我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊 OpenSearch 服务的矢量数据库功能详解
作为最终用户,当你使用 OpenSearch 的搜索功能时,你通常会想到一个目标——这是你想要实现的目标。在此过程中,你可以使用 OpenSearch 来收集信息以支持实现该目标(或者信息可能是最初的目标)。我们都已经习惯了 “搜索框” 界面,你可以在其中键入一些单词,搜索引擎会根据逐字匹配返回结果。假设你想买一张沙发,以便与家人一起在火炉旁度过舒适的夜晚。你去亚马逊,然后输入 “坐在火炉旁的舒适地方”。不幸的是,如果你在 Amazon.com 上进行搜索,你会得到火炉、暖气扇和家居装饰品等物品,而不是你想要的。问题在于,沙发制造商可能没有在产品标题或描述中使用 “舒适”、“放置”、“坐下” 和 “开火” 等词。
近年来,机器学习 (ML) 技术在增强搜索功能方面变得越来越流行。其中包括使用嵌入模型,这种模型可以将大量数据编码到一个 n 维空间中,其中每个实体都被编码成一个向量,在该空间中是一个数据点,并进行组织以使相似的实体更加接近。例如,嵌入模型可以对语料库的语义进行编码。通过搜索最接近编码文档的向量(k 最近邻 (k-nn) 搜索),您可以找到语义上最相似的文档。复杂的嵌入模型可以支持多种模式,例如,对产品目录的图像和文本进行编码,并在两种模式上实现相似度匹配。
矢量数据库通过提供诸如 k-nn 索引之类的专用索引来提供有效的向量相似度搜索。它还提供其他数据库功能,例如管理矢量数据以及其他数据类型、工作负载管理、访问控制等。
使用 OpenSearch 服务作为矢量数据库
借助 OpenSearch Service 的矢量数据库功能,您可以实现语义搜索、带有 LLM 的检索增强生成 (RAG)、推荐引擎和搜索富媒体。
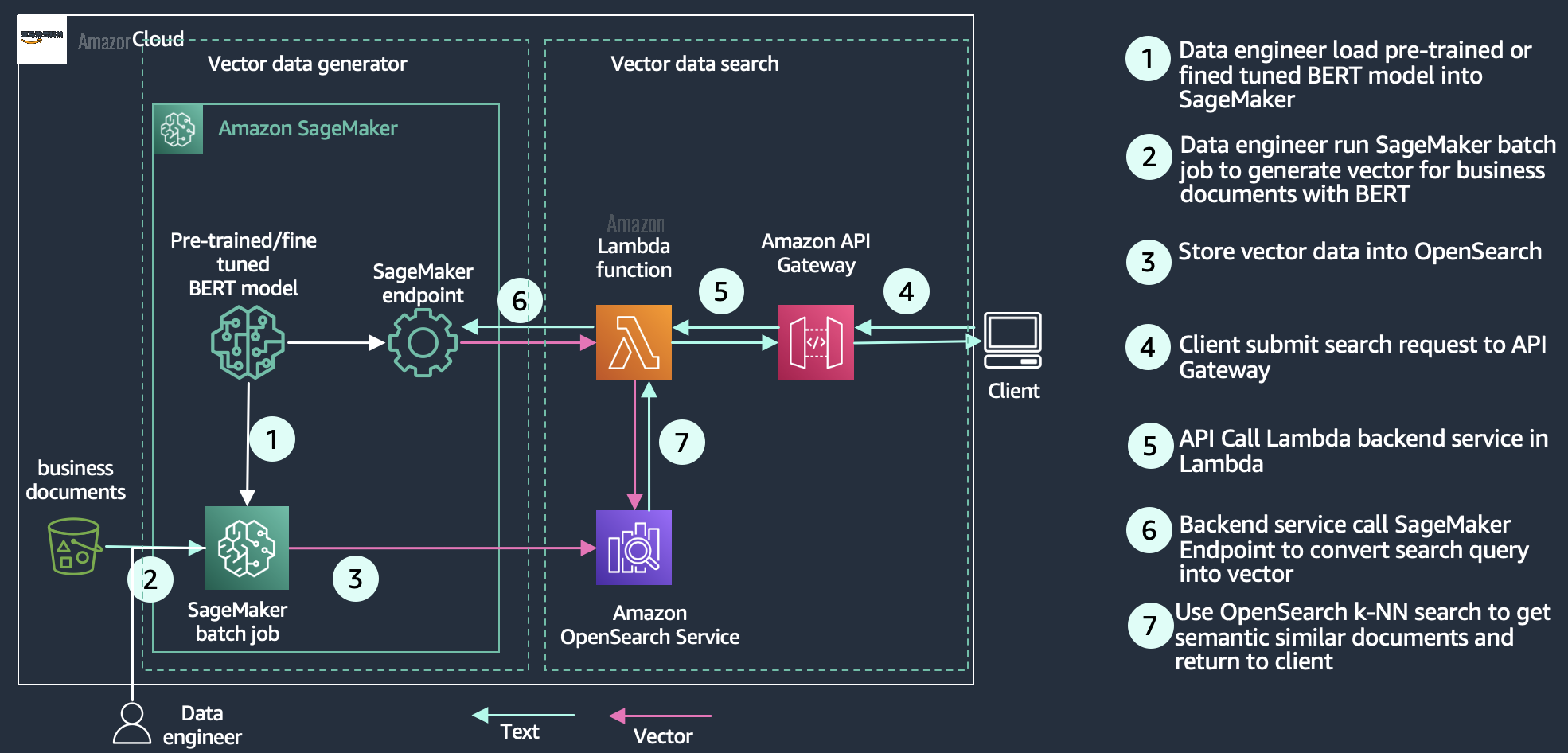
语义搜索
使用语义搜索,可以在搜索文档中使用基于语言的嵌入来提高检索结果的相关性。您可以让搜索客户使用自然语言查询,比如 “坐在火炉旁的舒适地方” 来寻找他们的 8 英尺长的蓝色沙发。有关更多信息,请参阅
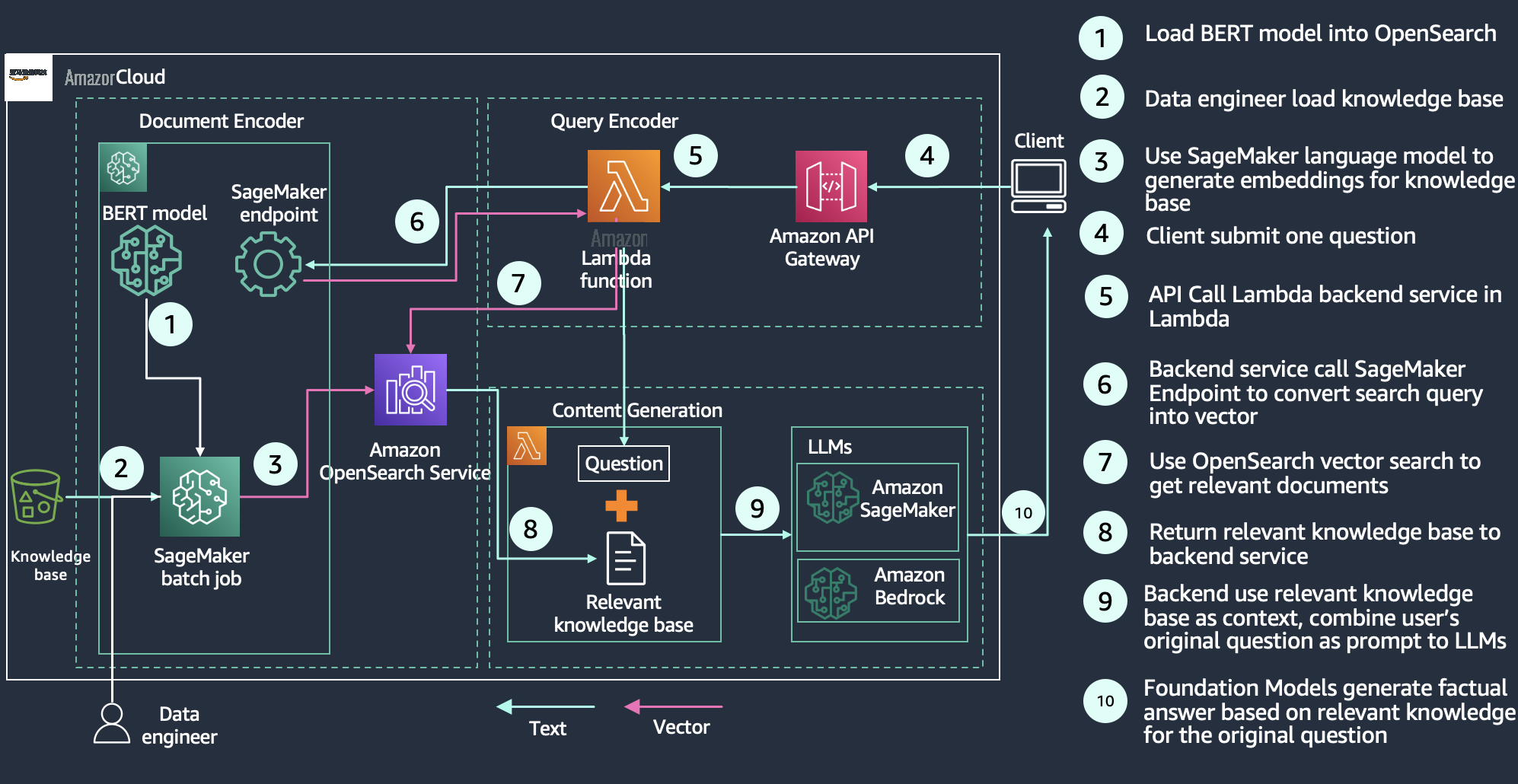
使用 LLM 进行检索增强生成
如下图所示,查询工作流程从一个问题开始,该问题经过编码,用于从矢量数据库中检索相关的知识文章。这些结果被发送到生成式 LLM,后者的工作是增强这些结果,通常是将结果总结为对话回应。通过用知识库补充生成模型,RAG 将模型建立在事实的基础上,以最大限度地减少幻觉。您可以在
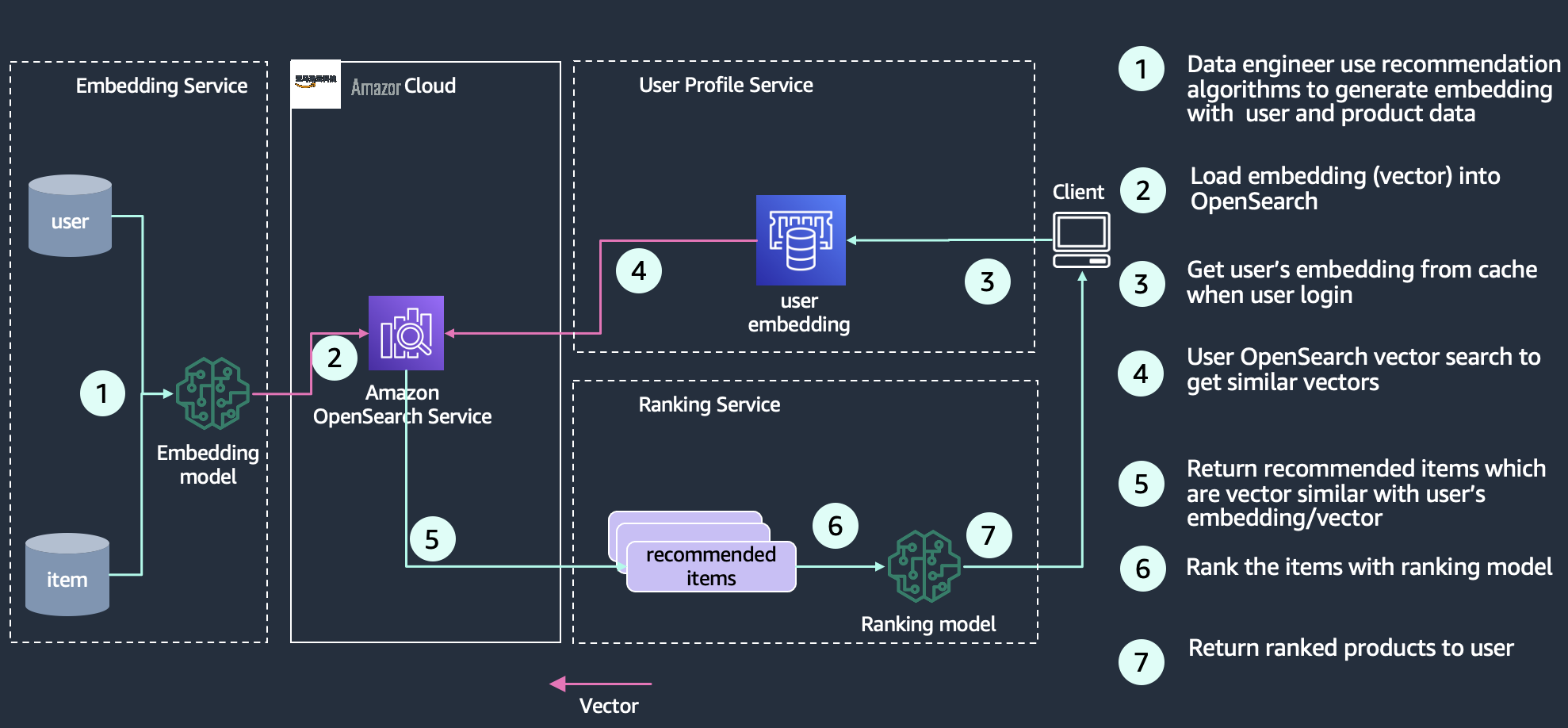
推荐引擎
推荐是搜索体验中的常见组成部分,对于电子商务应用程序尤其如此。添加诸如 “更像这样” 或 “购买此商品的客户也购买了那个” 之类的用户体验功能,可以通过为客户提供他们想要的东西来增加收入。
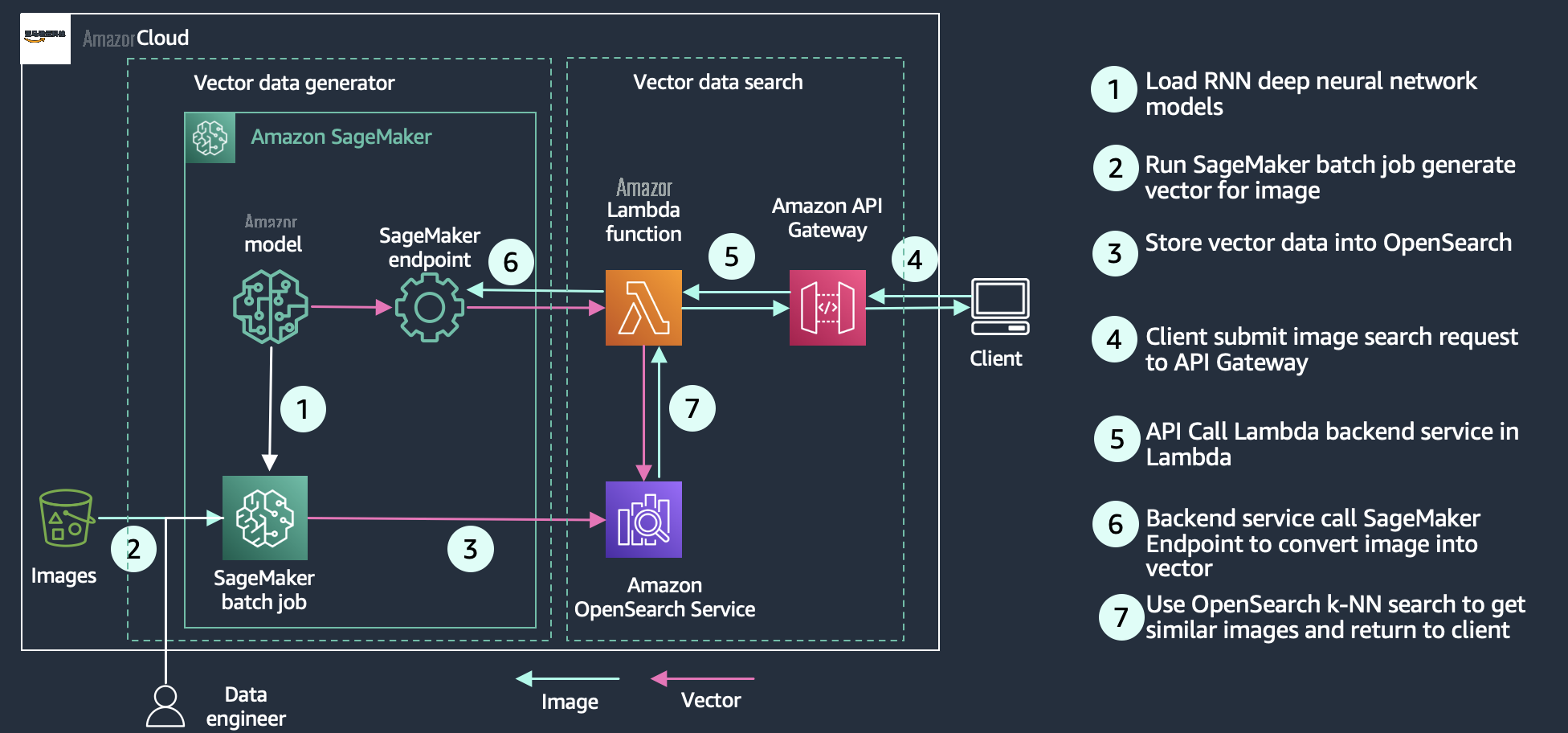
媒体搜索
媒体搜索使用户能够使用图像、音频和视频等富媒体来查询搜索引擎。它的实现与语义搜索类似,您可以为搜索文档创建向量嵌入,然后使用向量查询 OpenSearch Service。区别在于你使用诸如
了解这项技术
OpenSearch 使用来自
- 非公制空间库 (NMSLIB) — NMSLIB 实现 了 HNSW ANN 算法
- Facebook 人工智能相似度搜索 (FAISS) — FAISS 同时实现 HNSW 和 IVF ANN 算法
- Lucene — Lucene 实现了 HNSW 算法
用于近似 k-nn 搜索的三个引擎都有自己的属性,在给定情况下,这使得其中一个比其他引擎更明智地使用。您可以按照本节中的一般信息来帮助确定哪种引擎最能满足您的要求。
一般而言,应为大规模用例选择 NMSLIB 和 FAISS。Lucene 是小型部署的不错选择,但它具有诸如智能过滤之类的好处,即根据情况自动应用最佳过滤策略(预过滤、后过滤或精确 K-NN)。下表汇总了每个选项之间的差异。
| . |
NMSLIB-HNSW |
FAISS-HNSW |
FAISS-IVF |
Lucene-HNSW |
|
最大维度 |
16,000 |
16,000 |
16,000 |
1024 |
|
筛选 |
后置过滤 |
后置过滤 |
后置过滤 |
搜索时筛选 |
|
需要培训 |
没有 |
没有 |
是的 |
没有 |
|
相似度指标
|
l2,内积,cosinesimil,l1,linf |
l2,内部产品 |
l2,内部产品 |
l2,cosinesimil |
|
矢量体积 |
数百亿 |
数百亿 |
数百亿 |
< 一千万 |
|
索引延迟 |
低 |
低 |
最低 |
低 |
|
查询延迟和质量 |
低延迟和高质量 |
低延迟和高质量 |
低延迟和低质量 |
高延迟和高质量 |
|
向量压缩 |
平坦 |
平坦 产品量化 |
平坦 产品量化 |
平坦 |
|
内存消耗 |
高 |
高 PQ 值较低 |
中等 PQ 值较低 |
高 |
近似和精确的最近邻搜索
OpenSearch Service k-nn 插件支持三种不同的方法从向量索引中获取 k 最近的邻居:近似 k-nn、分数脚本(精确 k-nn)和无痛扩展(精确 k-nn)。
近似 k-nn
第一种方法采用近似最近邻法,它使用几种算法中的一种将近似 k 最近邻返回到查询向量。通常,这些算法会牺牲索引速度和搜索精度,以换取性能优势,例如更低的延迟、更小的内存占用和更具可扩展性的搜索。Approxy k-nn 是搜索需要低延迟的大型索引(即数十万个向量或更多)的最佳选择。如果要在 k-nn 搜索之前对索引应用滤镜,则不应使用近似 k-nn,这会大大减少要搜索的向量数量。在这种情况下,你应该使用分数脚本方法或无痛扩展。
分数脚本
第二种方法
_vector 字段或可以表示二进制对象的字段上运行暴力精确的 k-n
n 搜索。使用这种方法,您可以对索引中的向量子集运行 k-nn 搜索(有时称为
预过滤
搜索)。 与较小的文档正文相比,或者需要预过滤器时,这种方法是首选。在大型索引上使用这种方法可能会导致高延迟。
无痛延期
第三种方法将距离函数添加为无痛扩展,你可以将其用于更复杂的组合。与 k-nn 评分脚本类似,您可以使用此方法在索引中执行暴力精确的 k-nn 搜索,它还支持预过滤。与 k-nn 分数脚本相比,这种方法的查询性能略低。如果您的用例需要在最终分数上进行更多自定义,则应使用这种方法高于分数脚本 K-nn。
向量搜索算法
查找相似向量的简单方法是使用
分层可导航的小世界
HNSW 算法是目前最流行的 ANN 搜索算法之一。该算法的核心思想是构建一个边缘连接彼此靠近的索引向量的图形。然后,在搜索时,对该图形进行部分遍历以找到与查询向量最近的近邻。为了引导遍历向查询的最近邻域,该算法始终访问下一个查询向量最近的候选对象。
反向文件
IVF 算法将您的索引向量分成一组存储桶,然后,为了缩短搜索时间,只搜索这些存储桶的子集。但是,如果算法只是将你的向量随机分成不同的存储桶,并且只搜索其中的一个子集,那么得出的近似值就会很差。试管婴儿算法使用了更优雅的方法。首先,在开始索引之前,它会为每个存储桶分配一个代表性向量。对向量进行索引时,它会被添加到具有最接近代表向量的存储桶中。这样,彼此靠近的向量就会大致放置在相同或附近的存储桶中。
向量相似度指标
所有搜索引擎都使用相似度指标对结果进行排名和排序,并将最相关的结果带到顶部。使用纯文本查询时,相似度指标称为 TF-IDF,它衡量查询中术语的重要性,并根据文本匹配的数量生成分数。当您的查询包含向量时,相似度指标本质上是空间性的,它利用了向量空间中的邻近度。OpenSearch 支持多种相似度或距离测量值:
- 欧几里得距离 -点之间的 直线距离。
- L1(曼哈顿)距离 — 所有向量分量的差值之和。L1 距离用于测量从 A 点到 B 点需要穿越多少个正交城市街区。
- L 无限(棋盘)距离 — 国王在 n 维国际象棋盘上移动的次数。它与对角线上的欧几里得距离不同——二维棋盘上的对角线步距离 1.41 欧几里得单位,但距 2 个 L 无限单位。
- 内积 — 两个向量的大小与它们之间角度的余弦值的乘积。通常用于自然语言处理 (NLP) 向量相似度。
- 余弦相似度 — 向量空间中两个向量之间角度的余弦值。
- 汉明距离 -对于二进制编码向量,两个向量之间差异的位数。
OpenSearch 作为矢量数据库的优势
将 OpenSearch 服务用作矢量数据库时,可以利用该服务的可用性、可扩展性、可用性、互操作性和安全性等功能。更重要的是,你可以使用 OpenSearch 的搜索功能来增强搜索体验。例如,您可以 在 OpenSearch 中使用 “
规模和限制
OpenSearch 作为矢量数据库支持数十亿条向量记录。请记住以下有关向量数量和维度的计算器,以调整集群的大小。
向量数
OpenSearch VectorDB 利用了 OpenSearch 的分片功能,可以通过对向量进行分片以个位数毫秒的延迟扩展到数十亿个向量,并通过添加更多节点进行水平扩展。一台计算机中可以容纳的向量数量取决于计算机上堆外内存的可用性。所需的节点数将取决于每个节点可用于算法的内存量以及算法所需的总内存量。节点越多,内存越多,性能越好。
每个节点的可用内存量以 mem
ory_available = ( node_memory — jvm_
size ) * circuit_bre
aker_limit 计算得出
,参数如下:
- node_memory — 实例的总内存。
- jvm_size — OpenSearch JVM 堆大小 。这设置为实例 RAM 的一半,上限约为 32 GB。
- c@@ ircuit_breaker_limit — 断路器的本机内存使用阈值。此值设置为 0.5。
总聚类内存估计取决于向量记录和算法的总数。HNSW 和 IVF 有不同的内存要求。你可以参考
维度数
OpenSearch 当前对向量字段
knn_
vector 的维度限制为 16,000 个维度。每个维度都以 32 位浮点数表示。维度越大,索引和搜索所需的内存就越多。维度的数量通常由将实体转换为向量的嵌入模型决定。在构建
knn_
vector 字段时,有很多选项可供选择。要确定要选择的正确方法和参数,请参阅
客户故事:
亚马逊音乐
亚马逊音乐一直在创新,为客户提供独特的个性化体验。亚马逊音乐推荐音乐的方法之一是混搭亚马逊的经典创新、
逐件商品协作过滤器仍然是最受欢迎的在线产品推荐方法之一,因为它可以有效地扩展到大型客户群和产品目录。OpenSearch 通过提供横向扩展基础架构和 k-nn 索引(在对数时间内,轨道数量和相似度搜索呈线性增长),使推荐器的操作变得更加容易,并进一步提高了推荐器的可扩展性。
下图显示了向量嵌入所创建的高维空间。
亚马逊的品牌保护
亚马逊致力于提供世界上最值得信赖的购物体验,为买家提供尽可能广泛的正品选择。为了赢得和维护客户的信任,我们严格禁止销售假冒产品,并将继续投资于创新,以确保只有正品才能到达客户手中。亚马逊的品牌保护计划通过准确代表和全面保护品牌来建立与品牌的信任。我们努力确保公众的看法反映我们提供的值得信赖的体验。我们的品牌保护战略侧重于四大支柱:(1)主动控制(2)保护品牌的强大工具(3)追究不良行为者的责任(4)保护和教育客户。亚马逊 OpenSearch 服务是亚马逊主动控制的关键部分。
2022 年,亚马逊的自动化技术每天扫描超过 80 亿次对商品详情页面的更改尝试,以寻找潜在的滥用迹象。我们的主动控制系统在品牌必须找到并举报之前就发现了 99% 以上的被屏蔽或移除的商品。这些列表涉嫌欺诈、侵权、伪造或面临其他形式的滥用风险。为了进行这些扫描,亚马逊创建了使用先进和创新技术的工具,包括使用先进的机器学习模型自动检测全球亚马逊门店列表中的知识产权侵权行为。实施这种自动化系统的一个关键技术挑战是能否以快速、可扩展和具有成本效益的方式在庞大的十亿向量语料库中搜索受保护的知识产权。利用亚马逊 OpenSearch 服务的可扩展向量数据库功能和分布式架构,我们成功开发了一个采集管道,该管道已将 680 亿、128 和 1024 个维度的向量索引到 OpenSearch 服务中,使品牌和自动化系统能够通过高度可用且快速(亚秒)的搜索 API 实时进行侵权检测。
结论
无论你是在构建生成式 AI 解决方案、搜索富媒体和音频,还是为现有的基于搜索的应用程序提供更多语义搜索,OpenSearch 都是一个功能强大的矢量数据库。OpenSearch 支持各种引擎、算法和距离测量,您可以使用这些引擎、算法和距离测量来构建正确的解决方案。OpenSearch 提供了一个可扩展的引擎,可以支持低延迟的矢量搜索和多达数十亿个向量。借助 OpenSearch 及其矢量数据库功能,您的用户可以轻松找到那张 8 英尺蓝色的沙发,并在舒适的壁炉旁放松身心。
作者简介
 乔恩·汉德勒
是总部位于加利福尼亚州帕洛阿尔托的亚马逊网络服务的高级首席解决方案架构师。Jon 与 OpenSearch 和亚马逊 OpenSearch Service 紧密合作,为想要迁移到 亚马逊云科技 云的搜索和日志分析工作负载的众多客户提供帮助和指导。在加入 亚马逊云科技 之前,Jon 的软件开发生涯包括四年编写大型电子商务搜索引擎。Jon 拥有宾夕法尼亚大学文学学士学位和西北大学计算机科学与人工智能理学硕士和博士学位。
乔恩·汉德勒
是总部位于加利福尼亚州帕洛阿尔托的亚马逊网络服务的高级首席解决方案架构师。Jon 与 OpenSearch 和亚马逊 OpenSearch Service 紧密合作,为想要迁移到 亚马逊云科技 云的搜索和日志分析工作负载的众多客户提供帮助和指导。在加入 亚马逊云科技 之前,Jon 的软件开发生涯包括四年编写大型电子商务搜索引擎。Jon 拥有宾夕法尼亚大学文学学士学位和西北大学计算机科学与人工智能理学硕士和博士学位。
 李建伟
是亚马逊网络服务的首席分析专家 TAM。健威为客户提供顾问服务,帮助客户设计和建立现代数据平台。Janwei一直以软件开发人员、顾问和技术负责人的身份在大数据领域工作。
李建伟
是亚马逊网络服务的首席分析专家 TAM。健威为客户提供顾问服务,帮助客户设计和建立现代数据平台。Janwei一直以软件开发人员、顾问和技术负责人的身份在大数据领域工作。
 Dylan Tong
是亚马逊网络服务的高级产品经理。他领导了 OpenSearch 上的人工智能和机器学习 (ML) 产品计划,包括 OpenSearch 的矢量数据库功能。Dylan 拥有数十年的直接与客户合作以及在数据库、分析和 AI/ML 领域创建产品和解决方案的经验。Dylan 拥有康奈尔大学计算机科学学士学位和工程学硕士学位。
Dylan Tong
是亚马逊网络服务的高级产品经理。他领导了 OpenSearch 上的人工智能和机器学习 (ML) 产品计划,包括 OpenSearch 的矢量数据库功能。Dylan 拥有数十年的直接与客户合作以及在数据库、分析和 AI/ML 领域创建产品和解决方案的经验。Dylan 拥有康奈尔大学计算机科学学士学位和工程学硕士学位。
 Vamshi Vijay Nakkirtha
是一名软件工程经理,负责开发 OpenSearch 项目和亚马逊 OpenSearch 服务。他的主要兴趣包括分布式系统。他是各种插件的积极贡献者,例如K-nn、GeoSpatial和仪表板地图。
Vamshi Vijay Nakkirtha
是一名软件工程经理,负责开发 OpenSearch 项目和亚马逊 OpenSearch 服务。他的主要兴趣包括分布式系统。他是各种插件的积极贡献者,例如K-nn、GeoSpatial和仪表板地图。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。