我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊 Kinesis Data Streams 按需容量模式现在可扩展到 1 GB/秒的采集容量
客户采用按需容量模式令我们感到鼓舞,但随着客户扩展工作负载,有些客户达到了 200 Mb/s 的数据摄取限制,并要求提供解决方案。该团队从客户反馈中反过来提高了这一限制。截至 2023 年 3 月,
在这篇文章中,我们将探讨如何使用 Kinesis Data Streams 按需扩展和最佳实践来构建高效的数据流解决方案。我们将讨论不同的场景,以避免写入吞吐量异常,并在按需容量模式下将 Kinesis Data Streams 的采集容量扩展到 1 Gb/s。
Kinesis 数据流按需扩展
分片用作 Kinesis 数据流的基本吞吐量单位。分片支持 1 Mb/s 和 1,000 条记录/秒进行写入,2 Mb/s 用于读取。分片限制确保了可预测的性能,使设计和操作高度可靠的数据流工作流程变得容易。在按需容量模式下,扩展发生在单个分片级别。当平均采集分片利用率在 1 分钟内达到 50%(0.5 Mb/s 或 500 条记录/秒)时,一个分片将被拆分为两个分片。如果您使用随机值作为分区键,则流的所有分片将具有均匀的流量,并且它们将同时进行扩展。如果您使用业务专用密钥作为分区键,则分片的流量将不均衡。在这种情况下,只有超过平均利用率50%的分片才能扩展。根据要缩放的分片数量,分割分片最多需要 15 分钟。
当我们在按需容量模式下创建新的 Kinesis 数据流时,默认情况下,Kinesis Data Streams 会预置四个分片,提供 4 Mb/s 的写入吞吐量和 8 Mb/s 的读取吞吐量。随着工作负载的增加,Kinesis Data Streams 通过监控分片级别的摄取吞吐量来增加数据流中的分片数量。在按需容量模式下,4 Mb/s 的默认摄取吞吐量和分片级别扩展适用于大多数用例。但是,在某些特定情况下,即使在
按
需容
量模式下,生产者也可能会面临 WriteThroughputExceeded
和 Rate Exceede d 错误。我们将在以下部分中讨论其中的一些场景以及避免这些错误的策略。
您可以创建和保存记录模板,并使用
场景 1:需要大于 4 Mb/s 的基准采集吞吐量
要模拟此场景,请运行以下
kds-od-default-s
hards 数据流:
当
kds-od-default-shards
数据流处于活动状态时,运行以下 亚马逊云科技 CLI 命令来检查数据流中的分片数量:
你可以观察到 OpenShardCount 的值为 4,这意味着
kds-od-default-shards 数据
流的采集容量为 4 Mb/s。
接下来,我们使用 Locust 工具将基准设置为大约 25 Mb/s 的记录。如下面的
kds-od-default-shards 数据流会扩展分片
数量以支持 25 Mb/s 的采集吞吐量,并且记录不再受到限制。您也可以重新运行 d
escribe-stream-summary
亚马逊云科技 CLI 命令来检查数据流中增加的分片数量。

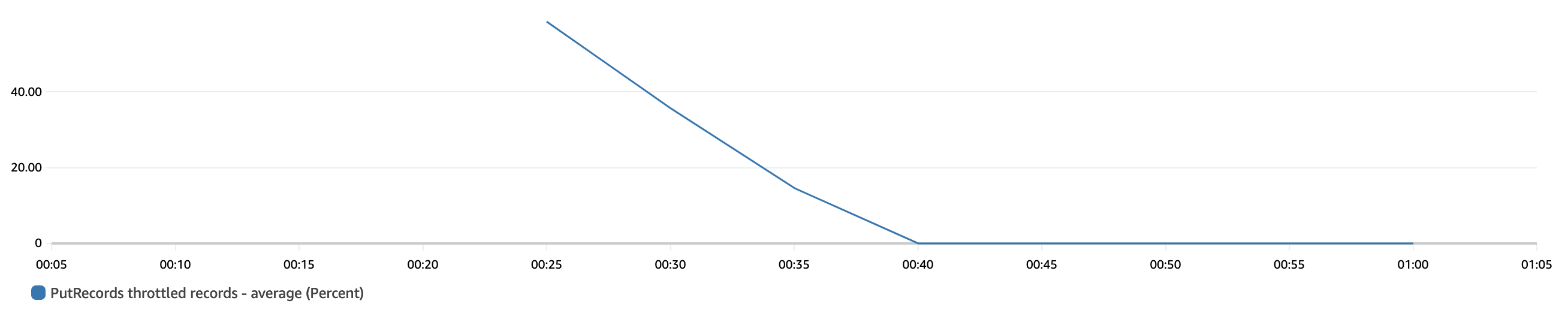
在我们提前知道采集吞吐量基准(25 MB/s)且不想遵守任何写入限制的情况下,我们可以通过指定分片数量 (30) 在预置模式下创建流,如以下 亚马逊云科技 CLI 命令所示(请务必在运行以下命令之前从 Kinesis Data Streams 控制台手动删除
kds-od-default-sh
ards):
当
kds-od-default-shards
数据流处于活动状态时,运行以下 亚马逊云科技 CLI 命令将数据流的容量模式转换为按需模式:
接下来,我们向
kds-od-default-shard
s 数据流发送 25 Mb/s 的记录。如以下 CloudWatch 指标图表所示,我们可以观察到没有写入限制,而且
kds-od-default-shards 数据流会调整分片数量
以应对采集量的增加。
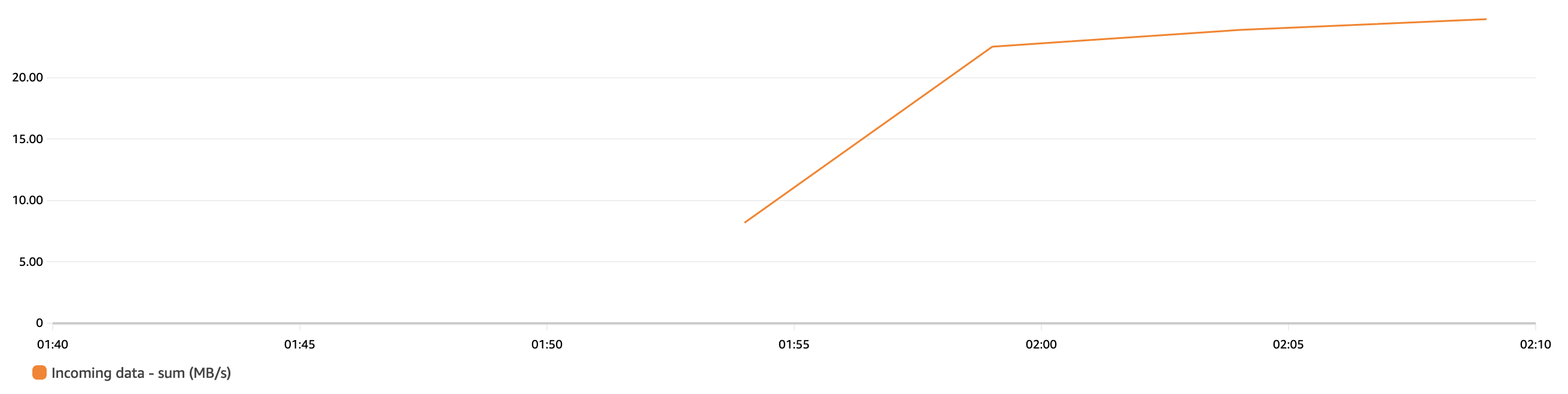

在我们向数据流发送 25 Mb/s 的流量一段时间后,我们可以运行以下 亚马逊云科技 CLI 命令来查看 OpenShardCount 的值现在增加到 30 以上:
场景 2:预计会出现显著的摄取高峰,这需要大于流中分片数量的摄取吞吐量
要模拟场景,请运行以下 亚马逊云科技 CLI 命令,在按需容
量模式下创建 kds-od-evitiant-sp
ike 数据流:
如前所述,默认情况下,
kds-od-evitiant-spike
数据流最初将有四个分片,因为该数据流是在按需模式下创建的。当数据流处于活动状态时,我们最初发送 4 Mb/s 的采集吞吐量,并将采集吞吐量每 5-10 分钟增加 30—50%。如以下 CloudWatch 指标图表所示,
kds-od-evitiant-spificant-spibint-spike
数据流会调整分片数量以应对摄取量的增加。
大约 15 分钟后,运行以下 亚马逊云科技 CLI 命令来查找 kds-od-evitiant-spifitiant-spi
k
e 数据流的 OpenShardCount 值 (x)。然后在数据流中发送 (x * 2) MB/s 的采集吞吐量,持续 2-3 分钟,并将采集吞吐量降低到之前的水平:
如以下 CloudWatch 指标图表所示,记录被限制了几分钟,然后限制就消失了。


通常,我们在举办计划中的活动(例如购物假期和产品发布会)时会面临显著的峰值情景。为了应对此类情况,我们可以主动将容量模式从按需更改为预配置。我们可以配置分片数量并选择我们预期的摄取容量。在预置容量模式下成功将分片数量扩展到所需的峰值容量后,我们可以将容量模式更改回按需模式。
场景 3:单个分区键开始推送超过 1 Mb/s
分区键用于隔离记录并将其路由到流的不同分片。分区键由数据创建器在向数据流中添加数据时指定。例如,假设我们有一个包含两个分片(分片 1 和分片 2)的流。我们可以将数据创建器配置为使用两个分区键(密钥 A 和密钥 B),以便将所有带有密钥 A 的记录添加到分片 1,并将所有带有密钥 B 的记录添加到分片 2。选择分区键是一个非常重要的决定,我们应该仔细选择分区键,以确保记录在流的所有分片上均匀分布。绑定到单个分区键 A 的消息将发送到单个分区(分区 1),并且在任何给定实例中,绑定到单个分区键 A 的消息都不能分布在不同的分片上。如前所述,默认情况下,一个分片支持 1 Mb/s 和 1,000 条记录/秒的写入,我们最终可能会遇到一个极端情况,即我们试图为特定的分区键推送超过 1 Mb/s 的速度。在这种情况下,制片人将继续受到限制,并无限期地继续重试。
要模拟场景,请运行以下 亚马逊云科技 CLI 命令以按需容
量模式创建 kds-od-partition-key-th
rottle 数据流:
如前所述,默认情况下,数据流最初将有四个分片,因为该数据流是在按需模式下创建的。当数据流处于活动状态时,我们会针对特定分区键 A 持续发送 1.5 Mb/s 的采集吞吐量。如以下 CloudWatch 指标图表所示,我们可以观察到,即使我们发送 1.5 Mb/s 的采集吞吐量,kds
-od-partition-key-
throttle 数据流的总摄取容量为 4 Mb/s。


为避免这种情况,我们应该谨慎选择分区键,并确保该特定分区键在数据流中持续发送的采集吞吐量不会超过 1 Mb/s。
在按需容量模式下将 Kinesis 数据流的采集容量扩展到 1 Gb/s
为了进行测试,我们首先以按需容量模式下 Kinesis Data Streams 的基准采集吞吐量约为 100 Mb/s,然后使用 Locust 负载测试工具每 5-10 分钟将采集吞吐量提高 30-50%。
要设置场景,请首先在预置容量模式下创建
kds-od-1gb-strea
m 数据流,并为预配置分片字段提供值 120:
当
kds-od-1gb-stream 数据流
处于活动状态时,将其容量模式切换到按需模式,如以下代码所示。当我们将容量模式从预置更改为按需容量模式时,即使在按需容量模式下,数据流的分片数 (120) 也保持不变。
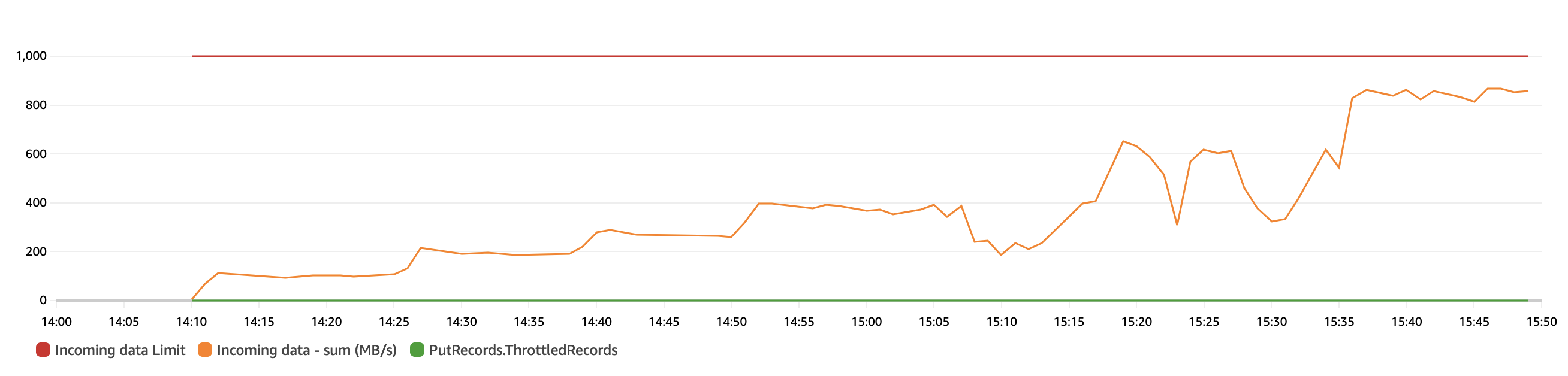
当
kds-od-1gb-stream 数据流
处于按需模式时,开始实验。我们使用 Locust 工具发送大约 100 Mb/s 的基准摄取吞吐量,每 5-10 分钟将摄取吞吐量提高 30-50%。如以下 CloudWatch 指标图表所示,
kds-od-1gb-stream 数据流在按需容量模式下无缝扩展到 1 Gb/s
。我们还可以观察到,当数据流以按需容量模式扩展时,生产者没有遇到任何写入限制。
清理
为了避免持续的成本,请使用 Kinesis Data Streams 控制台删除您在本文中创建的所有数据流。
结论
这篇文章通过使用最佳实践的一些场景演示了 Kinesis Data Streams 的按需扩展策略,并展示了如何在按需容量模式下将采集容量扩展到 1 Gb/s。您可以将按需写入吞吐量限制设置为比之前的 200 MB/s 限制高五倍。如果您使用未知工作负载创建新数据流、应用程序流量不可预测或不想管理容量,请选择按需模式。每 24 小时滚动周期内,您可以在按需和预置容量模式之间切换两次。请在评论部分留下任何反馈。
作者简介
 Nihar Sheth
是亚马逊网络服务亚马逊 Kinesis Data Streams 团队的高级产品经理。他热衷于开发直观的产品体验,以解决复杂的客户问题并帮助客户实现其业务目标。
Nihar Sheth
是亚马逊网络服务亚马逊 Kinesis Data Streams 团队的高级产品经理。他热衷于开发直观的产品体验,以解决复杂的客户问题并帮助客户实现其业务目标。
 Pratik Patel
是高级技术客户经理和流媒体分析专家。他与 亚马逊云科技 客户合作,提供持续的支持和技术指导,以使用最佳实践帮助规划和构建解决方案,并主动保持客户的 亚马逊云科技 环境运行健康。
Pratik Patel
是高级技术客户经理和流媒体分析专家。他与 亚马逊云科技 客户合作,提供持续的支持和技术指导,以使用最佳实践帮助规划和构建解决方案,并主动保持客户的 亚马逊云科技 环境运行健康。
 Nisha Dekhtawala 是一名
合作伙伴解决方案架构师和数据分析专家。她与全球咨询合作伙伴合作,成为他们值得信赖的顾问,为构建架构完善的创新行业解决方案提供技术指导和支持。
Nisha Dekhtawala 是一名
合作伙伴解决方案架构师和数据分析专家。她与全球咨询合作伙伴合作,成为他们值得信赖的顾问,为构建架构完善的创新行业解决方案提供技术指导和支持。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。