我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊 OpenSearch 无服务器扩展了对大型工作负载和集合的支持
我们最近宣布了对
OpenSearch 无服务器中用于数据提取、搜索和查询的计算容量以 OpenSearch 计算单位 (OCU) 来衡量。为了支持更大的数据集,我们已将索引和搜索的 OCU 限制从 50 提高到 100,包括可用区中断和基础设施故障时的冗余。这些 OCU 在不同的集合之间共享,每个集合都包含一个或多个大小不同的索引。您可以使用
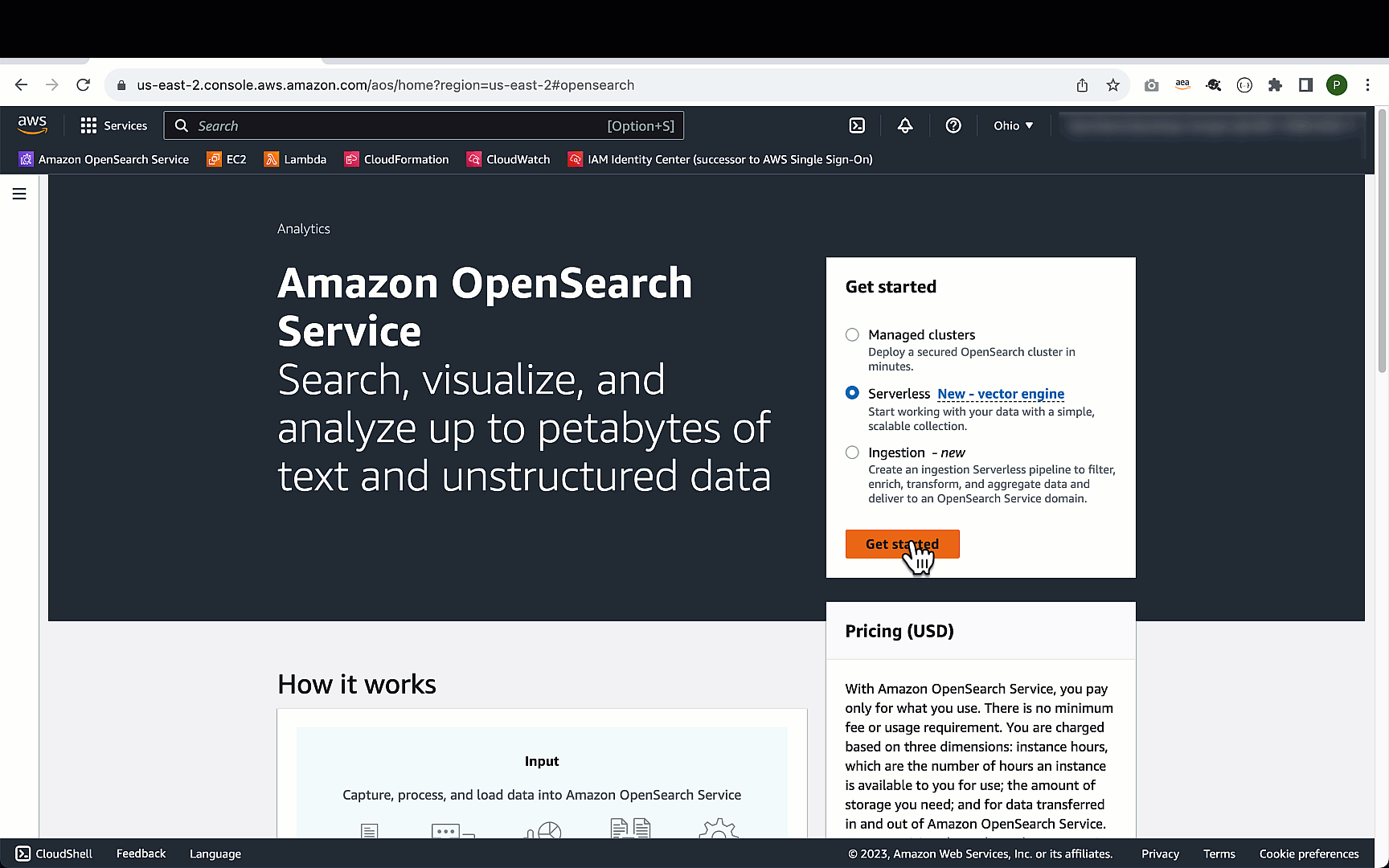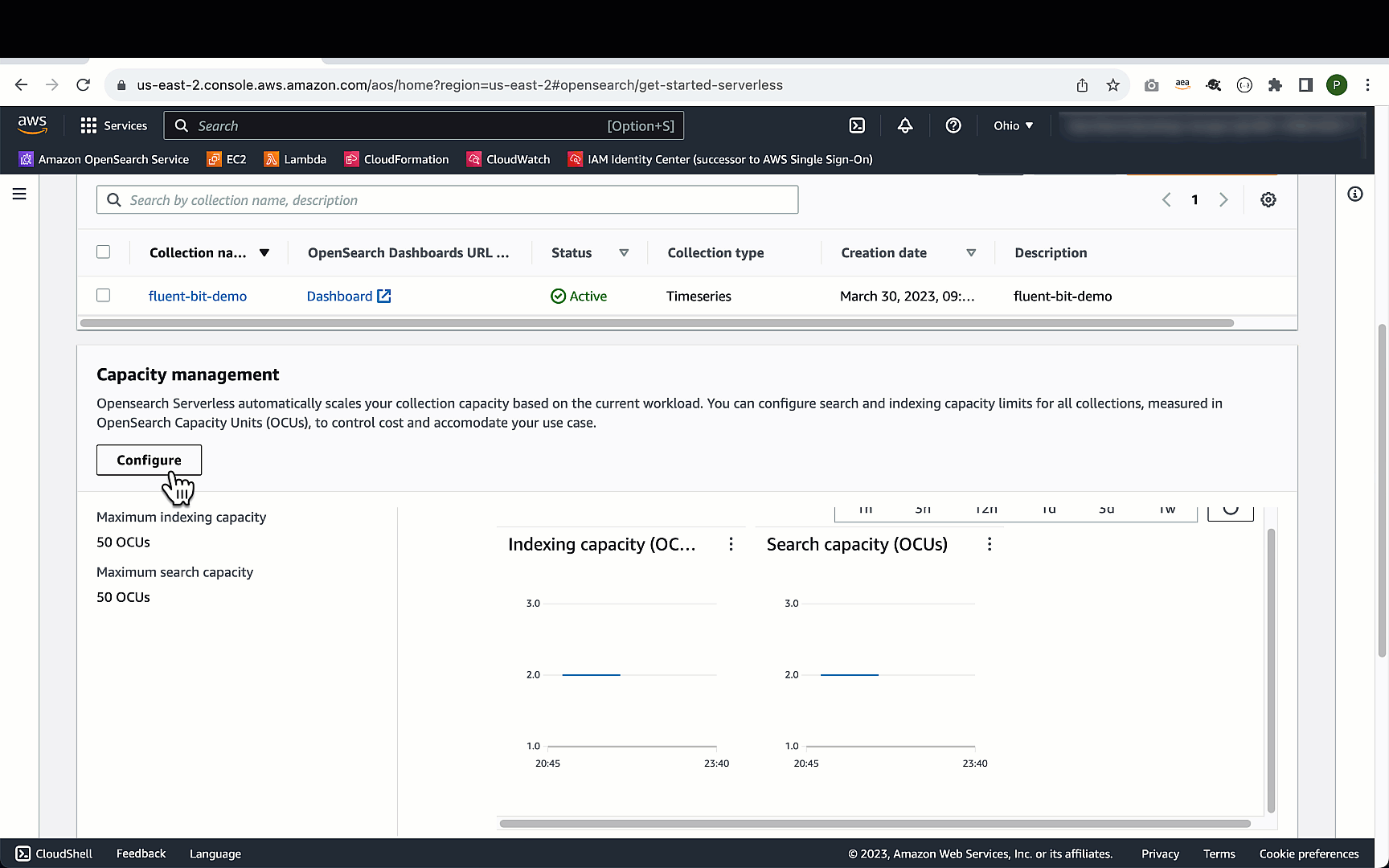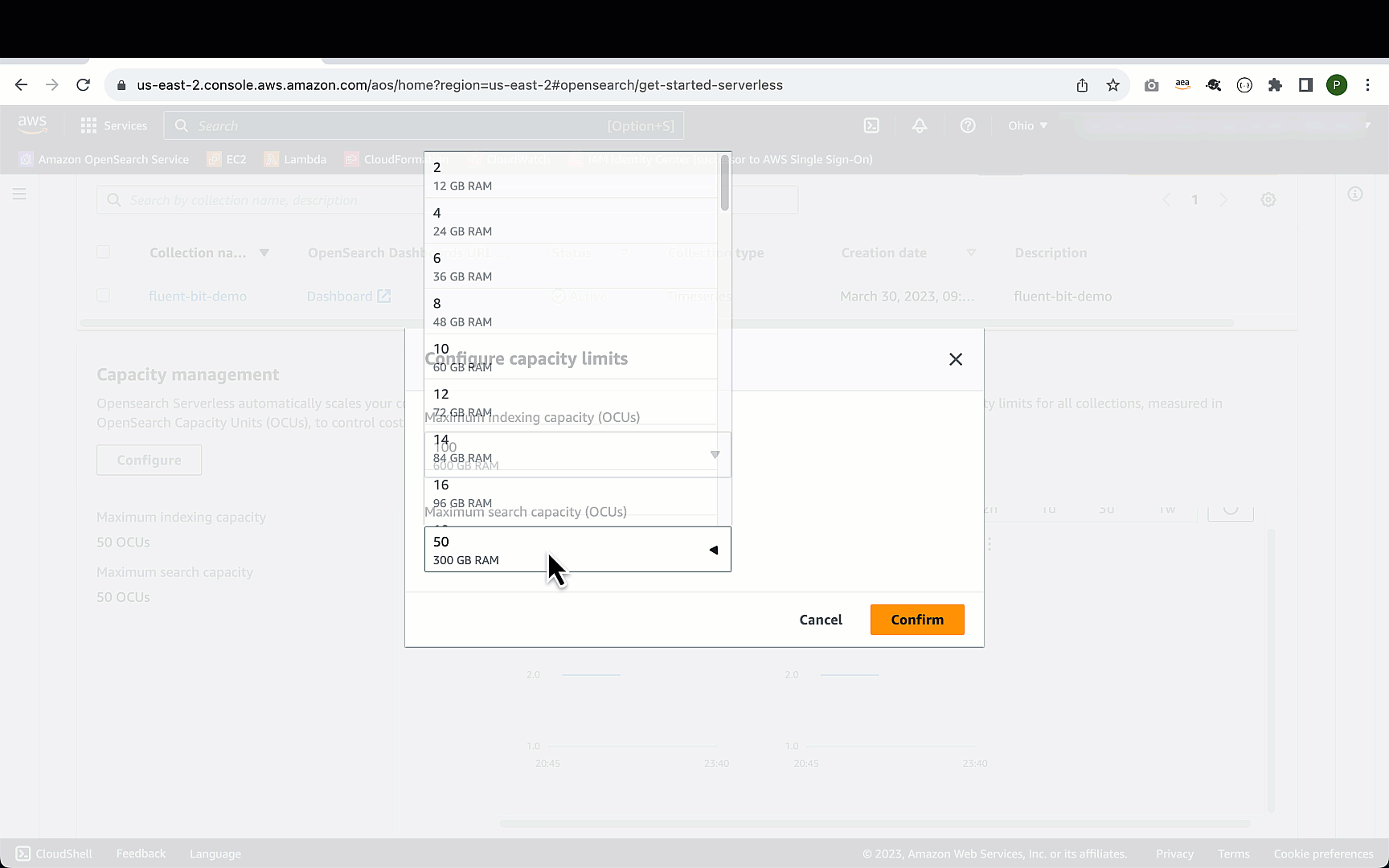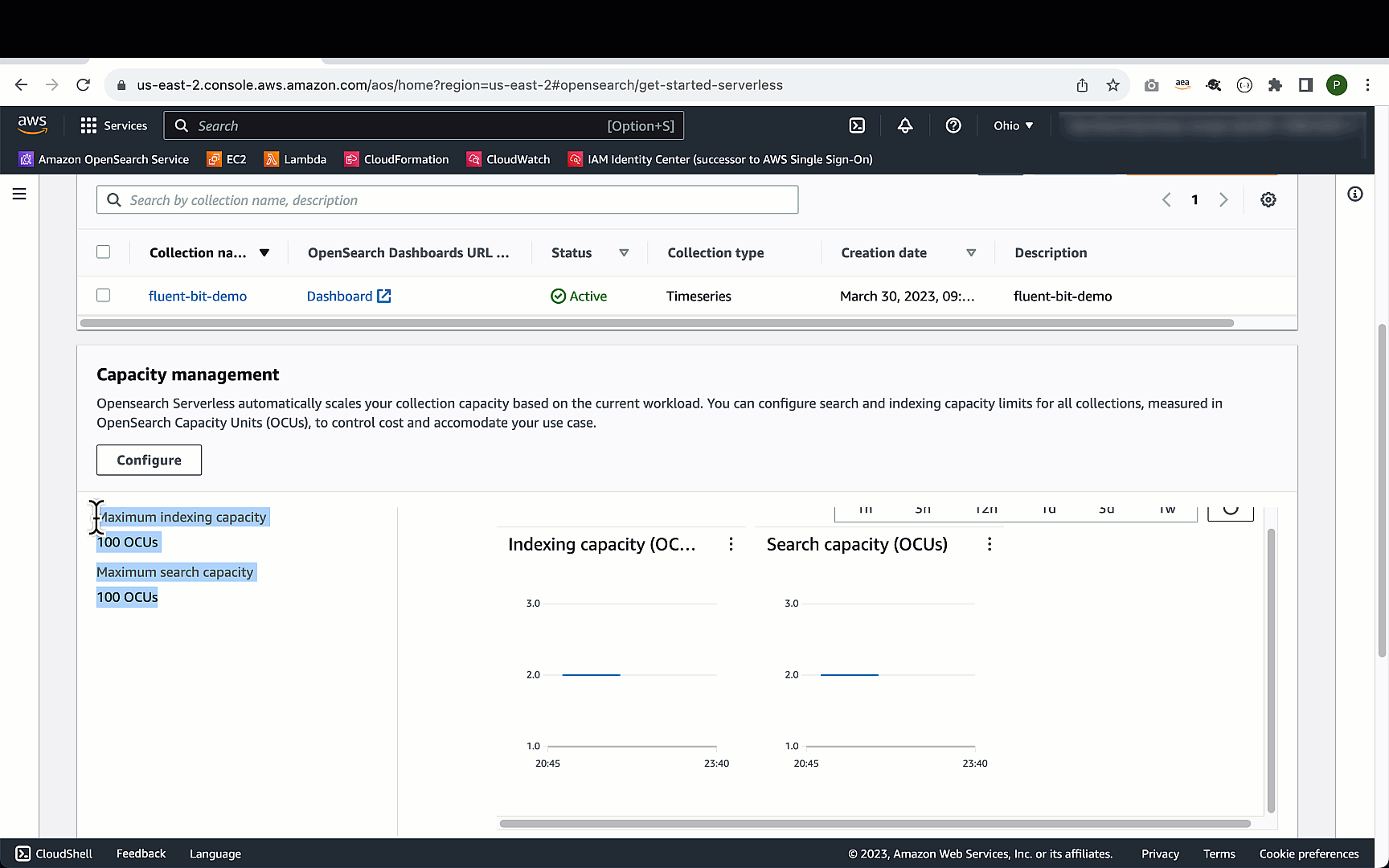
将最大 OCU 设置为 100
要开始使用,您必须先将索引和搜索的 OCU 限制更改为 100。请注意,您只需为消耗的资源付费,而不必为最大 OCU 配置付费。
摄取数据
您可以使用在以下

在 OpenSearch 无服务器中自动扩展资源
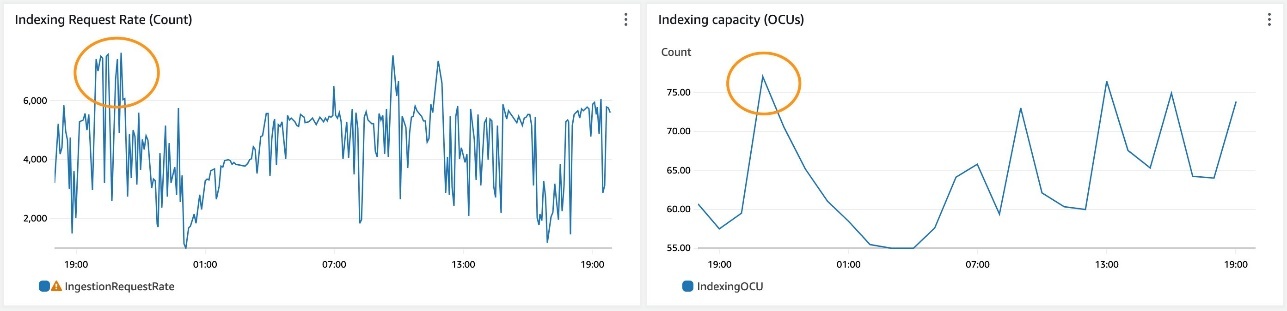
下图中的重点显示了 OpenSearch Serverless 如何通过自动扩展 OCU 来响应不断增长的索引流量,从 2,000 次批量请求操作增加到每秒 7,000 个批量请求。每个批量请求都包含 7,500 个文档。OpenSearch Serverless 使用各种系统信号根据您的工作负载需求自动扩展 OCU。
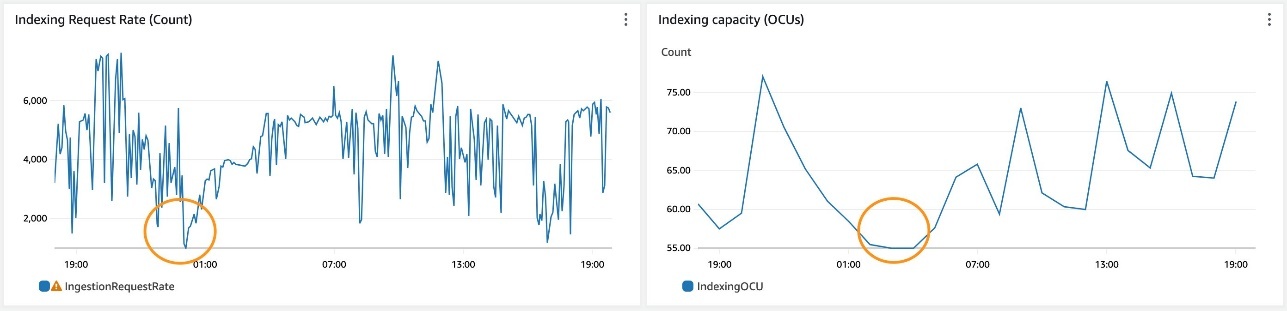
当工作负载的活动水平下降时,OpenSearch Serverless 还会缩小索引 OCU 的规模。下图中的突出显示点显示,索引流量从每秒 7,000 次批量采集操作逐渐减少到每秒 1,000 次以下。OpenSearch 无服务器通过减少 OCU 的数量来对负载变化做出反应。
结论
我们鼓励您利用 6 TB 索引支持并对其进行测试!迁移您的数据,探索提高的吞吐量,并利用增强的扩展功能。我们的目标是提供符合您要求的无缝高效体验。
要开始使用,请参阅
如果您对这篇文章有反馈,请在评论部分分享。如果您对这篇文章有疑问,请在
作者简介
 Prashant Agrawal
是亚马逊 OpenSearch Service 的高级搜索专家解决方案架构师。他与客户紧密合作,帮助他们将工作负载迁移到云端,并帮助现有客户微调集群以提高性能并节省成本。在加入 亚马逊云科技 之前,他帮助各种客户使用 OpenSearch 和 Elasticsearch 进行搜索和日志分析用例。不工作时,你会发现他在旅行和探索新的地方。简而言之,他喜欢做 “吃” → “旅行” → “重复”。
Prashant Agrawal
是亚马逊 OpenSearch Service 的高级搜索专家解决方案架构师。他与客户紧密合作,帮助他们将工作负载迁移到云端,并帮助现有客户微调集群以提高性能并节省成本。在加入 亚马逊云科技 之前,他帮助各种客户使用 OpenSearch 和 Elasticsearch 进行搜索和日志分析用例。不工作时,你会发现他在旅行和探索新的地方。简而言之,他喜欢做 “吃” → “旅行” → “重复”。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。