我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
利用计算机视觉和大型语言模型进行人工智能驱动的施工文档分析

AEC 行业和 AI 时代
在越来越多地采用人工智能和机器学习技术的推动下,建筑、工程和施工 (AEC) 行业正在经历数字化转型。处于这种演变的最前沿的是 TwinKnowledge,这是一家开创性的 AEC 人工智能公司,正在重新构想行业如何大规模设计和审查施工图纸。
在这篇博客文章中,我们将探讨 TwinKnowledge 如何与亚马逊云科技的原型设计和云工程(PACE)团队合作以克服一项关键挑战:在客户之间扩展计算机视觉(CV)平台,在几天之内高效处理数千张建筑图纸,同时保持高准确性。该解决方案结合了大型语言模型 (LLM) 和 CV 模型的强大功能,创建了人工智能增强的工作流程,显著增强了人工审查流程。
TwinKnowledge 的使命是利用人工智能增强人工审查流程,使 AEC 专业人员能够发现和纠正更多错误,从而减少施工文件中的错误并提高整体项目效率。但是,该公司面临可扩展性限制,这限制了他们实施更广泛的生成式人工智能战略的能力。通过利用 Amazon SageMaker 的 MLOps 功能并建立强大的数据采集和验证管道,亚马逊云科技 PACE 团队帮助 TwinKnowledge 突破了这些限制。
我们将详细介绍该解决方案如何不仅解决了眼前的扩展挑战,还为增强的搜索能力和人工智能驱动的见解奠定了基础。通过本次技术深入研究,您将了解如何编排亚马逊云科技服务以创建强大、可扩展的 AI 解决方案,以增强而不是取而代之的专业知识。
行业的信息问题
今天,二维绘图集已成为建筑的真实来源。它们是项目设计工作的综合体,由建筑师组成,移交给总承包商,供现场使用,构成项目执行的基础。在该领域,略超过 70% 的行业仍在使用它们的原始形式:作为纸质蓝图(参见 "BlueBuilding the Future:2025 年 Bluebeam AEC 技术展望",Blubeam)。这些设计文件是建筑项目的直接风险来源。为了降低这种风险,各公司努力通过控制措施来监管这些设计,例如从过去的项目中吸取的经验教训、详细的范围文件、要求和标准文件以及旨在正确处理问题的广泛协调。公司任命质量保证(QA)/质量控制(QC)主管和审查员小组,以确保文件质量。尽管有这些审阅者,但这些文档(通常长达数千页)通常包含不合规、设计错误以及缺少关键设计决策和设计细节。
根据 Plangrid-FMI 联合发布的行业报告《施工断开连接》,近四分之一的建筑返工是由不正确或隐藏的项目信息造成的(22%),每年给美国建筑业造成超过 143 亿美元的损失。这些信息中的大部分存储在 PDF 文件中,包括书面合同文档、信息请求,最重要的是绘图集。该报告进一步表明,AEC 专业人员的支出:
- 每周 5.5 小时搜索项目数据
- 每周 5 小时解决与信息相关的冲突
- 每周 4 小时解决错误和返工
这相当于每周总共有 14.5 小时与信息问题相关的本可避免的工作。
这些问题对该行业来说并不是什么新鲜事物。二维图纸集一直是施工的标准,但是 AEC 行业正处于停滞状态,其目前的员工队伍和项目情报系统对图纸集执行 QA/QC 的能力。关键的劳动力过渡加剧了这一挑战:根据国家建筑教育与研究中心的文章《熟练劳动力:卷土重来的故事》,预计到 2031 年将有 41% 的建筑专业人员退休,他们将拥有数十年的隐性设计知识。
TwinKnowledge 是一家应用人工智能从施工文档中挖掘宝贵见解并检测图纸集错误的公司,该公司认识到了通过将人工智能能力与 AEC 专业人员的专业知识相结合来扩展能力和加强图纸质量保证/质量控制审查来应对这一挑战的机会。
他们的方法将 LLM 与 CV 相结合,创建了一个全面的系统,将绘图集中的设计信息映射到其预期的设计驱动因素:经验教训、要求和标准。这种集成需要处理并将文本和图形设计信息合并到一个单一的知识库中,供 LLMs 进行分析。
但是,事实证明,现成的多模态人工智能模型不足以处理图形信息。图形信息的处理方式必须能够以审阅者认为合理的方式(例如绘图集的结构)进行组织、访问和呈现给审阅者。这意味着根据绘图集中的信息的结构来解析和处理图形信息:例如引用细节的平面图视图,参考时间表绘制细节,以及带有自己的参考的时间表。
为此,TwinKnowledge 建立了一个专有数据管道,该管道首先将绘图集信息与文本信息分开,然后使用内部简历模型解析原始格式的绘图集。但是,绘图集结构的视觉方向和表示方式因项目而异。为了解决这个问题,TwinKnowledge 对每个公司的基本简历模型和每个项目的图纸集进行了微调,在逐个项目的基础上提供接近人类水平的信息理解能力。
该解决方案虽然有效,但却揭示了一个新的挑战:需要在 TwinKnowledge 快速扩大的客户群中扩展和实施微调流程。由于他们的客户组合预计在短期内将翻一番,他们需要一个有效的解决方案来扩展其 AEC 行业的项目人工智能能力。为此,他们求助于亚马逊云科技 PACE 团队。
TwinKnowledge 解决方案扩展声明
所有施工图纸的背后都隐藏着一个看不见的知识网络——经验教训、标准、协调和依赖关系——一个由设计驱动因素组成的系统和构成项目真实信息来源的实际设计。当前的行业惯例包括对该系统内的合规性进行抽查,这种方法导致效率低下,每年给该行业造成数十亿美元的损失。尽管人工审阅者擅长合规性评估所需的批判性思维,但他们面临两个关键限制:
- 需要处理大量的项目信息
- 促进设计合规性映射的项目信息系统不足
相比之下,LLM 擅长处理和存储大量文本数据,以实现近乎即时的访问。TwinKnowledge 的解决方案将经过专门训练的简历模型与 LLM 相结合,将图形信息从绘图集合分块并转换为文本数据,同时保留其原始结构和关联。通过这种方式,TwinKnowledge 利用 LLM 将项目中的所有文本和图形设计信息嵌入到同一个高维矢量空间中,从而使 LLM 可以随时访问互联信息。TwinKnowledge 的 LLM 已经根据构造语言进行了微调,然后可以找到设计驱动信息并将其与绘图集中的设计图形(即细节)联系起来。有了 TwinKnowledge,这可以在 100% 的覆盖水平上完成,与当前行业标准的抽查系统相比,这是一个显著的改进。
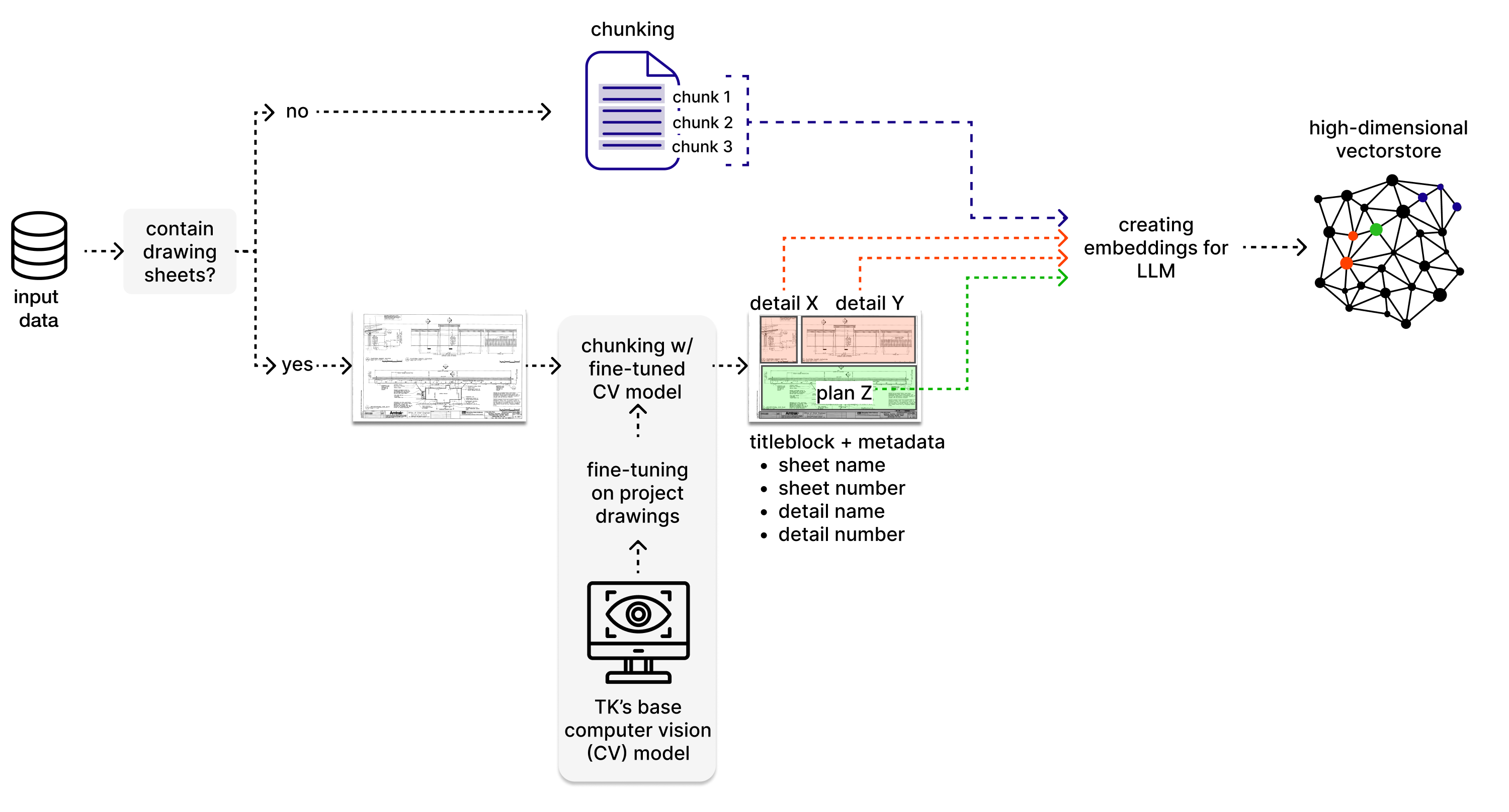
TwinKnowledge 用于分块和嵌入项目信息的管道
上图显示了 TwinKnowledge 用于分块和嵌入项目信息的两个不同管道:用于文档分析的文本处理管道和用于绘图集处理的简历流水线。流水线包括提取绘图集结构信息(例如图纸名称和编号、标题栏中的最新日期、视图/详细信息/时间表标题,甚至页面上信息的物理边界)的过程,并将这些信息存储为元数据。
为了有效地为每个客户和每个项目扩展该解决方案,TwinKnowledge 聘请了亚马逊云科技 PACE 团队设计了可扩展的软件架构。重点集中在扩展三个关键方面:
- 处理标记图纸集信息,例如 "细节"、"细节标题" 和 "标题栏"
- 基于通用 CV 模型的训练工作流程
- 针对特定客户的 CV 模型执行推理
该团队的长期目标是实施全面的端到端 MLOps 管道,以简化 AEC 文档处理的整个机器学习生命周期(有关深度管道架构,请参阅 "亚马逊云科技峰会 ANZ 2022 — 架构师端到端 MLOP")。该管道将包括三个关键组件:数据摄取和标签、模型训练和推理工作流程。通过集成这些组件,TwinKnowledge-亚马逊云科技团队旨在创建一个无缝流程,以提高效率,确保数据质量并加速模型开发和部署。
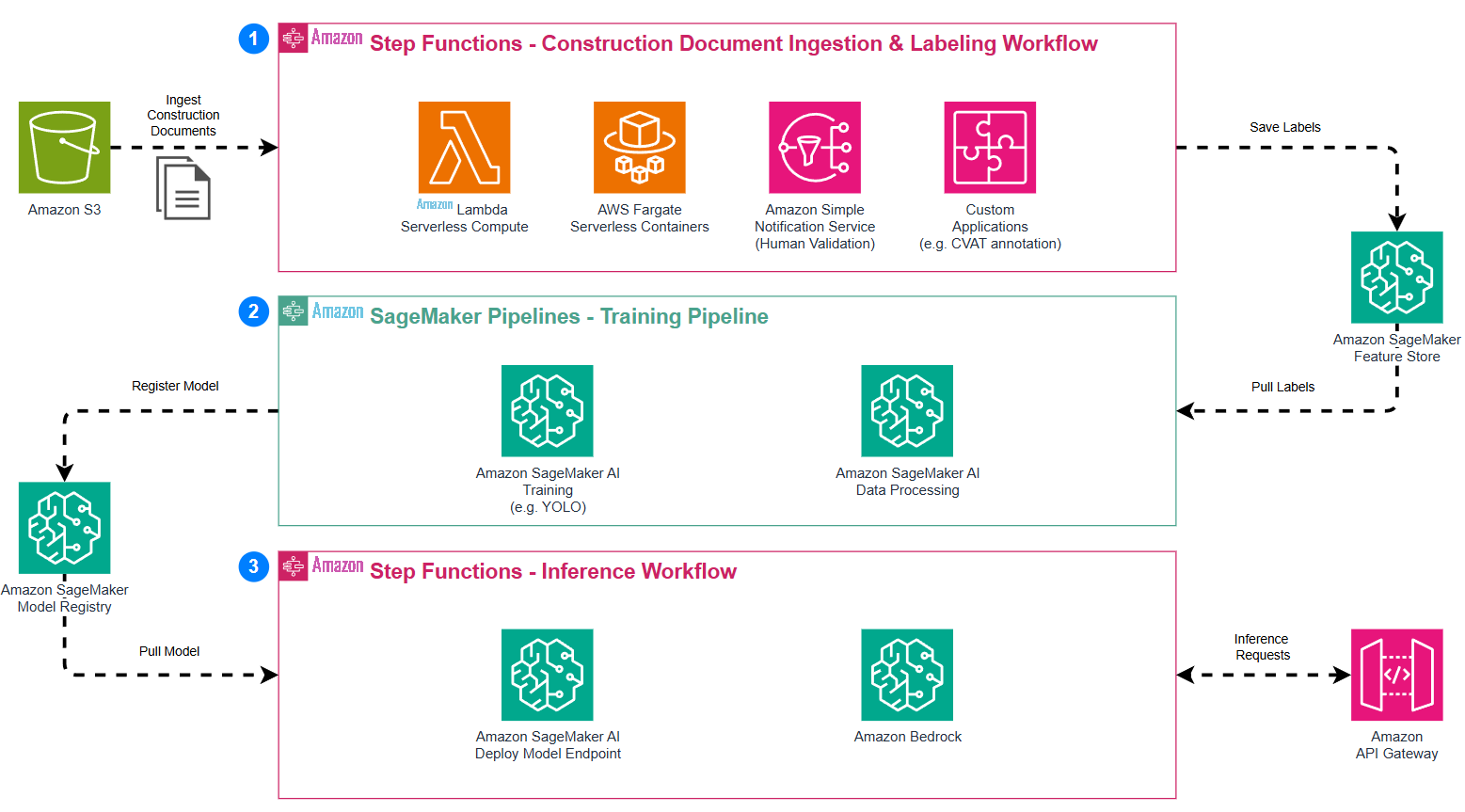
端到端 MLOps 管道的架构图
上图说明了设想的 MLOps 管道的高级架构:
- 施工文件摄取和标签:这个初始阶段涉及收集、处理和标记 AEC 文档和图纸。
- 训练管道:使用准备好的数据开发、训练和验证机器学习模型。
- 推理工作流程:部署经过训练的模型以实时分析新的 AEC 文档的最后阶段。
亚马逊云科技 PACE 原型的扩展概述
任何成功的机器学习项目的基础都在于组织良好的高质量数据。在 AEC 文件处理的背景下,这尤其重要,因为施工图纸和文档的性质多种多样。数据摄取和标签工作流程旨在通过智能自动化和强大的组织来应对这些挑战。
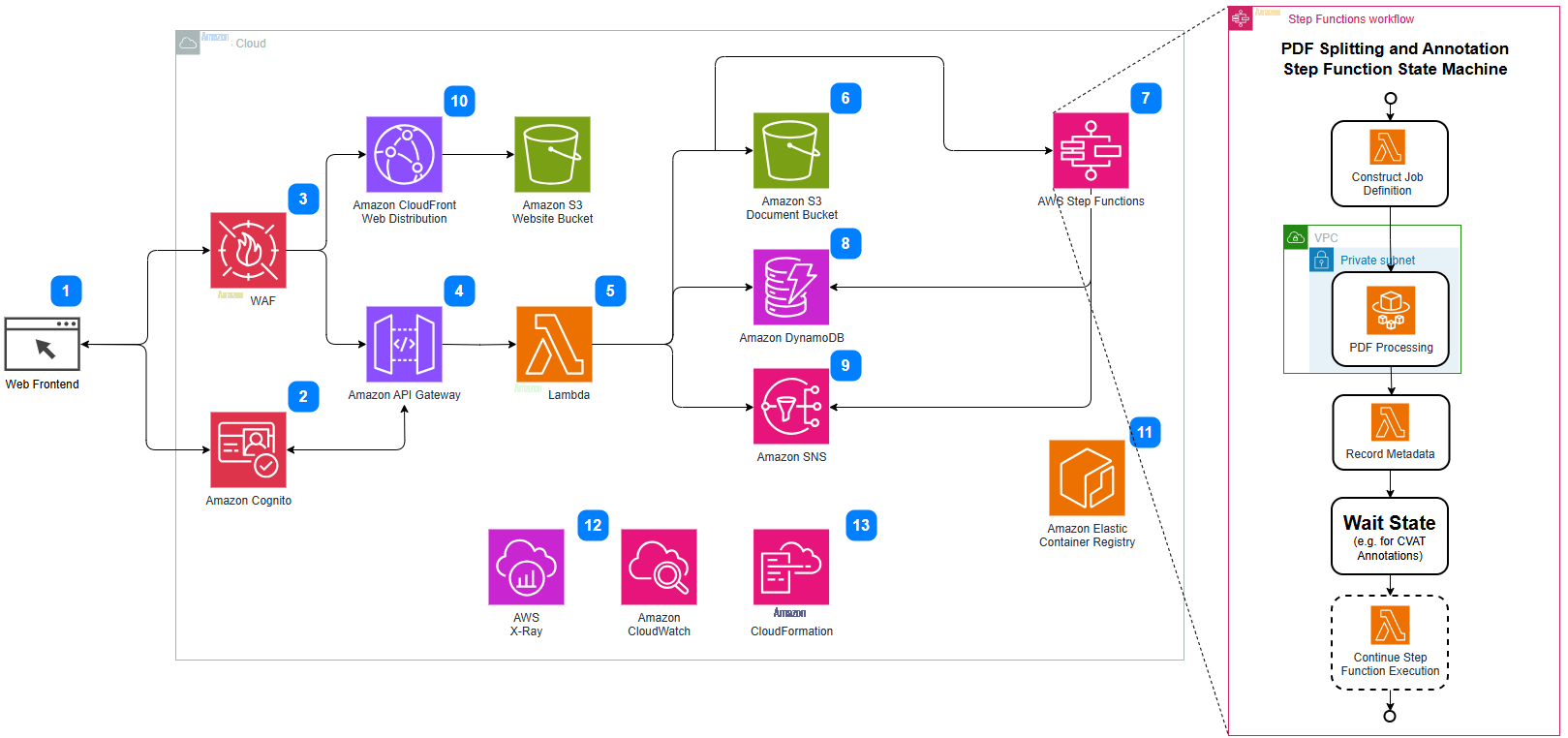
用于数据提取和标签的亚马逊云科技架构图
我们的数据采集和标签流程架构利用多项亚马逊云科技服务来确保效率和可扩展性:
- 用户可以通过 Web 前端上传施工文档并触发处理管道。
- Amazon Cognito 用于在网络应用程序中对用户进行身份验证。
- Amazon Web 应用程序防火墙 (WAF) 使用托管规则集保护 Web 应用程序免受常见攻击。
- Amazon API Gateway 用于创建和管理 REST API 资源和方法,以及与 Amazon Lambda 的通信。
- Amazon Lambda 提供无服务器计算资源并促进与其他服务之间的通信。
- Amazon Simple Storage Service(Amazon S3)存储上传的数据和从文档中提取的图像。
- 当新的构造文档集上传到 S3 时,Amazon Step Functions 状态机就会启动。Amazon Fargate 集群在 Amazon Virtual Private Cloud 私有子网内执行文档分页和图像生成任务。
- Amazon DynamoDB 存储有关每个施工文件处理项目的元数据。
- Amazon Simple Notification Service(Amazon SNS)向用户发送通知,让他们知道管道已完成。
- Amazon CloudFront 用于分发 React 前端 Web 应用程序。
- Amazon Elastic Container Registry (ECR) 用于存储用于管道的 Docker 容器镜像。
- Amazon X-Ray 和 Amazon CloudWatch 用于跟踪和监控。
- Amazon CloudFormation 用于将资源部署为基础设施即代码 (IaC)。
通过自动执行数据采集和标签的关键方面,显著减少了为机器学习准备 AEC 文档所需的时间和精力。这种方法不仅可以加快开发周期,还可以确保数据准备的一致性,从而实现更可靠的模型训练和更好的推理结果。
在此工作流程中强调数据组织可以更轻松地进行数据版本控制、实验跟踪和模型谱系,这对于在动态 AEC 行业中随着时间的推移维护和改进机器学习模型至关重要。
结论
通过此次合作,我们展示了如何将亚马逊云科技服务与创新的 MLOps 实践相结合,可以改变 AEC 行业的文档处理工作流程,并帮助扩展行业转型的人工智能。该解决方案不仅解决了 TwinKnowledge 眼前的挑战,还为未来的人工智能能力奠定了坚实的基础。
此实施的关键要点包括:
- 将 MLOp 优秀实践与 Amazon SageMaker 整合以创建可持续、可扩展的人工智能解决方案的力量
- 人工智能增强的工作流程如何增强而不是取代文档审查流程中的人类专业知识
- 构建可以随着人工智能技术的进步而发展的灵活架构的重要性
随着 AEC 行业继续数字化并采用人工智能技术,像 TwinKnowledge 平台这样的解决方案将在推动效率和创新方面发挥越来越重要的作用。该解决方案的成功部署仅仅是将领域专业知识与亚马逊云科技全面的机器学习能力相结合的可能性的开始。
要详细了解亚马逊云科技如何支持您组织的 AI 计划或探索类似的解决方案,请联系您的亚马逊云科技账户团队或访问亚马逊云科技解决方案库。

亚当·切尔尼克
Adam 是亚马逊云科技的高级空间计算原型设计架构师,专注于 AR/VR/数字双胞胎和新兴技术。亚当此前曾领导 ShoP 建筑师事务所的 AEC/房地产行业的应用研究小组。他经常在麻省理工学院、耶鲁大学和哥伦比亚大学等会议和大学发表演讲。他的申请曾获得奖项提名,曾在博物馆展出,并在《纽约时报》等出版物中发表过文章。

卢克·里夫
卢克·里夫是 TwinKnowledge 的首席解决方案架构师,该公司牵头为 AECO 行业开发人工智能项目情报。在加入 TwinKnowledge 之前,Luke 曾在全国获奖的设计公司 Uzun+Case 担任结构工程师,并就读于哈佛大学设计研究生院,探索人工智能重塑人类信息交互未来的变革潜力。

斯科特·帕顿
Scott Patten 是亚马逊云科技的高级空间计算原型设计架构师,他为客户提供空间计算云解决方案。在加入亚马逊云科技之前,Scott 曾担任 XR 开发人员、Web 开发人员和潜艇海军建筑师。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。