我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊 RDS:揭开快照、恢复和恢复的神秘面纱
在这篇文章中,我们深入探讨了 Amazon RDS 实例的快照和恢复是如何工作的。
亚马逊 RDS 快照概述
Amazon RDS 快照是在存储卷级别拍摄的,独立于原生引擎备份工具,例如适用于 Oracle 的 RMAN 或适用于 MySQL 实例的 mysqldump。Amazon RDS 卷的快照是增量的,当快照运行时,自动决定要备份哪些块。每张快照都包含将数据恢复到新卷所需的所有信息。Amazon RDS 快照存储在安全和加密的 亚马逊云科技 管理的 A
Amazon RDS 快照有两种类型:自动和手动。
要通过 亚马逊云科技 控制台修改首选备份窗口,请执行以下步骤。
- 转到实例页面
- 选择 “ 修改”
- 转到 “ 其他配置 ” 部分
- 在 “备份” 部分下,选择 “ 选择窗口 ” 单选按钮
- 指定所需的开始时间和持续时间
- 验证时间和持续时间是否符合预期
- 选择 “ 继续 ”
- 现在,您可以选择立即或在下一个维护时段 “安排修改”。
要通过 亚马逊云科技 CLI 修改首选备份窗口,您可以执行以下命令,将
< >
对于
下图说明了 Amazon RDS 单可用区快照的工作原理。

以下是 Amazon RDS 多可用区快照工作原理的基本示意图。
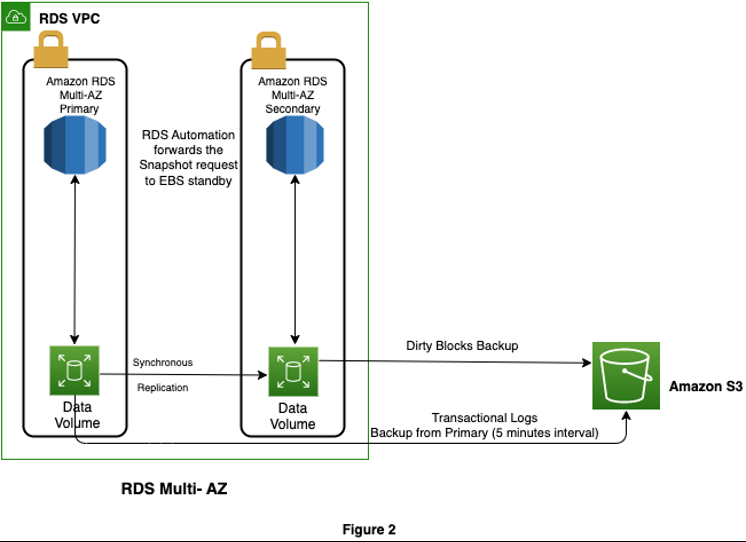
无论是
如果您正在寻找一种完全托管的服务来集中和自动保护整个 亚马逊云科技 服务的数据,那么我们鼓励您探索 AW
在这篇文章中,我们将重点介绍如何通过亚马逊 RDS 自动化和亚马逊 RDS 快照特定 API 管理亚马逊 RDS 快照和恢复。让我们详细了解一下快照和恢复在 Amazon RDS 中的工作原理。
自动快照
您可以使用自动快照将实例恢复到拍摄快照的时间。您也可以使用它来将
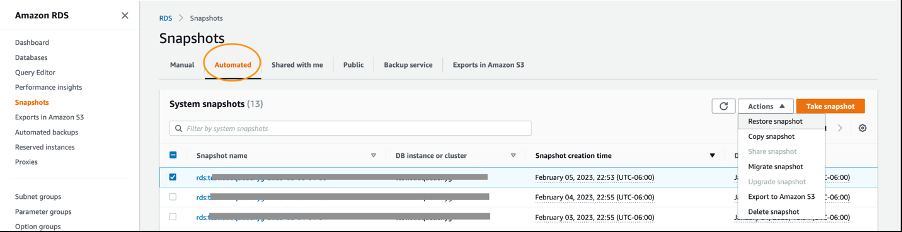
以下 Amazon RDS 控制台的屏幕截图显示了如何将自动快照恢复到拍摄时的时间。
手动快照
手动快照是用户启动的快照,您只能使用它恢复到拍摄快照时的时间。恢复手动快照就像恢复自动快照一样。不同之处在于,您可以随时拍摄手动快照,但自动快照只能在预定时段内启动。手动快照只有在通过 API 调用明确删除后才会被删除,而自动快照是根据自动快照
多可用区故障转移的备份时间
多可用区故障转移后,为什么第一个 Amazon RDS 快照需要更长时间?
正如 Amazon RDS 快照架构中所述,Amazon RDS 实例卷的快照始终取自多可用区备用实例,并且是增量的。多可用区备用实例的 Amazon E
时间点恢复
只有启用自动快照后,才能启动时间点恢复 (PITR)。使用 PITR,可以从数据库卷的自动快照中恢复 Amazon RDS 实例,然后应用事务日志使实例达到 API 调用中指定的时间。您最多可以将自动快照保留 35 天。
在执行 PITR 或恢复自动或手动快照时,会创建一个新实例。
有时,亚马逊 RDS PITR 需要很长时间才能完成,有时 PITR 会很快完成。这背后的原因是什么?
Amazon RDS 实例的 PITR 包含两个组件:还原和重放事务日志。执行卷恢复所需的时间是标准时间。重放事务日志所需的时间取决于在拍摄上一次自动快照的时间和 PITR API 调用中指定的时间之间存在的事务日志的数量和大小。因此,在不同的 PITR 时段内,同一 Amazon RDS 实例在 PITR 期间的差异取决于重播事务日志所需的持续时间。
假设亚马逊 RDS 实例的自动快照是在每天晚上 7:00 拍摄的。如果您在2023年1月26日晚上 10:00 之前对亚马逊 RDS 实例执行 PITR,则亚马逊 RDS 自动化将从 1 月 26 日晚上 7:00 拍摄的快照中恢复,并连续应用所有事务日志,直到 1 月 26 日晚上 10:00。Amazon RDS 自动化需要应用下午 7:00 至晚上 10:00 之间生成的 3 小时事务日志,以使 PITR 实例达到在 API 调用中指定的时间。因此,需要应用的事务日志越多,完成恢复所需的时间就越长。
PITR 也可能需要更长的时间才能完成,具体取决于作为实例恢复的一部分应用的事务日志的内容。
恢复后补水
在将快照 S3 存储桶中的所有数据块移至数据卷之前,恢复后会出现水合作用。如何缓解这种情况?
对于从快照还原的 Amazon RDS 实例(自动和手动),一旦配置了所需的基础设施,这些实例就会立即可用。但是,有一个持续的过程会继续将存储块从 Amazon S3 复制到 EBS 卷;这称为 延迟加载 。在进行延迟加载时,I/O 操作可能需要等待首先从 Amazon S3 读取要访问的块。这会导致 I/O 延迟增加,这并不总是会对使用 Amazon RDS 实例的应用程序产生影响。如果你想减少水化导致的缓慢,请在恢复完成后立即读取所有数据块。以下是适用于不同发动机的选项,可缩短完成补水所需的时间。请注意,这些选项是引擎原生命令,因此仅影响多可用区 Amazon RDS 的主实例。
在
-
使用 rdsadmin.rdsadmin_
rman_util.validate_database 包运行数据库级验证命令。可以根据 vCPU 的数量修改并行度以避免节流。 -
根据
引擎 许可,使用并行机制快速执行数据泵完整导出。 - 视情况使用并行提示,分别对所有大型或最常用的表进行显式选择。
在
-
使用
pg_prewarm共享库模块通读所有表 -
使用带有作业和纯数据参数的
pg_dump实用程序来导出所有应用程序架构 - 使用并行机制分别对所有大型且经常使用的表执行显式选择
在
- 并行对所有大型且经常使用的表格执行各种选择
-
使用
mysqldump 导出所有表
在
- 使用并行机制对所有大型且经常使用的表执行手动选择
摘要
在这篇文章中,我们解释了备份和恢复在 Amazon RDS 中的工作原理、导致备份和恢复时间增加的因素以及如何缩短这些因素。我们希望这篇文章能为您有关使用 Amazon RDS 快照和还原操作的问题提供急需的答案,并邀请您使用我们提供的提示尝试一些数据库恢复。
我们欢迎您的反馈。如果您有任何问题或建议,请将其留在评论部分。
作者简介
 Arnab Saha
是 亚马逊云科技 的高级数据库专家解决方案架构师。Arnab 专门研究亚马逊 RDS、亚马逊 Aurora 和亚马逊 EBS。他为客户提供指导和技术援助,使他们能够在 亚马逊云科技 云中构建可扩展、高度可用和安全的解决方案。
Arnab Saha
是 亚马逊云科技 的高级数据库专家解决方案架构师。Arnab 专门研究亚马逊 RDS、亚马逊 Aurora 和亚马逊 EBS。他为客户提供指导和技术援助,使他们能够在 亚马逊云科技 云中构建可扩展、高度可用和安全的解决方案。
 Deepak Mani
在亚马逊网络服务中 担任云支持 DBA II。他是适用于甲骨文的亚马逊 RDS 和亚马逊 RDS 的主题专家。Deepak 拥有 15 年的关系数据库使用经验。在 亚马逊云科技,他主要为适用于甲骨文的亚马逊 RDS、适用于 PostgreSQL 的亚马逊 RDS、Amazon Aurora PostgreSQL 和 亚马逊云科技 DMS 创建的高级支持票证和内部升级。
Deepak Mani
在亚马逊网络服务中 担任云支持 DBA II。他是适用于甲骨文的亚马逊 RDS 和亚马逊 RDS 的主题专家。Deepak 拥有 15 年的关系数据库使用经验。在 亚马逊云科技,他主要为适用于甲骨文的亚马逊 RDS、适用于 PostgreSQL 的亚马逊 RDS、Amazon Aurora PostgreSQL 和 亚马逊云科技 DMS 创建的高级支持票证和内部升级。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。