我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
用于降维的亚马逊 SageMaker Data Wrangler
在机器学习 (ML) 领域,数据集的质量对模型的可预测性至关重要。尽管通常数据越多越好,但由于维度问题,具有大量特征的大型数据集有时会导致模型性能不理想。分析师可以花费大量时间转换数据以提高模型性能。此外,大型数据集更昂贵,训练时间更长。如果时间是一个限制,则模型性能可能会因此受到限制。
降维技术可以帮助缩小数据的大小,同时保留其信息,从而缩短训练时间、降低成本,并可能提高模型的性能。
今天,我们很高兴将机器学习领域常用的新转换技术添加到 Data Wrangler 预建转换列表中:使用主成分分析进行降维。借助这项新功能,您只需在 Data Wrangler 控制台上单击几下,即可将数据集中的大量维度减少到可用于常用机器学习算法的维度。这可以毫不费力地显著提高模型性能。
在这篇文章中,我们概述了这项新功能,并展示了如何在数据转换中使用它。我们将展示如何在大型稀疏数据集上使用降维。
主成分分析概述
主成分分析 (PCA) 是一种方法,通过该方法,可以在具有许多数值特征的数据集中将特征的维度转换为具有较少特征的数据集,同时仍尽可能保留原始数据集中的信息。这是通过找到一 组名为组件 的新特征来实现的 ,这些特征是相互不相关的原始特征的组合。数据集中的多个特征通常对最终结果的影响较小,并可能增加机器学习模型的处理时间。人类可能很难理解和解决此类高维度问题。像 PCA 这样的降维技术可以帮助我们解决这个问题。
解决方案概述
在这篇文章中,我们将介绍如何在
要了解有关新的降维功能的更多信息,请参阅在数据集中
先决条件
这篇文章假设你已经设置了一个
要开始使用 Data Wrangler 的新功能,请在
执行快速模型分析
我们在本文中使用的数据集包含 60,000 个训练示例和标签。每行包含 785 个值:第一个值是标签(介于 0—9 之间的数字),其余 784 个值是像素值(介于 0—255 之间的数字)。首先,我们对原始数据进行快速模型分析,以获得性能指标,并将其与PCA转换后的模型指标进行比较以进行评估。完成以下步骤:
-
下载
MNIST 数据集训练数据集 。 -
从.zip 文件中提取数据并上传到
亚马逊简单存储服务 (Amazon S3) 存储 桶中。 -
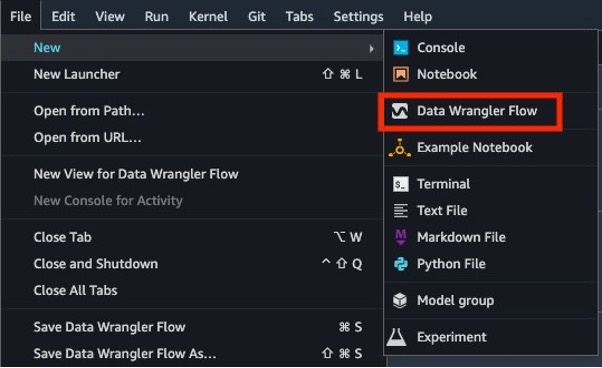
在 Studio 中,选择 “
新
建” 和
“ 数据管理者流
” 以创建新的数据管理者流。
-
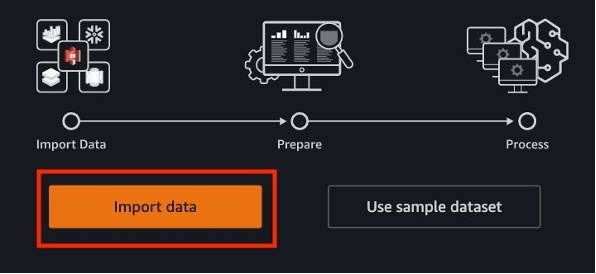
选择
导入数据
从 Amazon S3 加载数据。
-
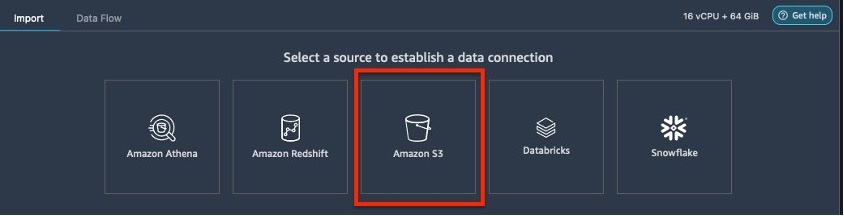
选择
Amazon S3
作为您的数据源。
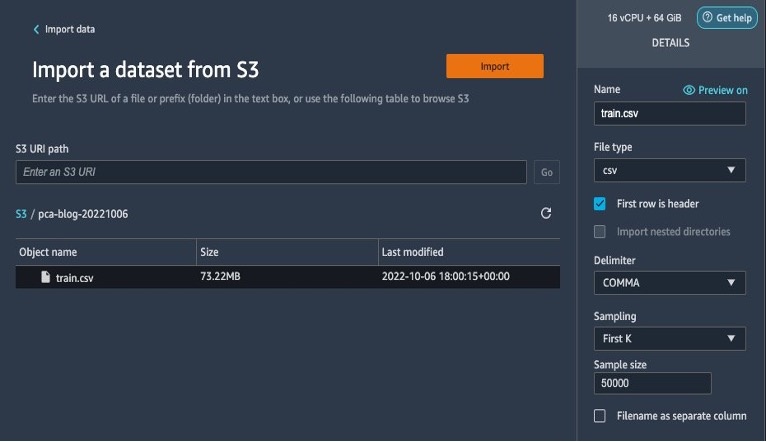
- 选择上传到您的 S3 存储桶的数据集。
-
保留默认设置并选择 “
导入
” 。
导入数据后,Data Wrangler 会自动验证数据集并根据其采样检测所有列的数据类型。在 MNIST 数据集中,由于所有列都很长,因此我们将此步骤保持原样,然后返回数据流。
-
在 “
数据
类型 ” 页面顶部选择 “ 数据
流
” 以返回主数据流。
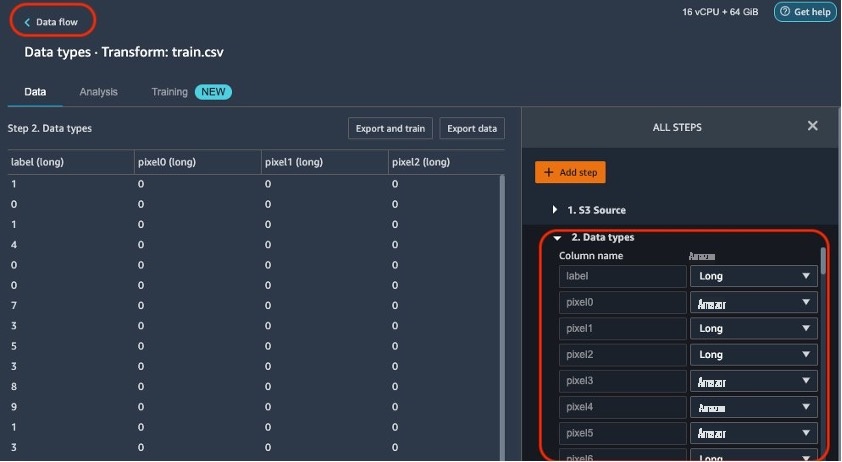
流量编辑器现在显示两个区块,显示数据是从源导入的,并且数据类型已识别。如果需要,您还可以编辑数据类型。
在确认数据质量可以接受之后,我们返回数据流并使用数据管理者的《数据质量和见解报告》。此报告对导入的数据集进行分析,并提供有关缺失值、异常值、目标泄漏、不平衡数据和快速模型分析的信息。有关详细信息,请参阅
在本分析中,我们仅关注数据质量报告的快速模型部分。
-
选择 “
数据类型
” 旁边的加号 ,然后选择 “
添加分析
” 。
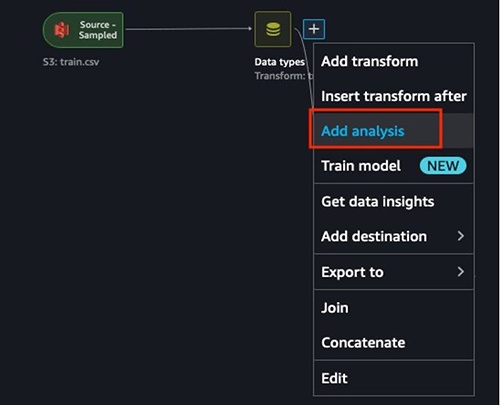
- 对于 分析类型 ,选择 数据质量和见解报告 。
- 对于 “ 目标” 列 ,选择标签。
- 对于 问题类型 ,选择 分类 (此步骤是可选的)。
-
选择 “
创建
” 。
在这篇文章中,我们使用数据质量和洞察报告来展示如何使用PCA来保持模型性能。我们建议您使用基于深度学习的方法来提高性能。
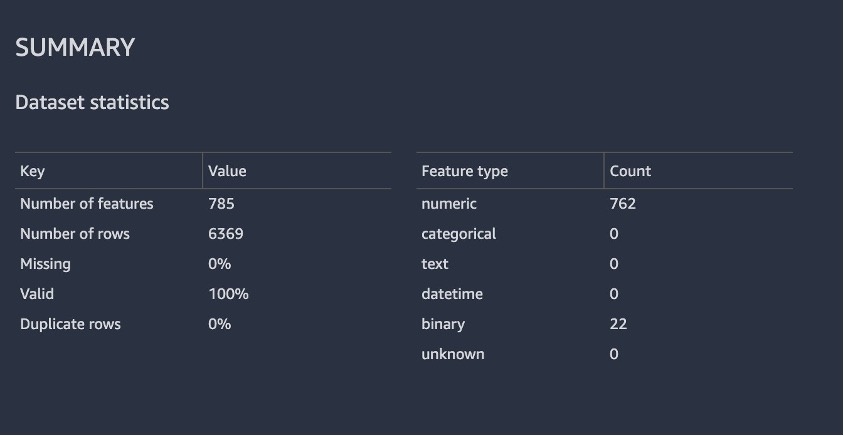
以下屏幕截图显示了报表中数据集的摘要。幸运的是,我们没有任何缺失值。生成报告所花费的时间取决于数据集的大小、要素的数量以及 Data Wrangler 使用的实例大小。
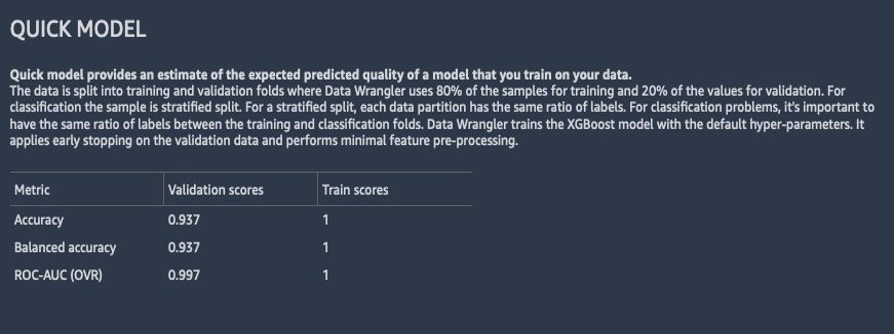
以下屏幕截图显示了模型在原始数据集上的表现。在这里,我们注意到该模型利用784个特征的精度为93.7%。
使用 Data Wrangler 降维变换
现在,让我们使用 Data Wrangler 降维变换来减少该数据集中的要素数量。
-
在数据流页面上,选择
数据类型
旁边的加号 ,然后选择
添加转换
。

-
选择 “
添加步骤
” 。
-
选择 “
降维”。
如果您没有看到列出的降维选项,则需要更新 Data Wrangler。有关说明,请参阅
-
配置 PCA 中的关键变量:
- 对于 Trans form ,选择要使用的降维技术。在这篇文章中,我们选择 主成分分析 。
- 对于 输入列 ,选择要包含在 PCA 分析中的列。在此示例中,我们选择了除目标列标签之外的所有功能(您也可以使用 “全 选” 功能选择所有功能并取消选择不需要的功能)。这些列必须是数字数据类型。
- 对于 主成分 数 ,指定目标维度的数量。
- 对于 方差阈值百分 比 ,指定要按主成分解释的数据中的变异百分比。默认值为 95;在这篇文章中,我们使用 80。
- 选择 居 中 ,在缩放之前使用均值将数据居中。
-
选择 “
缩
放” 使用单位标准差缩放数据。
PCA 更加重视具有高方差的变量。因此,如果不缩放维度,我们将得到不一致的结果。例如,一个变量的值可能在 50—100 的范围内,而另一个变量的值可能在 5—10 之间。在这种情况下,PCA 将增加第一个变量的权重。在应用 PCA 之前,可以通过缩放数据集来解决此类问题。
在 “
- 输出格式 ” 中 ,指定是否要将组件输出到单独的列或向量中。对于这篇文章,我们选择 列 。
- 对于 “ 输出” 列 ,为 PCA 生成的列名输入前缀。在这篇文章中,我们输入 PCA80_。
-
选择 “
预览
” 预览数据,然后选择 “
更新
” 。
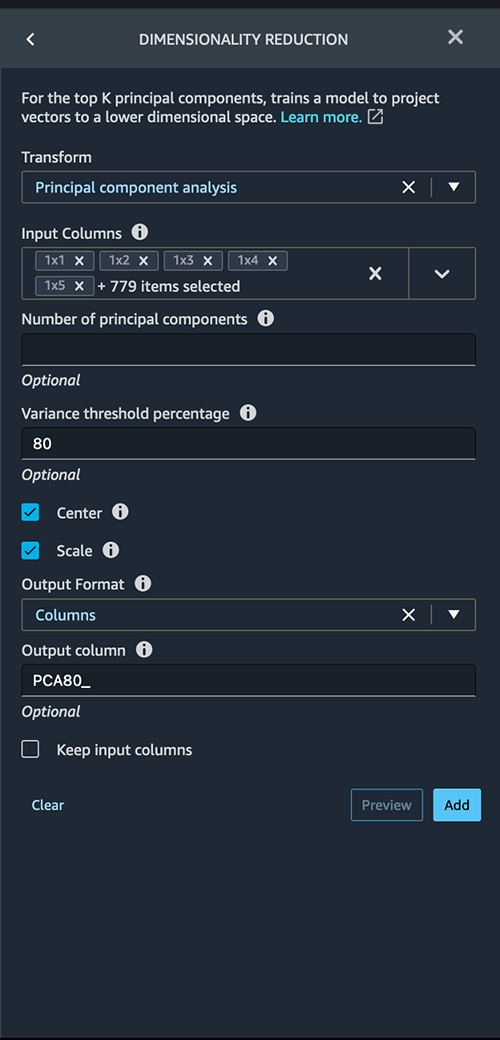
应用 PCA 后,列数将从 784 减少到 115,这意味着特征数量减少了 85%。
现在,我们可以使用转换后的数据集生成另一份数据质量和见解报告,如以下屏幕截图所示,以观察模型性能。
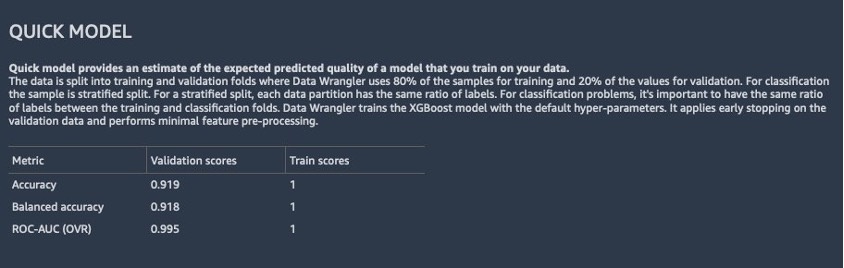
在第二份分析中,我们可以看到,与第一份快速模型报告相比,模型性能有所提高,准确性提高到91.8%。PCA 将数据集中的特征数量减少了 85%,同时将模型精度保持在相似水平。
根据报告中的快速模型分析,模型性能为91.8%。使用 PCA,我们将列数减少了 85%,同时仍将模型精度保持在相似水平。为了获得更好的结果,你可以尝试深度学习模型,它可能会提供更好的性能。
我们发现使用
- 缩小 PCA 维度 — 25 分钟
- 不缩小 PCA 尺寸 — 45 分钟
将 PCA 投入运营
随着数据随着时间的推移而变化,通常需要将我们的参数重新训练为新的看不见的数据。Data Wrangler 通过使用重新拟合参数来提供这种功能。有关重新拟合训练参数的更多信息,请参阅
之前,我们将 PCA 应用于包含 50,000 行样本的 MNIST 数据集样本。因此,我们的流程文件包含一个模型,该模型已在此示例上进行了训练,并用于所有创建的作业,除非我们指定要重新学习这些参数。
要重新调整 MNIST 训练数据集上的模型参数,请完成以下步骤:
-
在 Amazon S3 中为我们的流程文件创建目的地,这样我们就可以创建数据管理器处理任务。
- 创建作业并选择 Refit 以学习新的训练参数。
训练过的参数 部分显示有 784 个参数。这是每列的一个参数,因为我们在 PCA 简化中排除了标签列。
请注意,如果我们在此步骤中不选择 Refit,则 将使用 在交互模式下学习到的经过训练的参数。
-
创建作业。
-
选择处理任务链接来监控任务并在 Amazon S3 上找到生成的流程文件的位置。
该流程文件包含在整个 MNIST 训练数据集上学习的模型。
- 将此文件加载到数据管理器中。
清理
要清理环境以免产生额外费用,请删除 Amazon S3 中的数据集和项目。此外,删除 Studio 中的数据流文件并关闭其运行的实例。有关详细信息,请参阅 “
结论
降维是从模型中移除不需要的变量的好方法。它可用于降低模型复杂性和数据中的噪声,从而缓解机器学习和深度学习模型中常见的过度拟合问题。在这篇博客中,我们演示了通过减少特征数量,我们仍然能够为模型实现相似或更高的精度。
有关使用 PCA 的更多信息,请参阅
作者简介

 阿比盖尔 是亚马
逊 SageMaker 的软件开发工程师。她热衷于帮助客户在 DataWrangler 中准备数据并构建分布式机器学习系统。在空闲时间,阿比盖尔喜欢旅行、远足、滑雪和烘烤。
阿比盖尔 是亚马
逊 SageMaker 的软件开发工程师。她热衷于帮助客户在 DataWrangler 中准备数据并构建分布式机器学习系统。在空闲时间,阿比盖尔喜欢旅行、远足、滑雪和烘烤。


*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。