领域拥有 10 年的经验。她热衷于构建创新的机器学习解决方案,推动公司的转型变革。在业余时间,她喜欢旅行、阅读和学习新技术。
Betty Zh
ang 是一位数据科学家,在数据和技术领域拥有 10 年的经验。她热衷于构建创新的机器学习解决方案,推动公司的转型变革。在业余时间,她喜欢旅行、阅读和学习新技术。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。