我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Amazon S3 Tables 与 Amazon SageMaker Lakehouse 的集成现已正式推出
在 re:Invent 2024 上,我们推出了 Amazon S3 Tables,这是第一款内置支持 Apache Iceberg 的云对象存储,可简化表格数据的大规模存储,并推出了 Amazon SageMaker Lakehouse,通过统一、开放和安全的数据湖库来简化分析和人工智能。我们还预览了 S3 Tables 与亚马逊云科技分析服务的集成,您可以使用 Amazon Athena、Amazon Data Firehose、Amazon EMR、Amazon Glue、Amazon Redshift 和 Amazon QuickSight 流式传输、查询和可视化 S3 Tables 数据。
我们的客户希望简化其 Apache Iceberg 存储的管理和优化,这促成了 S3 Tables 的开发。他们同时努力使用 SageMaker Lakehouse 打破阻碍分析协作和洞察生成的数据孤岛。与 S3 Tables 和 SageMaker Lakehouse 配合使用时,除了与亚马逊云科技分析服务的内置集成外,它们还可以获得一个综合平台,统一对多个数据源的访问,从而支持分析和机器学习 (ML) 工作流程。
今天,我们宣布,Amazon S3 Tables 与 Amazon SageMaker Lakehouse 的集成正式上市,以提供跨各种分析引擎和工具的统一 S3 表格数据访问权限。你可以从 Amazon SageMaker Unified Studio 访问 SageMaker Lakehouse,这是一个集合了来自亚马逊云科技分析和人工智能/机器学习服务的功能和工具的单一数据和人工智能开发环境。所有集成到 SageMaker Lakehouse 的 S3 表格数据都可以从 SageMaker Unified Studio 和诸如 Amazon Athena、Amazon EMR、Amazon Redshift 和兼容 Apache Iceberg 的引擎(例如 Apache Spark 或 PyIceBerg)等引擎中查询。
通过这种集成,您可以简化安全分析工作流程的构建,在其中可以读取和写入 S3 Tables,并与 Amazon Redshift 数据仓库以及第三方和联合数据源(例如 Amazon DynamoDB 或 PostgreSQL)中的数据联接。
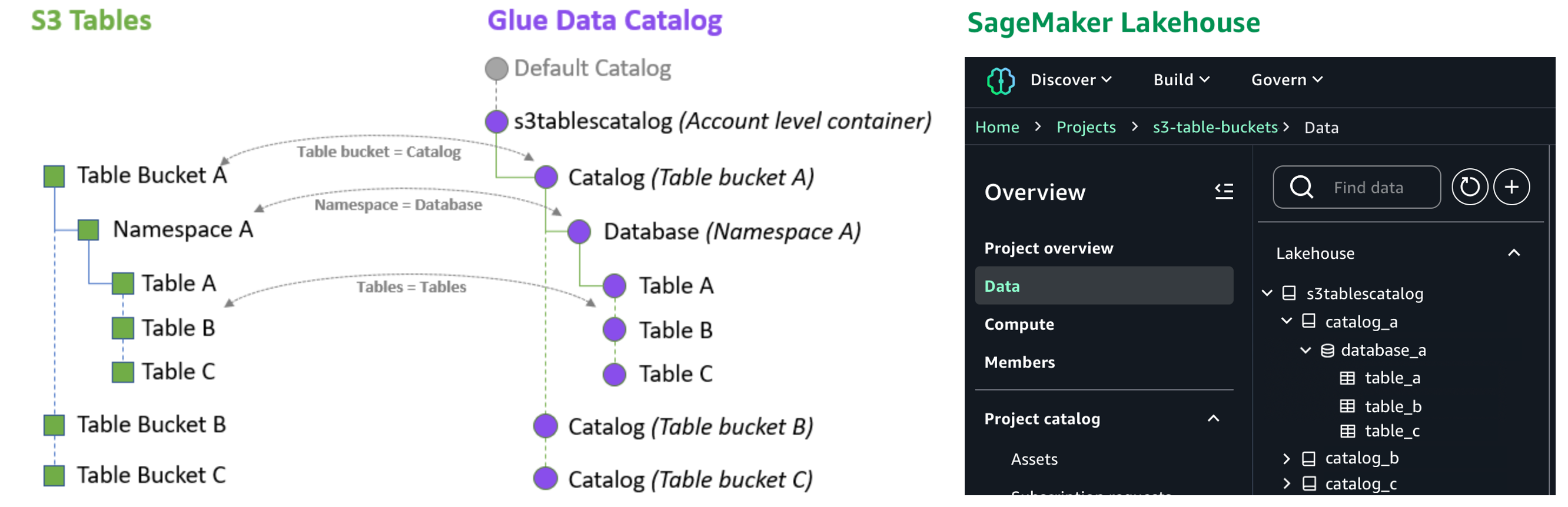
您还可以集中设置和管理 S3 Tables 中数据以及 SageMaker Lakehouse 中其他数据的精细访问权限,并将其一致地应用于所有分析和查询引擎。
S3 Tables 与 SageMaker Lakehouse 的集成正在运行
要开始使用,请前往 Amazon S3 控制台,从导航窗格中选择表存储桶,然后选择"启用集成"以从亚马逊云科技分析服务访问表存储桶。
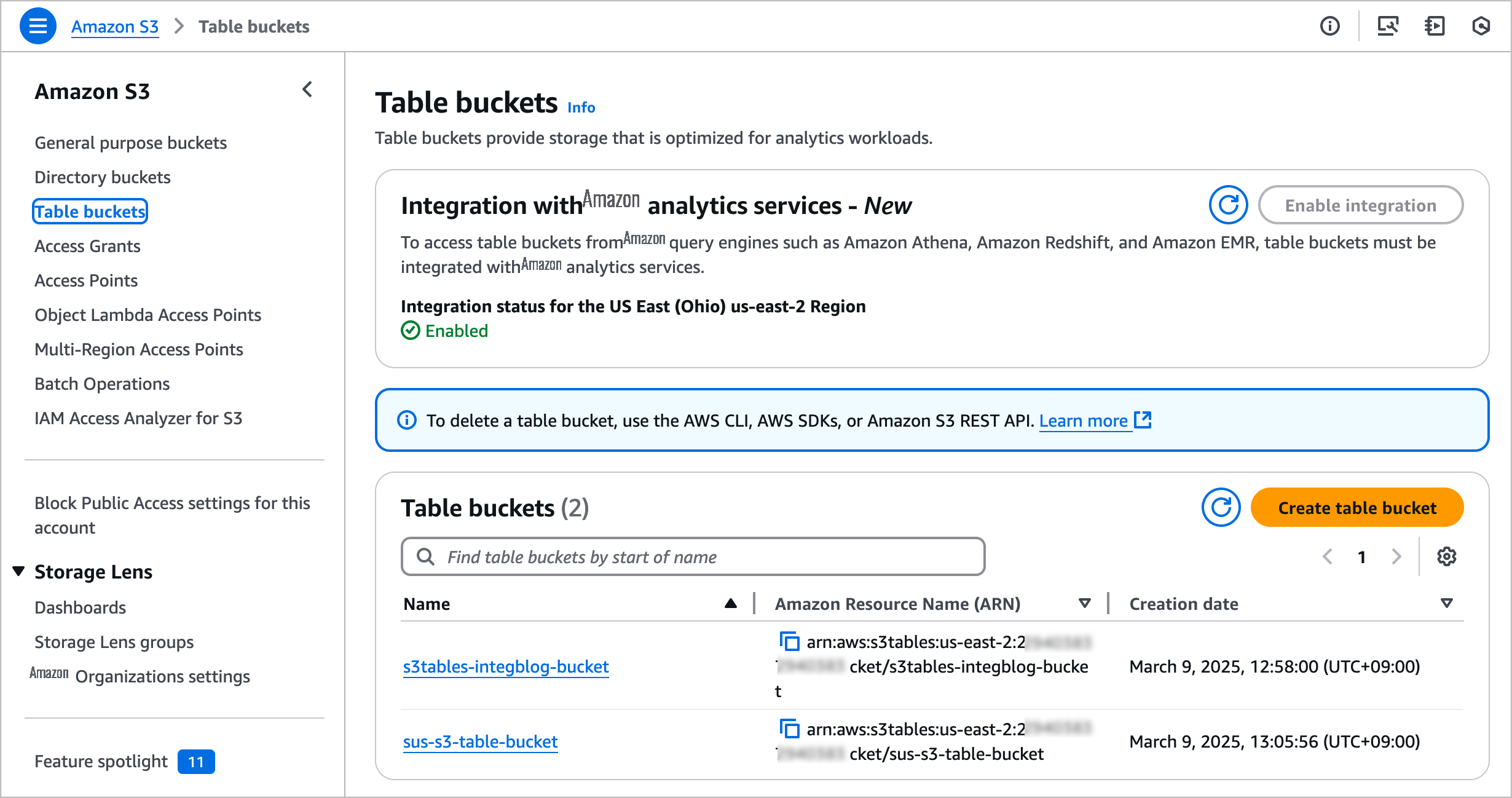
现在,你可以创建自己的表存储桶以与 SageMaker Lakehouse 集成。要了解更多信息,请访问亚马逊云科技文档中的 S3 Tables 入门。
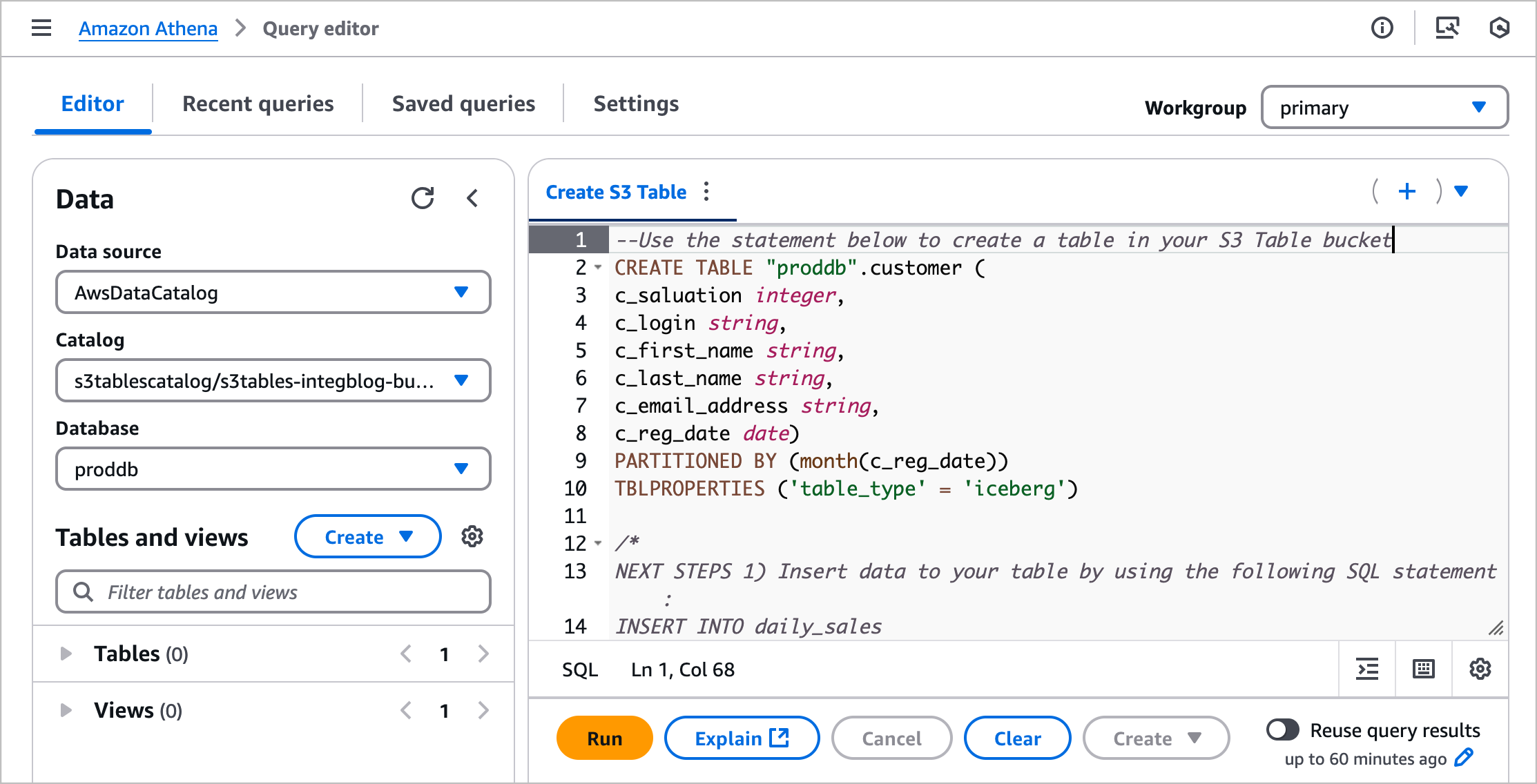
1. 在 Amazon S3 控制台中使用 Amazon Athena 创建表格
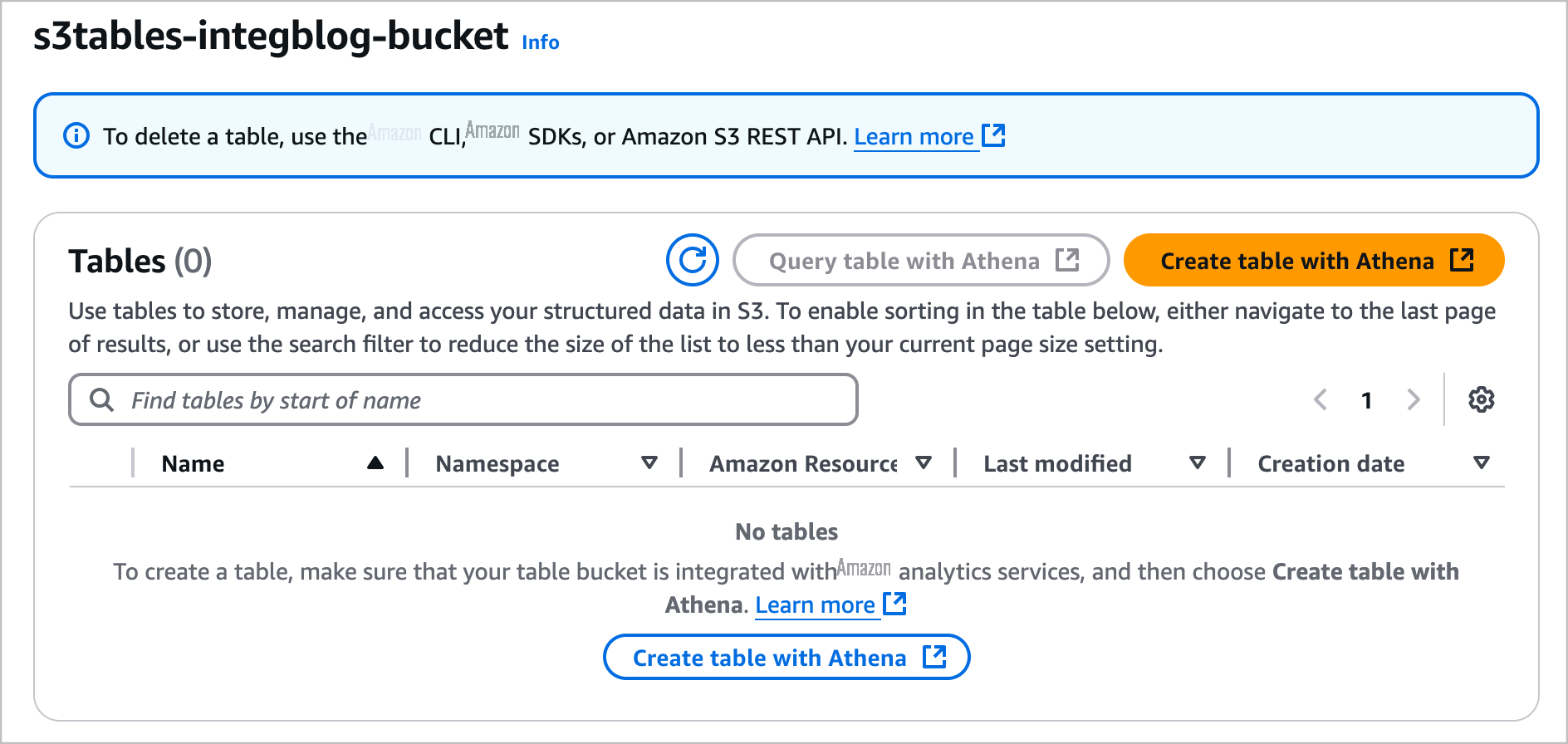
您只需几个步骤即可创建表,在其中填充数据,然后使用 Amazon Athena 直接从 Amazon S3 控制台进行查询。选择一个表格存储桶并选择"使用 Athena 创建表",或者您可以选择现有表并选择"使用 Athena 查询表"。
当你想使用 Athena 创建表时,你应该首先为你的表指定一个命名空间。S3 Tables 存储桶中的命名空间等同于 Amazon Glue 中的数据库,您可以在 Athena 查询中使用该表命名空间作为数据库。
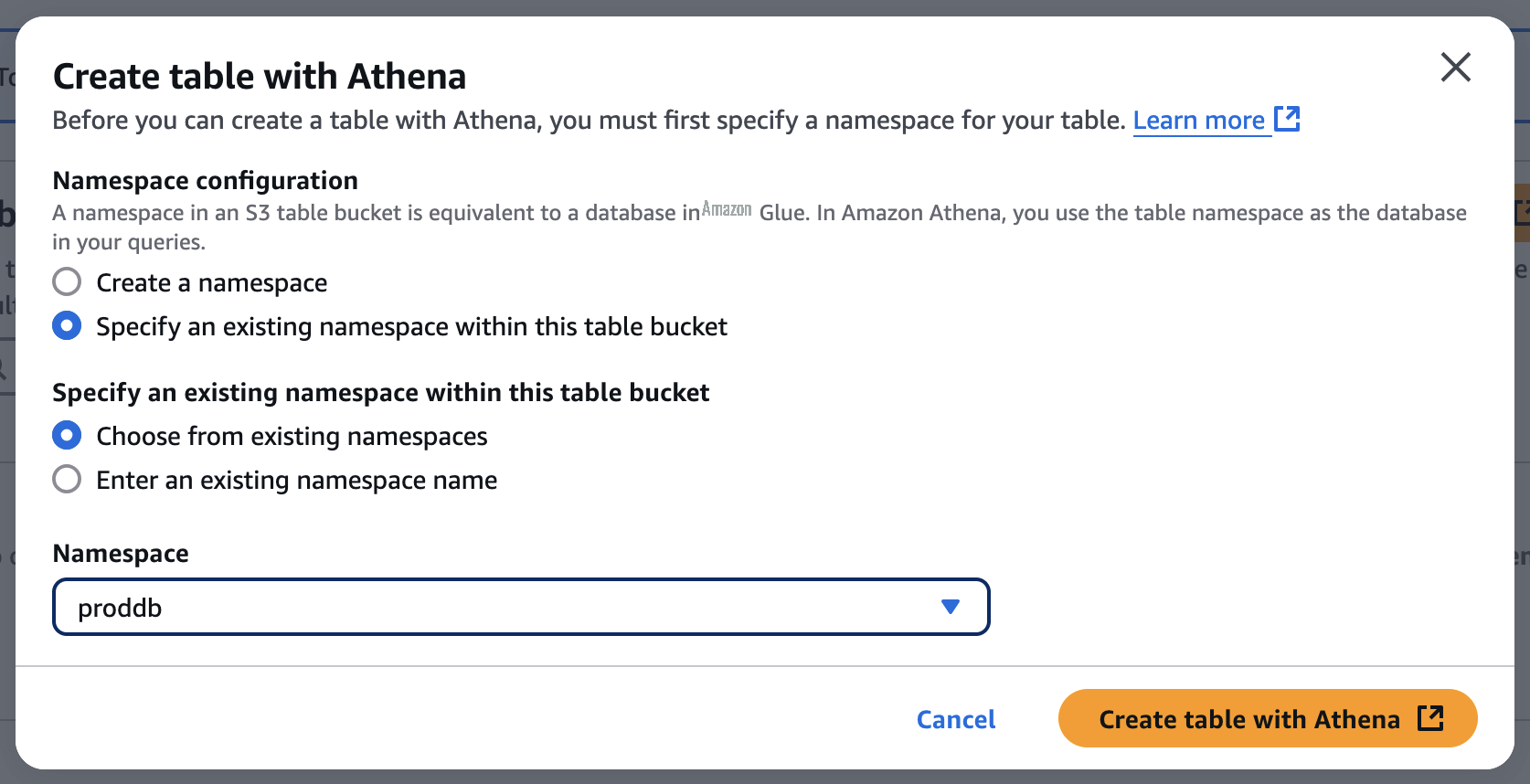
选择命名空间并选择"使用 Athena 创建表"。它进入 Athena 控制台中的查询编辑器。您可以在 S3 表存储桶中创建表或在表中查询数据。
2. 在 SageMaker Unified Studio 中使用 SageMaker Lakehouse 进行查询
现在,您可以直接从 SageMaker Unified Studio 访问 SageMaker Lakehouse 中的 S3 数据湖、Redshift 数据仓库、第三方和联合数据源中的统一数据。
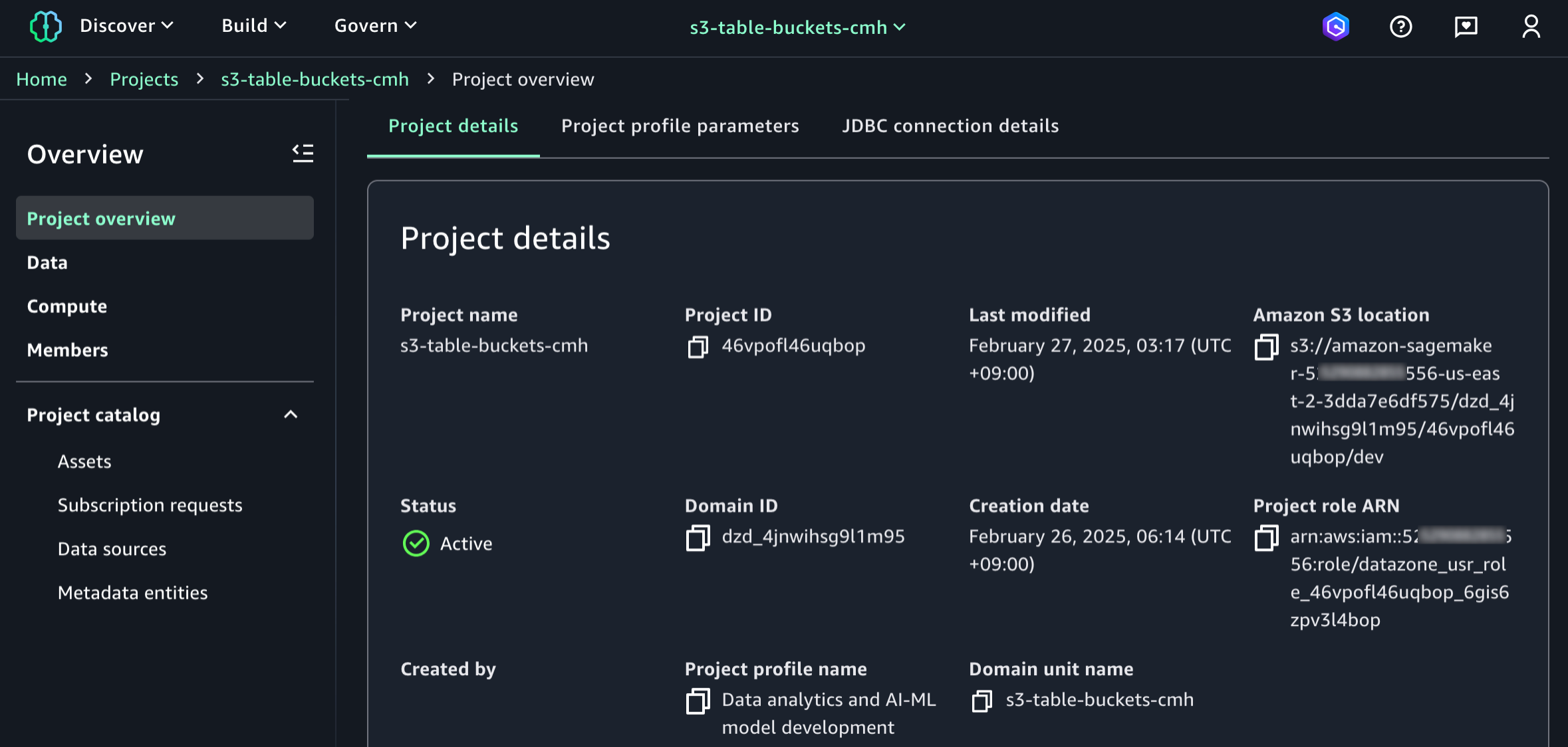
要开始使用,请前往 SageMaker 控制台,使用示例项目配置文件创建 SageMaker Unified Studio 域名和项目:数据分析和人工智能机器学习模型开发。要了解更多信息,请访问亚马逊云科技文档中的创建 Amazon SageMaker Unified Studio 域。
创建项目后,导航至项目概览并向下滚动至项目详情,记下项目角色亚马逊资源名称 (ARN)。
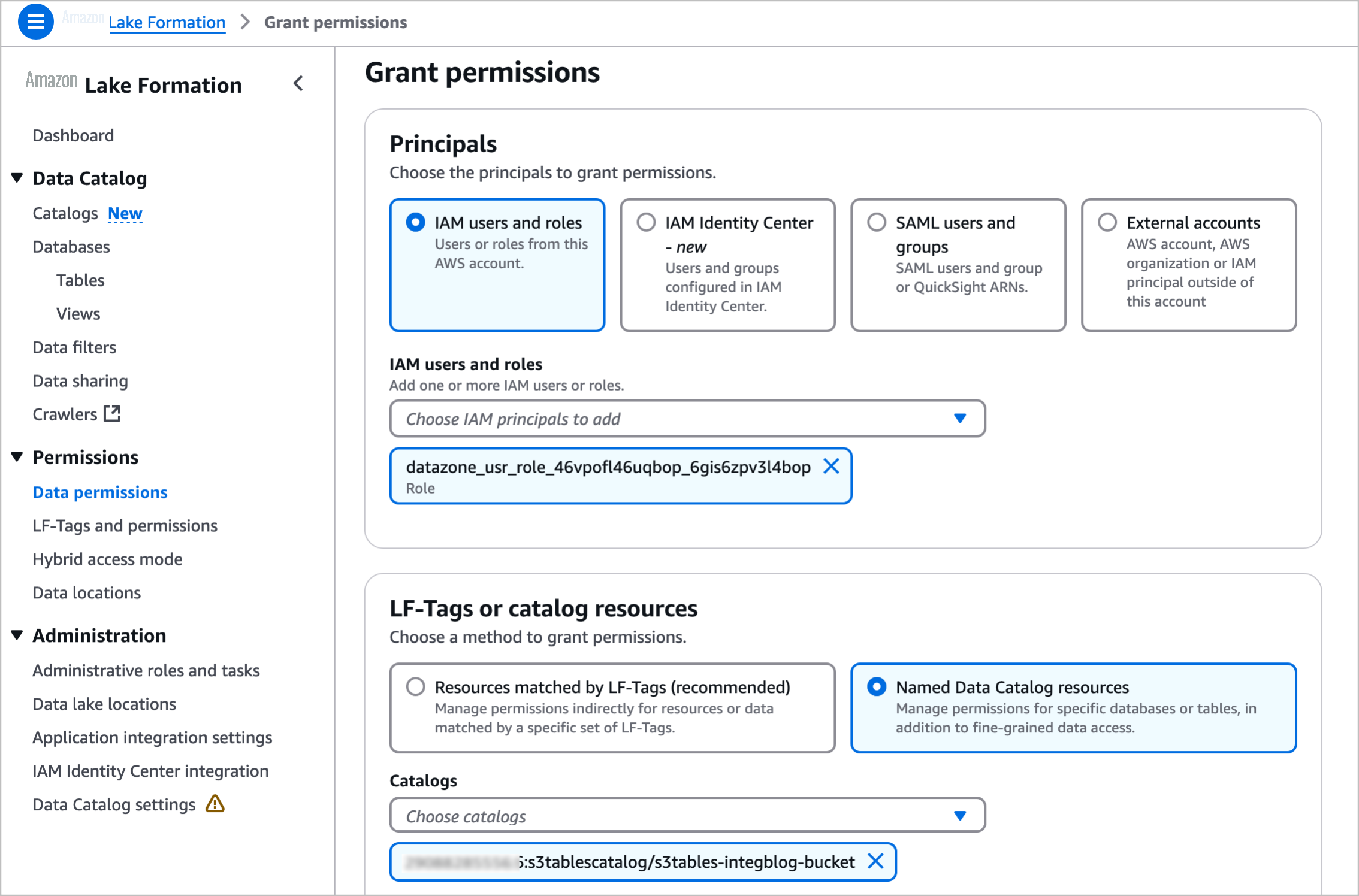
前往 Amazon Lake Formation 控制台,为 Amazon Identity and Access Management (IAM) 用户和角色授予权限。在"主体"部分中,选择上一段中<project role ARN>注明的内容。在 LF 标签或目录资源部分中选择命名数据目录资源,然后选择您为目录创建的表存储桶名称。要了解更多信息,请访问亚马逊云科技文档中的 Lake Formation 权限概述。
当你返回 SageMaker Unified Studio 时,你可以在项目页面左侧导航窗格的"数据"菜单中的 Lakehouse 下看到你的表格存储桶项目。选择"操作"时,您可以选择如何在 Amazon Athena、Amazon Redshift 或 JupyterLab Notebook 中查询表存储桶数据。
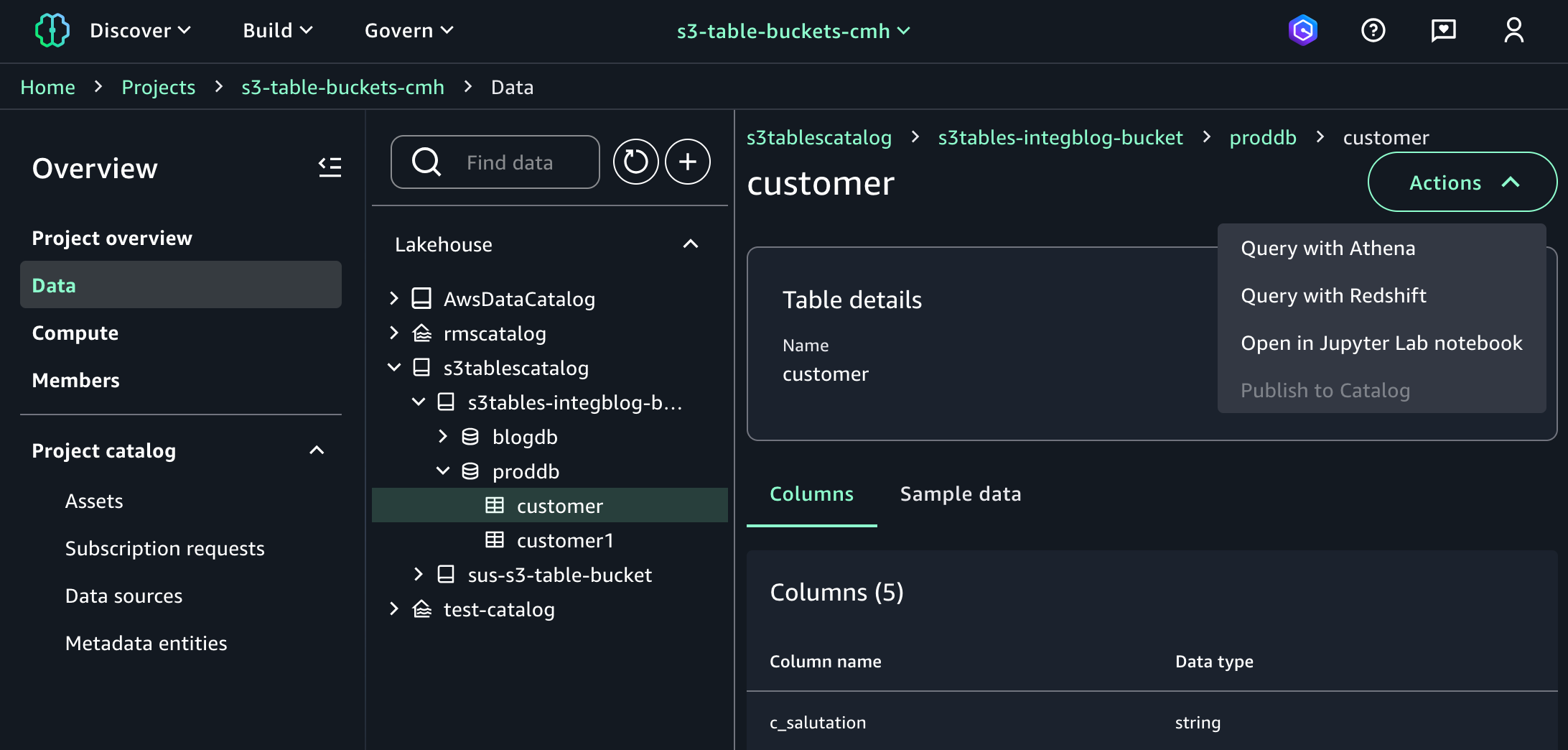
当您选择"使用 Athena 进行查询"时,它会自动进入查询编辑器,使用 Athena 对 S3 Tables 运行数据查询语言 (DQL) 和数据操作语言 (DML) 查询。
以下是使用 Athena 的示例查询:
select * from "s3tablecatalog/s3tables-integblog-bucket"."proddb"."customer" limit 10;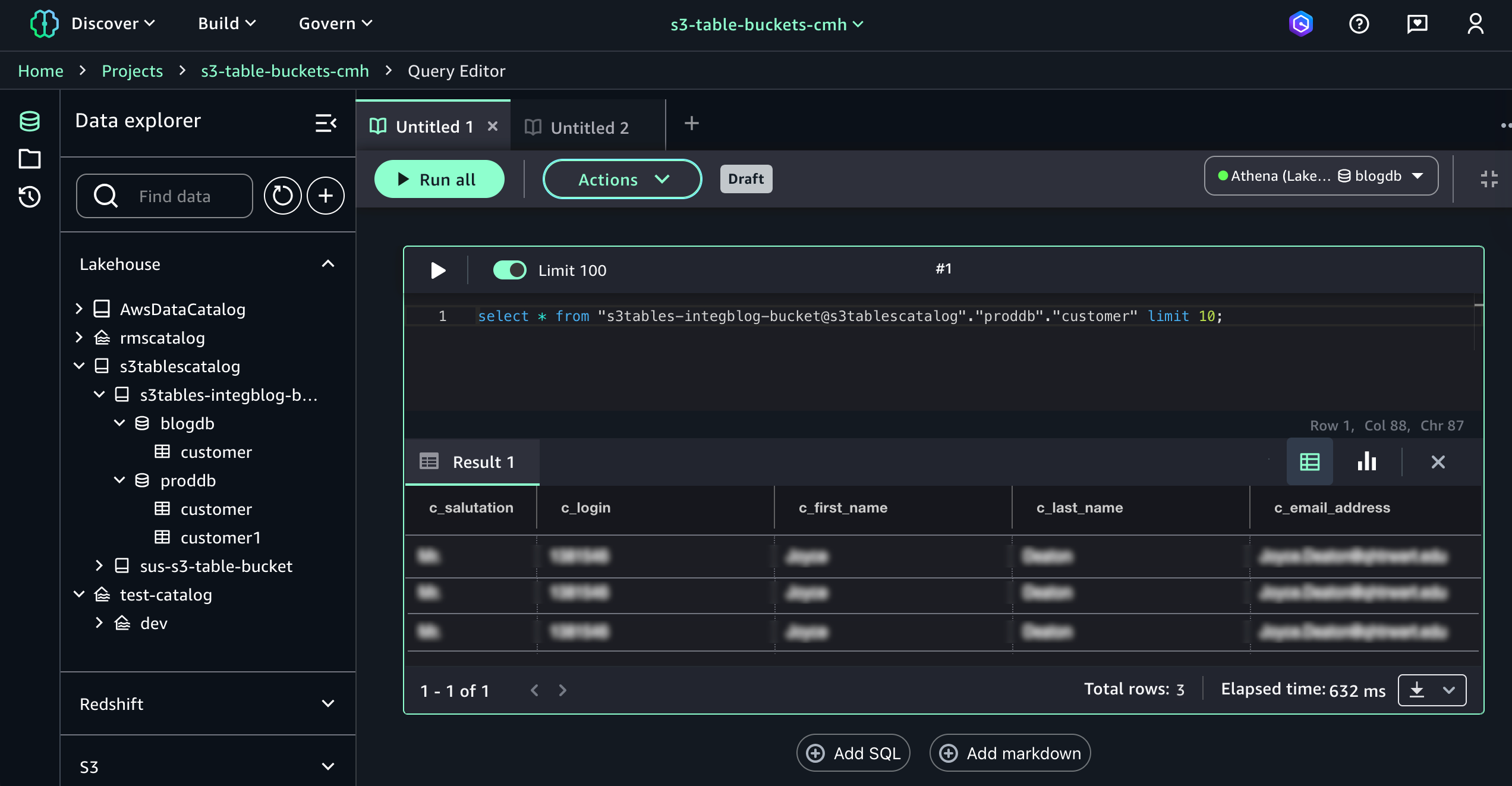
要使用 Amazon Redshift 进行查询,您应该设置 Amazon Redshift 无服务器计算资源以进行数据查询分析。然后选择"使用 Redshift 进行查询",然后在"查询编辑器"中运行 SQL。如果你想使用 JupyterLab Notebook,你应该在 Amazon EMR Serverless 中创建一个新的 JupyterLab 空间。
3. 将来自其他来源的数据与 S3 Tables 数据结合
使用 SageMaker Lakehouse 现已提供 S3 Tables 数据,您可以将其与来自数据仓库、在线事务处理 (OLTP) 来源(例如关系或非关系数据库)、Iceberg 表和其他第三方来源的数据结合起来,以获得更全面、更深入的见解。
例如,你可以添加与诸如 Amazon DocumentDB、Amazon DynamoDB、Amazon Redshift、PostgreSQL、MySQL、谷歌 BigQuery 或 Snowflake 等数据源的连接,并使用没有提取、转换和加载 (ETL) 脚本的 SQL 合并数据。
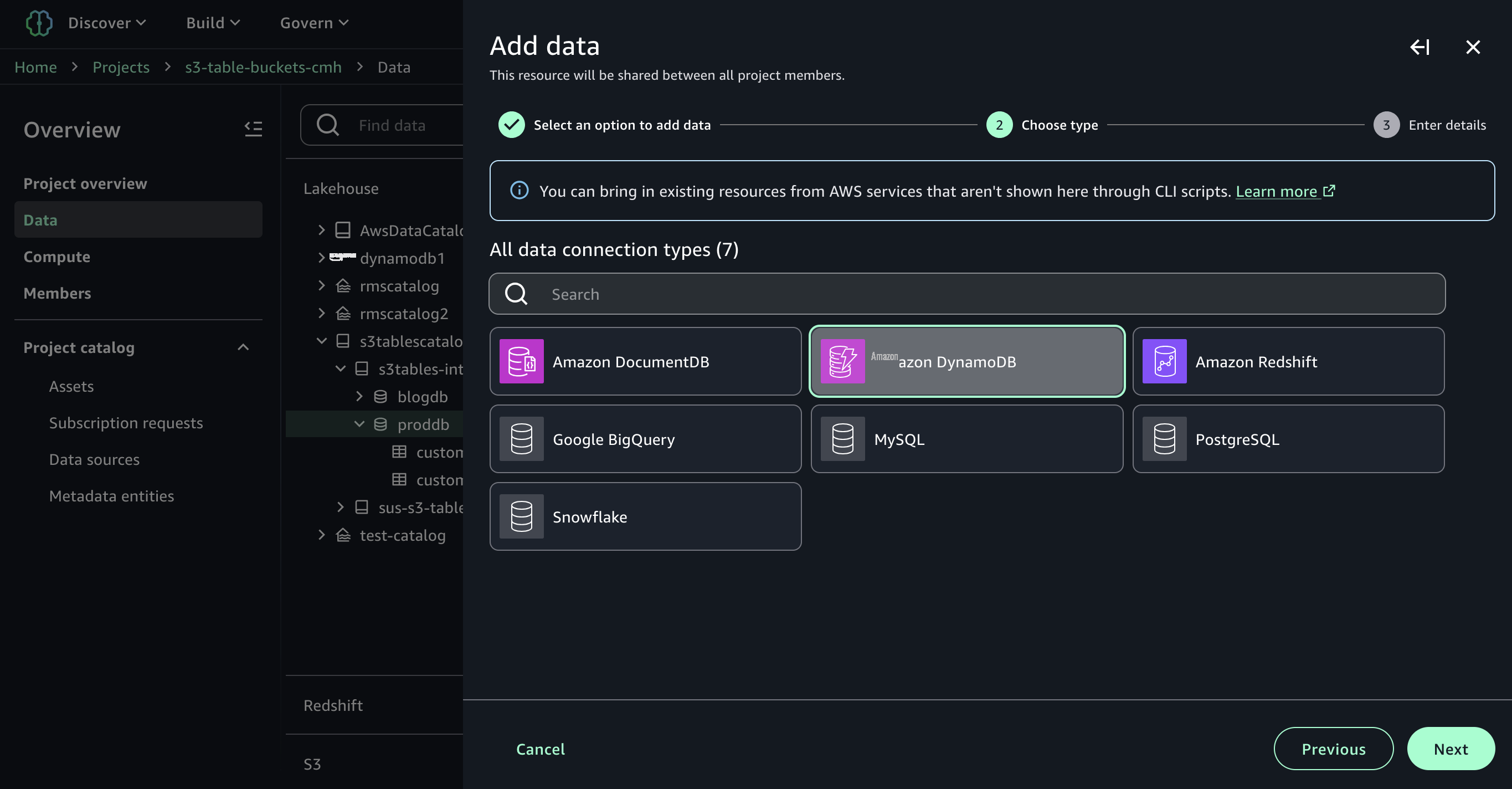
现在,您可以在查询编辑器中运行 SQL 查询,将 S3 Tables 中的数据与 DynamoDB 中的数据联接起来。
以下是在 Athena 和 DynamoDB 之间加入的示例查询:
select * from "s3tablescatalog/s3tables-integblog-bucket"."blogdb"."customer",
"dynamodb1"."default"."customer_ddb" where cust_id=pid limit 10;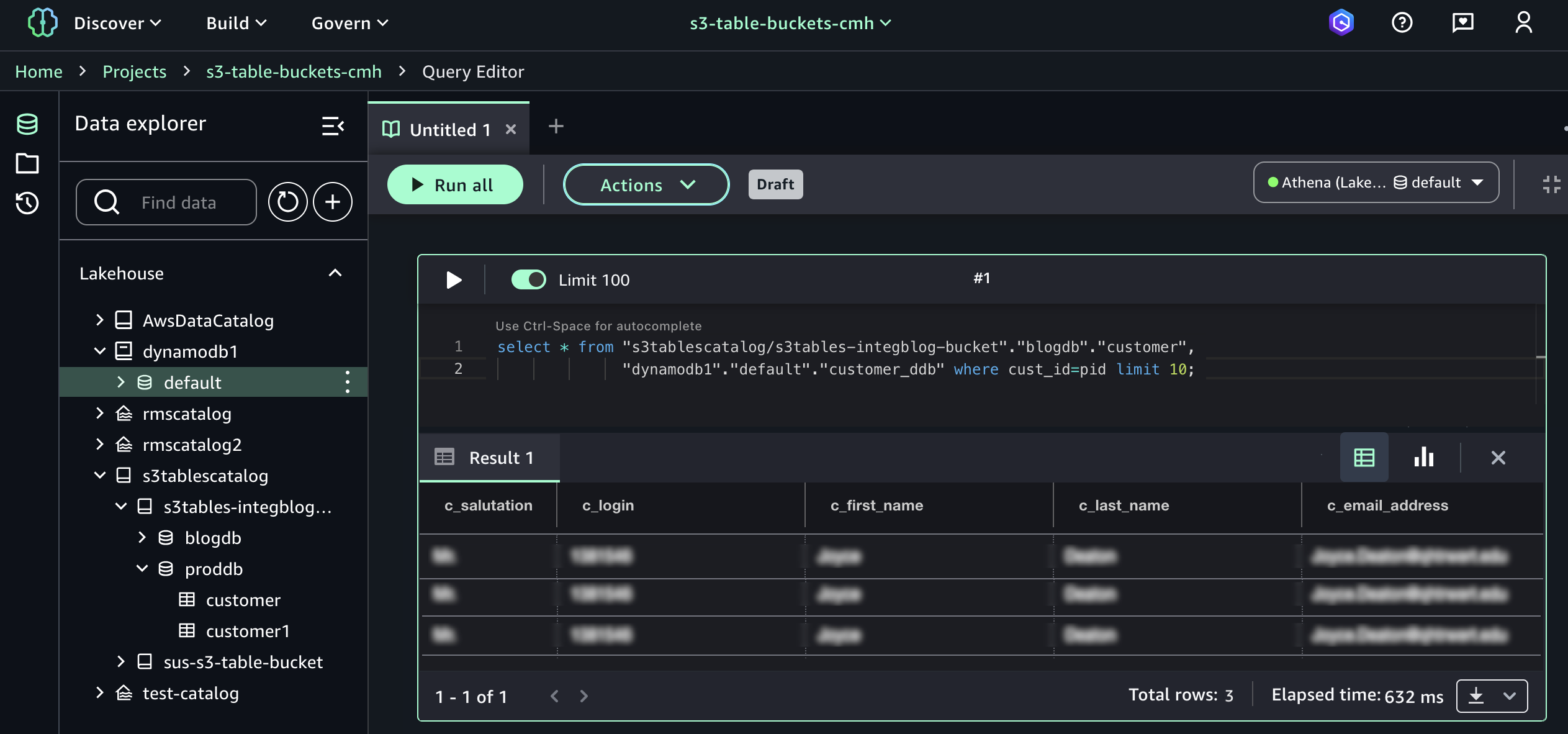
要了解有关此集成的更多信息,请访问亚马逊云科技文档中的 Amazon S3 Tables 与 Amazon SageMaker Lakehouse 的集成。
现已推出
S3 Tables 与 SageMaker Lakehouse 的集成,现已在所有提供 S3 Tables 的亚马逊云科技区域中普遍可用。要了解更多信息,请访问 S3 Tables 产品页面和 SageMaker Lakehouse 页面。
立即在 SageMaker Unified Studio 试一试 S3 Tables,向 Amazon S3 的亚马逊云科技 re:Post 和 Amazon SageMaker 的亚马逊云科技 re:Post 发送反馈,或者通过通常的亚马逊云科技支持联系人发送反馈。
在 Amazon S3 发布的年度庆祝活动中,我们将为 Amazon S3 和 Amazon SageMaker 推出更多精彩的产品。要了解更多信息,请参加 3 月 14 日的亚马逊云科技 Pi Day 活动。
— Channy
—
新闻博客怎么样?参加这个 1 分钟的调查!
(本调查由外部公司主办。亚马逊云科技按照亚马逊云科技隐私声明中的描述处理您的信息。亚马逊云科技将拥有通过本次调查收集的数据,不会与调查受访者共享收集的信息。)

Channy Yun (윤석찬)
Channy 是亚马逊云科技云的首席开发倡导者。作为一名开放网络爱好者和博客作者,他热爱社区驱动的学习和技术共享。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。