我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊 Redshift:更低的价格,更高的性能
与几乎所有客户一样,您希望尽可能少地花钱,同时获得尽可能好的性能。这意味着你需要注意性价比。有了
由于价格和性能都包含在性价比的计算中,因此有两种考虑性价比的方法。第一种方法是保持价格不变:如果你有 1 美元的支出,那么你的数据仓库能带来多少性能?性价比更高的数据库将为每花费1美元提供更好的性能。 因此,在比较两个成本相同的数据仓库时保持价格不变时,性价比更高的数据库将更快地运行您的查询。 看待性价比的第二种方法是保持性能不变:如果您需要在 10 分钟内完成工作负载,成本是多少?性价比更高的数据库将在 10 分钟内以较低的成本运行您的工作负载。因此,在比较两个大小可以提供相同性能的数据仓库时保持性能不变时,性价比更高的数据库将降低成本并为您节省资金。
最后,性价比的另一个重要方面是可预测性。了解随着数据仓库用户数量的增长,数据仓库将花费多少对于规划至关重要。它不仅应提供当今最好的性价比,还应以可预测的方式扩展,并在增加更多用户和工作负载时提供最佳性价比。理想的数据仓库应该具有 线性规模 — 理想情况下,扩展数据仓库以提供两倍的查询吞吐量,其成本应该是原来的两倍(或更少)。
在这篇文章中,我们分享了性能结果,以说明与领先的替代云数据仓库相比,Amazon Redshift 如何提供明显更好的性价比。这意味着,如果您在亚马逊 Redshift 上花费的金额与在其他数据仓库上花费的金额相同,则使用 Amazon Redshift 将获得更好的性能。或者,如果您调整 Redshift 集群大小以提供相同的性能,则与这些替代方案相比,您将看到更低的成本。
真实工作负载的性价比
您可以使用 Amazon Redshift 来支持各种各样的工作负载,从批处理基于提取、转换和加载 (ETL) 的复杂报告,以及实时流分析,到需要同时为数百甚至数千名用户提供亚秒级响应时间的低延迟商业智能 (BI) 控制面板,以及介于两者之间的所有内容。我们不断提高客户性价比的方法之一是不断审查来自 Redshift 机群的软件和硬件性能遥测数据,寻找可以进一步提高 Amazon Redshift 性能的机会和客户用例。
最近由舰队遥测推动的性能优化的一些示例包括:
- 字符串查询优化 — 通过分析 Amazon Redshift 如何处理 Redshift 队列中的不同数据类型,我们发现优化字符串密集型查询将为客户的工作负载带来显著好处。(我们将在本文后面更详细地讨论这个问题。)
-
自动物化视图
— 我们发现,Amazon Redshift 客户经常运行许多具有常见子查询模式的查询。例如,几个不同的查询可能使用相同的连接条件联接相同的三个表。Amazon Redshift 现在能够使用 Amazon Redshift 中机器学习的自动物化视图自治
功能自动创建和维护实例化视图,然后透明地重写查询以使用实例化视图 。 启用自动物化视图后,无需任何用户干预即可透明地提高重复查询的查询性能。(请注意,本文讨论的任何基准测试结果中均未使用自动实例化视图)。 - 高并发工作负载 — 我们看到越来越多的用例是使用 Amazon Redshift 来提供类似仪表板的工作负载。这些工作负载的特点是所需的查询响应时间为个位数秒或更短,有数十或数百个并发用户同时运行查询,其使用模式高峰且往往是不可预测的。这方面的典型示例是由 Amazon Redshift 支持的 BI 仪表板,当大量用户开始新的一周时,该仪表板的流量会激增。
特别是高并发工作负载具有非常广泛的适用性:大部分数据仓库工作负载以并发方式运行,数百甚至数千名用户同时在 Amazon Redshift 上运行查询的情况并不少见。Amazon Redshift 旨在保持查询响应时间的可预测性和快速性。Redshift Serverless 通过根据需要添加和删除计算来自动为您完成此操作,从而保持查询响应时间快速且可预测。这意味着由 Redshift Serverless 支持的仪表板在一两个用户访问时可以快速加载,即使许多用户同时加载仪表板也将继续快速加载。
为了模拟此类工作负载,我们使用了源自 TPC-DS 的基准测试,其数据集为 100 GB。TPC-DS 是一种行业标准基准测试,包括各种典型的数据仓库查询。在这个 100 GB 的相对较小的规模下,该基准测试中的查询平均在几秒钟内在 Redshift Serverless 上运行,这代表了加载交互式 BI 仪表板的用户的期望。我们对该基准测试进行了 1—200 次并行测试,模拟了 1—200 名用户同时尝试加载仪表板。我们还重复了对几个也支持自动扩展的热门替代云数据仓库的测试(如果你熟悉
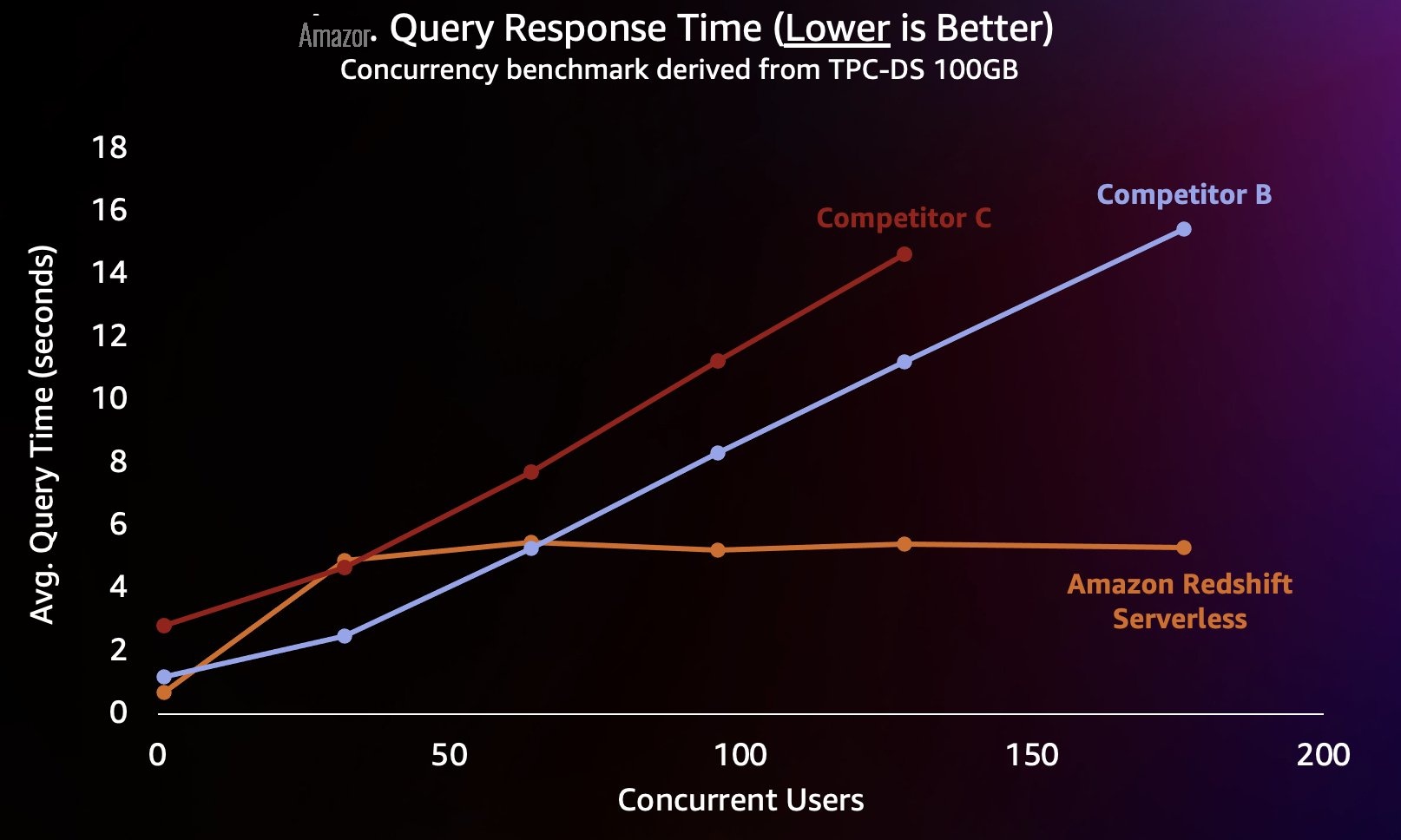
竞争对手 B 在大约 64 个并发查询之前可以很好地扩展,此时它无法提供额外的计算能力,查询开始排队,从而导致查询响应时间延长。尽管竞争对手 C 能够自动扩展,但它可以扩展到比 Amazon Redshift 和竞争对手 B 都更低的查询吞吐量,并且无法缩短查询运行时间。此外,当计算耗尽时,它不支持排队查询,这使其无法扩展到大约 128 个并发用户。除此之外提交其他查询将被系统拒绝。
在这里,即使有数百名用户同时运行查询,Redshift Serverless 也能够将查询响应时间保持在 5 秒左右,相对稳定。随着仓库负载的增加,竞争对手 B 和 C 的平均查询响应时间稳步增加,这导致当数据仓库繁忙时,用户必须等待更长时间(最多 16 秒)才能返回查询。这意味着,如果用户尝试刷新控制面板(重新加载后甚至可能提交多个并发查询),则即使控制面板由数十或数百名其他用户同时加载,Amazon Redshift 也能够保持控制面板加载时间更加稳定。
由于Amazon Redshift能够为短查询提供非常高的查询吞吐量(正如我们在
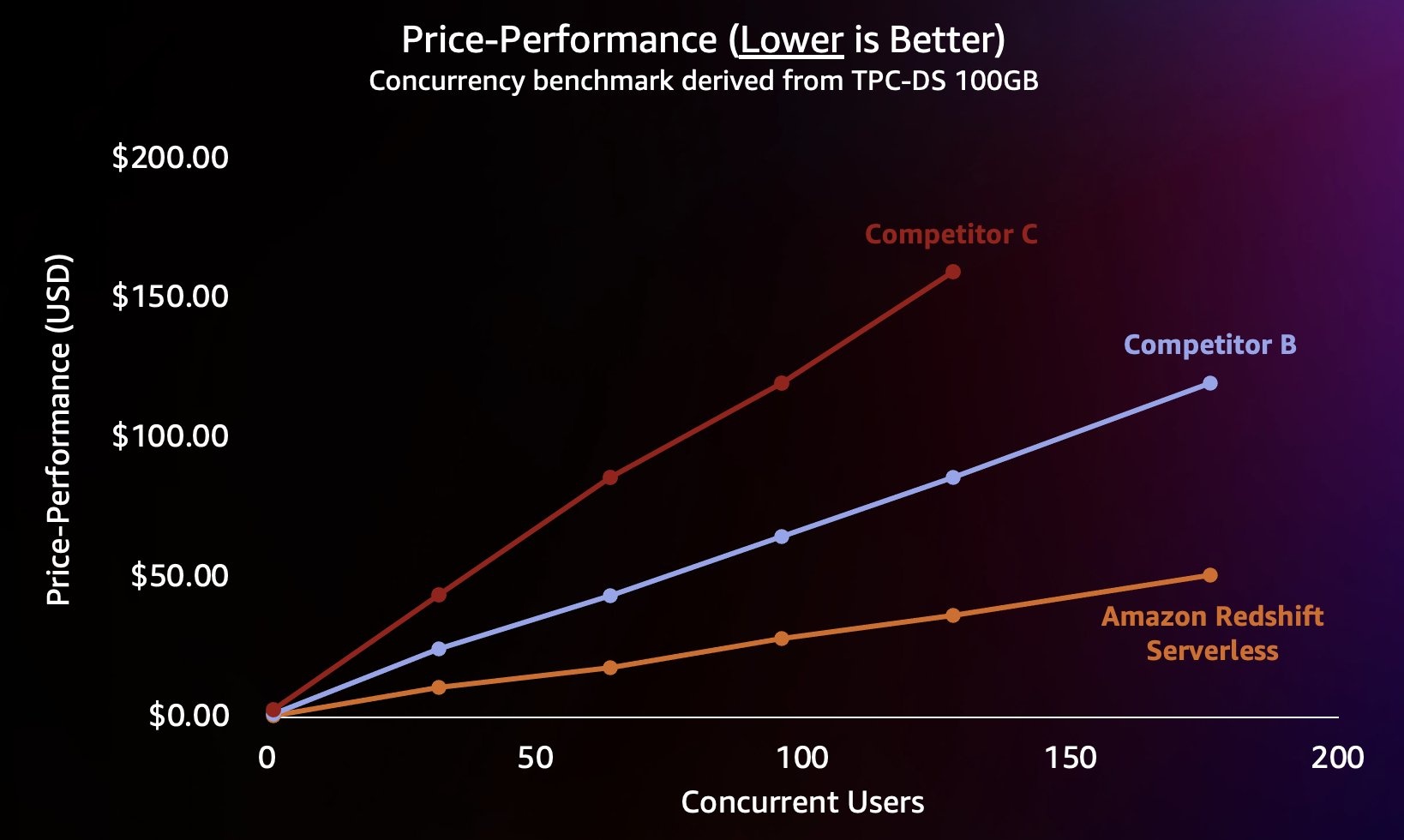
因此,Amazon Redshift不仅能够在更高的并发条件下提供更好的性能,而且能够以更低的成本提供更好的性能。性价比图表中的每个数据点等同于在指定并发下运行基准测试的成本。由于性价比是线性的,我们可以将任何并发运行基准测试的成本除以并发性(此图表中的并发用户数),以得出该特定基准测试每增加一个新用户的成本。
前面的结果很容易复制。基准测试中使用的所有查询都可以在我们的
优化字符串密集型工作负载
如前所述,Amazon Redshift团队一直在寻找新的机会,为客户提供更好的性价比。我们最近推出的一项显著提高性能的改进是优化了字符串数据的查询性能。例如,您可能需要使用诸如 SE
LECT sum(价格)FROM SUM SUM(价格),其中 city = 'New York '这样的查询来查找位于纽约 市的零售商店产生的总
收入。此查询对字符串数据(c
ity = 'New Yor k '
)应用谓词。可以想象,字符串数据处理在数据仓库应用程序中无处不在。
为了量化客户的工作负载访问字符串的频率,我们使用队列遥测对 Amazon Redshift 管理的数万个客户集群进行了详细的字符串数据类型使用情况分析。我们的分析表明,在90%的群集中,字符串列至少占所有列的30%,在50%的群集中,字符串列至少占所有列的50%。此外,在 Amazon Redshift 云数据仓库平台上运行的所有查询中,大部分都会访问至少一个字符串列。另一个重要因素是,字符串数据的基数通常较低,这意味着这些列包含相对较少的唯一值。
例如,尽管表示销售数据的
订单
表可能包含数十亿行,但该表中的
order_stat
us 列可能仅包含这数十亿行中的几个唯一值,例如
待处理 、处理
中
和 已完成。
为了进一步提高字符串密集型工作负载的性价比,Amazon Redshift 现在引入了额外的性能增强功能,与编码为 BYTEDICT 的低基数字符串列相比,比 LZO 或 ZSTD 等替代压缩编码快 5-63 倍(参见下一节中的结果)。Amazon Redshift 通过对轻量级、CPU 效率高、字节编码、低基数字符串列进行矢量化扫描来实现这种性能改进。这些字符串处理优化有效利用了现代硬件提供的内存带宽,从而实现了对字符串数据的实时分析。这些新引入的性能功能最适合低基数字符串列(最多几百个唯一字符串值)。
通过在 Amazon Redshift 数据仓库中启用
性能结果
为了衡量字符串增强对性能的影响,我们生成了一个由低基数字符串数据组成的 10TB(Tera Byte)数据集。我们使用短、中、长字符串生成了三个版本的数据,分别对应于 Amazon Redshift 舰队遥测中字符串长度的第 25、第 50 和第 75 个百分位数。我们将这些数据两次加载到 Amazon Redshift 中,在一种情况下使用 LZO 压缩对其进行编码,在另一种情况下使用 BYTEDICT 压缩进行编码。最后,我们测量了扫描量大的查询的性能,这些查询在这些低基数字符串数据集上返回许多行(占表的 90%)、中等数量的行(表的 50%)和几行(表的 1%)。下表汇总了性能结果。
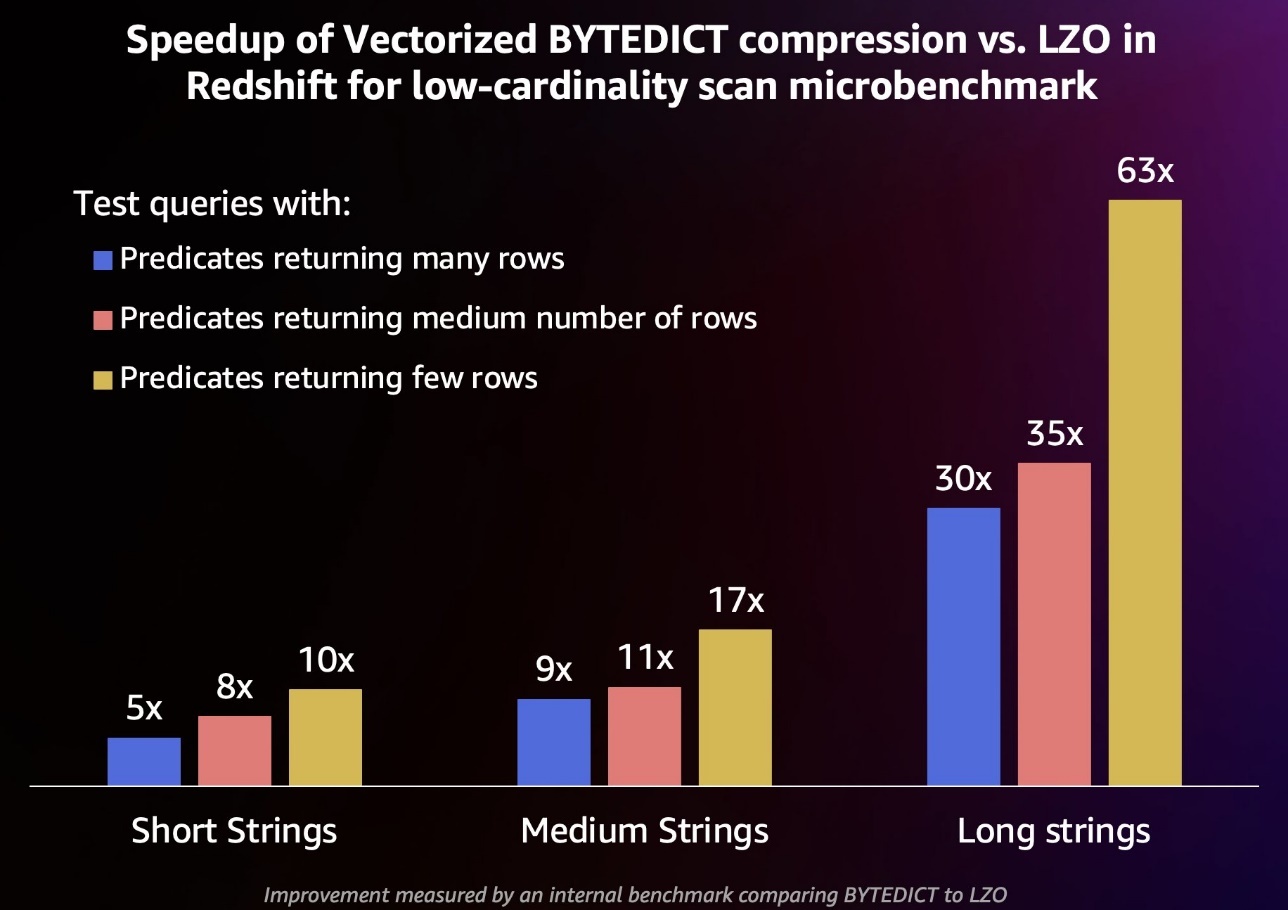
与 LZO 相比,使用新的矢量化 BYTEDICT 编码的谓词匹配的行百分比较高的查询提高了 5-30 倍,而在此内部基准测试中,具有较低行百分比匹配的谓词的查询提高了 10-63 倍。
Redshift 无服务器性价比
除了本文中介绍的高并发性能结果外,我们还使用了 TPC-DS 衍生的云数据仓库基准测试,将 Redshift Serverless 的性价比与使用更大 3TB 数据集的其他数据仓库的性价比进行了比较。我们选择了定价相似的数据仓库,在本例中,使用公开的按需定价,在每小时 32 美元的10%以内。这些结果表明,与亚马逊 Redshift RA3 实例一样,与其他领先的云数据仓库相比,Redshift 无服务器提供了更好的性价比。与往常一样,可以使用我们的
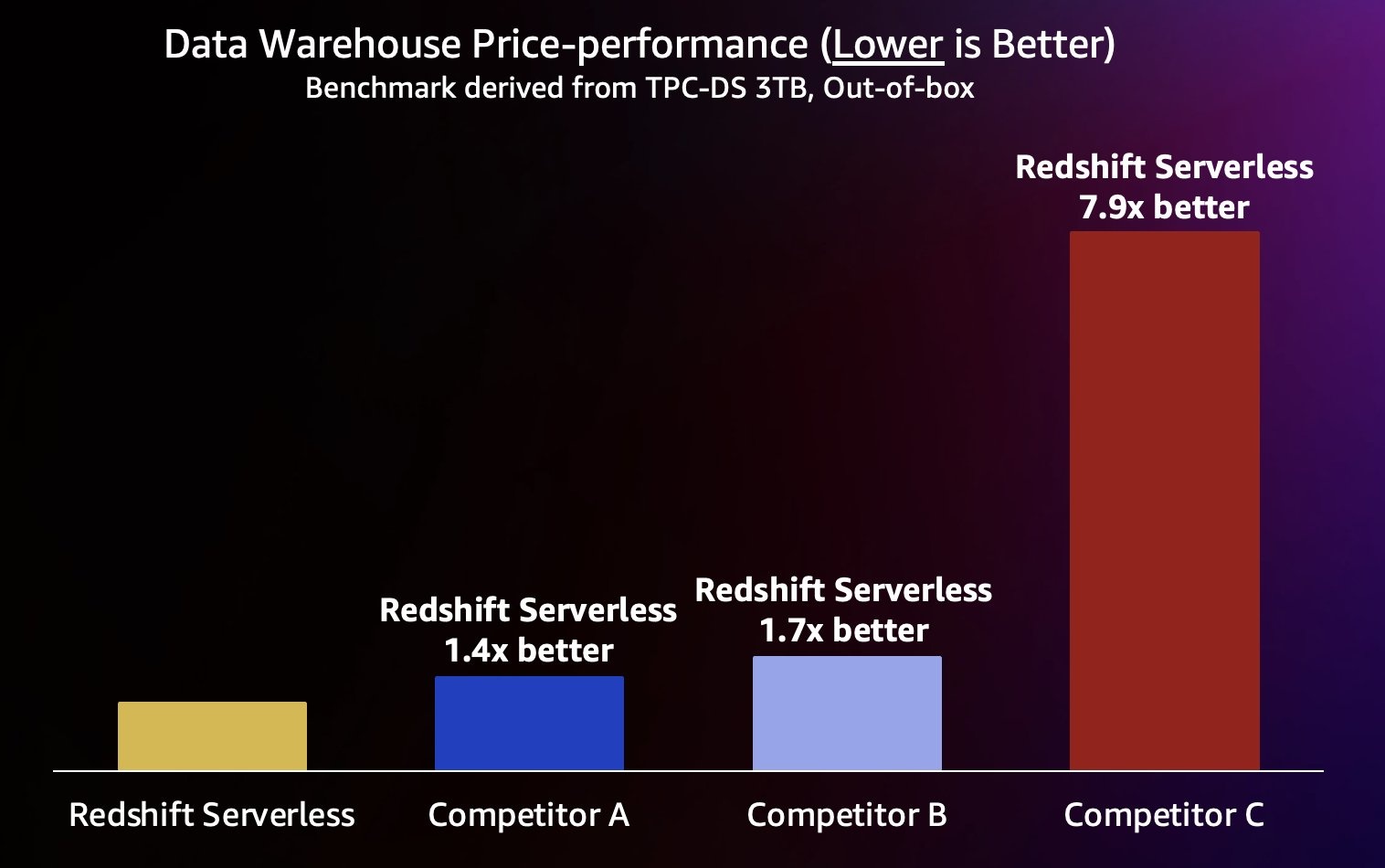
我们鼓励您使用自己的
为您的工作负载找到最佳性价比
本文中使用的基准来自行业标准的TPC-DS基准测试,具有以下特征:
- 在 TPC-DS 中使用架构和数据时未作任何修改。
- 查询是使用官方 TPC-DS 套件生成的,查询参数使用 TPC-DS 套件的默认随机种子生成。如果仓库不支持默认 TPC-DS 查询的 SQL 方言,则仓库将使用 TPC 批准的查询变体。
- 该测试包括 99 个 TPC-DS SELECT 查询。它不包括维护和吞吐量步骤。
- 在单个 3TB 并发测试中,运行了三次电源,每个数据仓库都采用了最佳运行结果。
- TPC-DS 查询的性价比按每小时成本 (美元) 乘以基准测试运行时间(以小时为单位)计算,这等于运行基准测试的成本。最新发布的按需定价用于所有数据仓库,而不是前面提到的预留实例定价。
我们称之为云数据仓库基准测试,您可以使用我们的
结论
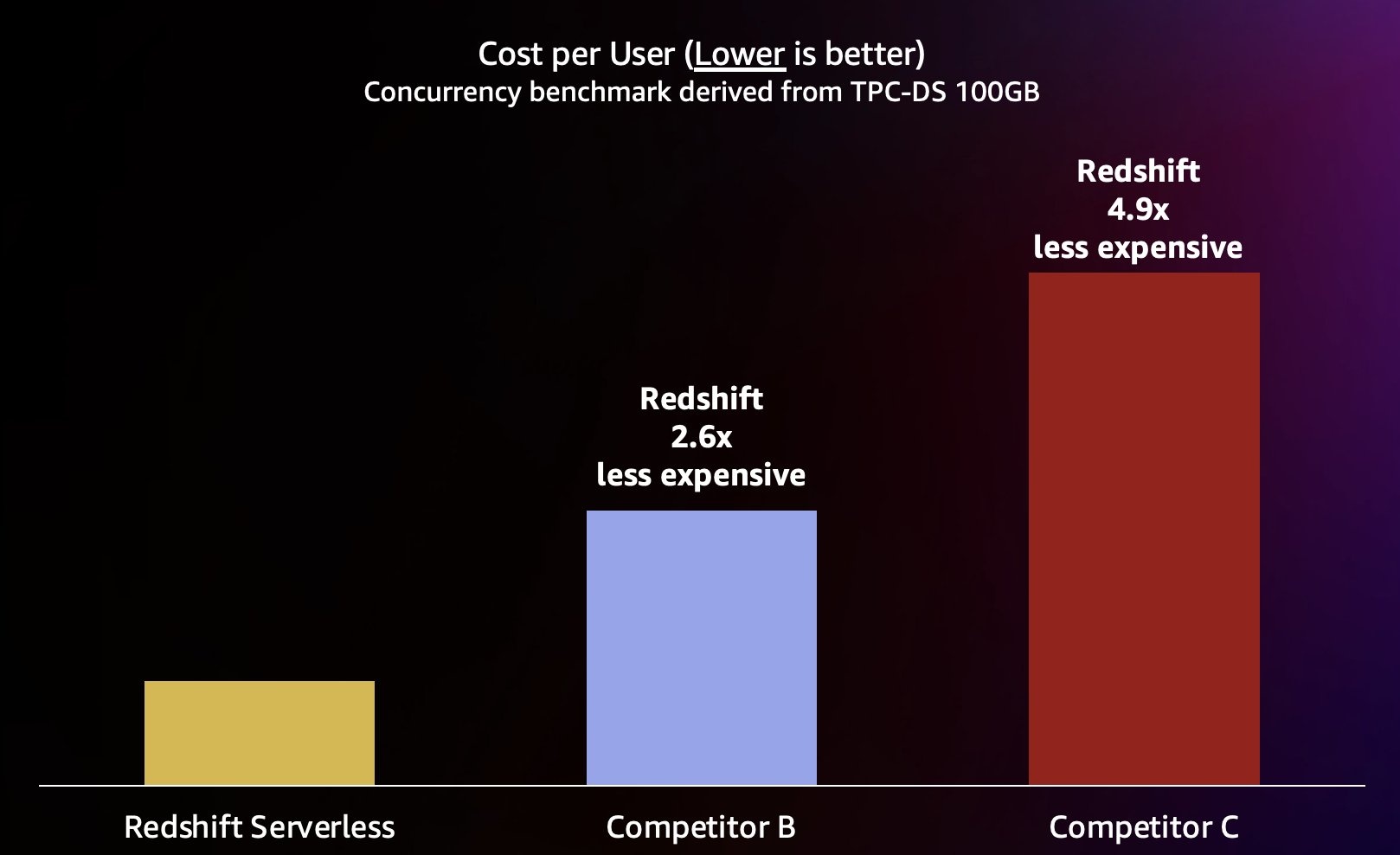
Amazon Redshift 致力于为最广泛的工作负载提供业界最佳的性价比。Redshift Serverless 以最佳(最低)的性价比线性扩展,支持数百名并发用户,同时保持一致的查询响应时间。根据本文中讨论的测试结果,与最接近的竞争对手(竞争对手B)相比,Amazon Redshift在相同并发水平下的性价比最高可提高2.6倍。如前所述,使用带有 3 年期全额预付选项的预留实例可以为您提供最低的运行 Amazon Redshift 的成本,与我们在本文中使用的按需实例定价相比,相对性价比甚至更高。我们的持续性能改进方法包括将客户对了解客户用例及其相关的可扩展性瓶颈的痴迷与持续的机队数据分析相结合,以发现进行重大性能优化的机会。
每种工作负载都有其独特的特征,因此,如果您刚刚起步,
要了解亚马逊 Redshift 的最新动态,请关注亚马逊 Redshi
作者简介
 斯特凡·格罗莫尔
是亚马逊 Redshift 团队的高级性能工程师,负责测量和改进 Redshift 性能。在业余时间,他喜欢做饭、和三个孩子一起玩以及砍柴火。
斯特凡·格罗莫尔
是亚马逊 Redshift 团队的高级性能工程师,负责测量和改进 Redshift 性能。在业余时间,他喜欢做饭、和三个孩子一起玩以及砍柴火。

 Aamer Shah
是亚马逊 Redshift 服务团队的高级工程师。
Aamer Shah
是亚马逊 Redshift 服务团队的高级工程师。
 Sanket Hase
是亚马逊 Redshift 服务团队的软件开发经理。
Sanket Hase
是亚马逊 Redshift 服务团队的软件开发经理。
 Orestis Polychroniou
是亚马逊 Redshift 服务团队的首席工程师。
Orestis Polychroniou
是亚马逊 Redshift 服务团队的首席工程师。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。