我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 SageMaker Canvas 通过无代码机器学习实现有效的业务成果
2021 年 11 月 30 日,我们
机器学习在各行各业的组织中变得无处不在,可以利用现有数据的预测快速准确地收集有价值的业务见解。扩大机器学习使用范围的关键是使其更易于使用。这意味着让业务分析师能够在不依赖数据科学团队的情况下自行使用机器学习。Canvas 可帮助业务分析师将机器学习应用于常见的业务问题,而无需知道算法类型、训练参数或集成逻辑等细节。如今,客户正在使用Canvas来解决垂直领域的各种用例,包括流失检测、销售转化率和时间序列预测。
在这篇文章中,我们讨论了 Canvas 的关键功能。
开始使用 Canvas
Canvas 提供交互式导览,可帮助您浏览可视化界面,首先是从云端或本地源导入数据。Canvas入门很快;我们为多个用例提供了示例数据集,包括预测客户流失、估计贷款违约概率、预测需求和预测供应链交付时间。这些数据集涵盖了 Canvas 目前支持的所有用例,包括二元分类、多类分类、回归和时间序列预测。要了解有关浏览 Canvas 和使用示例数据集的更多信息,请参阅
探索性数据分析
导入数据后,Canvas允许您在构建预测模型之前对其进行探索和分析。您可以预览导入的数据并可视化不同要素的分布。然后,你可以选择转换数据,使其适合解决你的问题。例如,您可以选择删除列、提取日期和时间、估算缺失值或使用标准值或自定义值替换异常值。这些活动记录在模型
配方
中 ,这是数据准备的一系列步骤。从数据准备到生成预测,在特定 ML 模型的整个生命周期中,该方法都会得到维护。参见
可视化您的数据
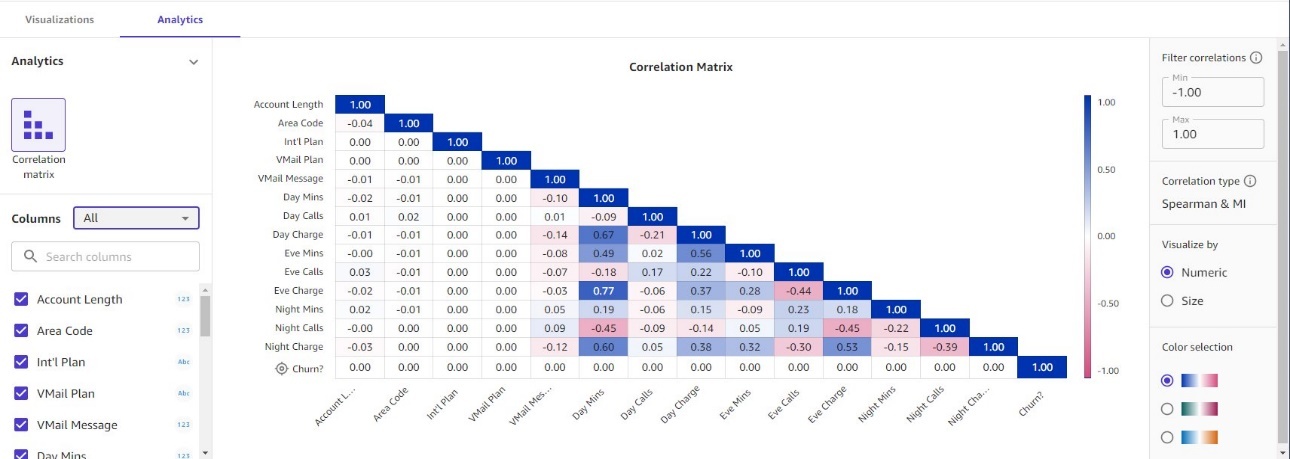
Canvas 还提供了通过数学运算符和逻辑函数在数据中定义和创建新特征的能力。通过将要素直接拖放到图表上,您可以通过箱线图、条形图和散点图来可视化和浏览数据。此外,Canvas 还为数值和类别变量提供关联矩阵,以了解数据中特征之间的关系。这些信息可用于优化您的输入数据并生成更准确的模型。有关 Canvas 中数据分析功能的更多详细信息,请参阅
在准备和浏览数据后,Canvas 为你提供了验证数据集的选项,这样你就可以主动检查数据质量问题。Canvas 代表您验证数据,并出现诸如任何行或列中缺少值以及目标列中与行数相比的唯一标签过多等问题。此外,Canvas 还为您提供了在构建 ML 模型之前修复这些问题的选项。要更深入地了解数据验证功能,请参阅使用 Am
构建 ML 模型
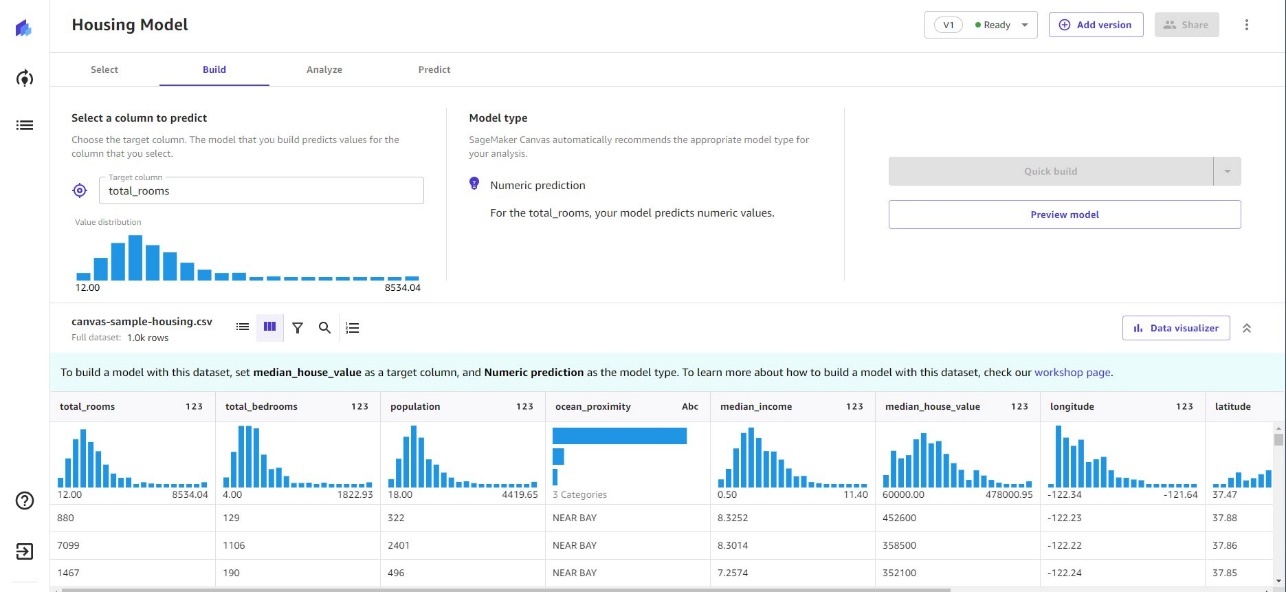
在 Canvas 中构建 ML 模型的第一步是定义问题的目标列。例如,您可以选择房间总数作为目标列来确定住房模型中的房价。或者,您可以使用流失率作为目标列来确定在不同条件下流失客户的概率。选择目标列后,Canvas 会自动确定要构建的模型的问题类型。
在构建 ML 模型之前,您可以通过运行预览分析,从方向上了解模型的估计精度以及每项功能如何影响结果。基于这些见解,您可以进一步准备、分析或探索数据,以获得所需的模型预测精度。
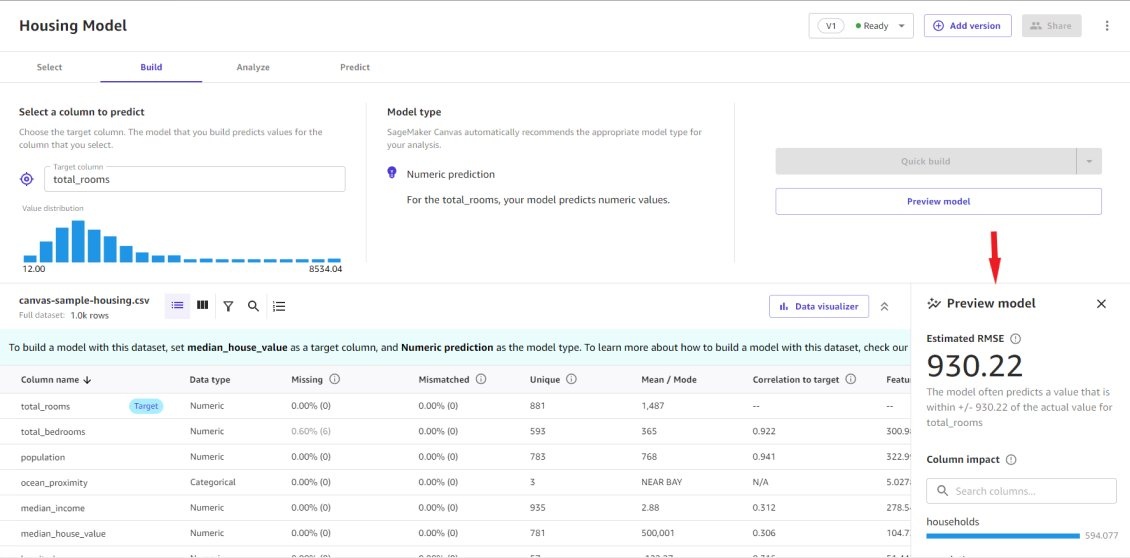
Canvas 提供了两种训练机器学习模型的方法: 快速构建 和 标准构建 。这两种方法都提供了经过全面训练的机器学习模型,该模型完全透明,可以了解每个特征对模型结果的重要性。Quick build 侧重于速度和实验,而标准构建则侧重于通过多次迭代数据预处理、选择正确的算法、探索超参数空间以及生成多个候选模型,然后选择性能最佳的模型,来实现最高的准确性。此过程由 Canvas 在幕后完成,无需编写代码。
新的性能改进可将机器学习模型训练时间缩短多达三倍,从而实现快速原型设计并缩短业务成果实现价值的时间。要了解更多信息,请参阅
模型分析
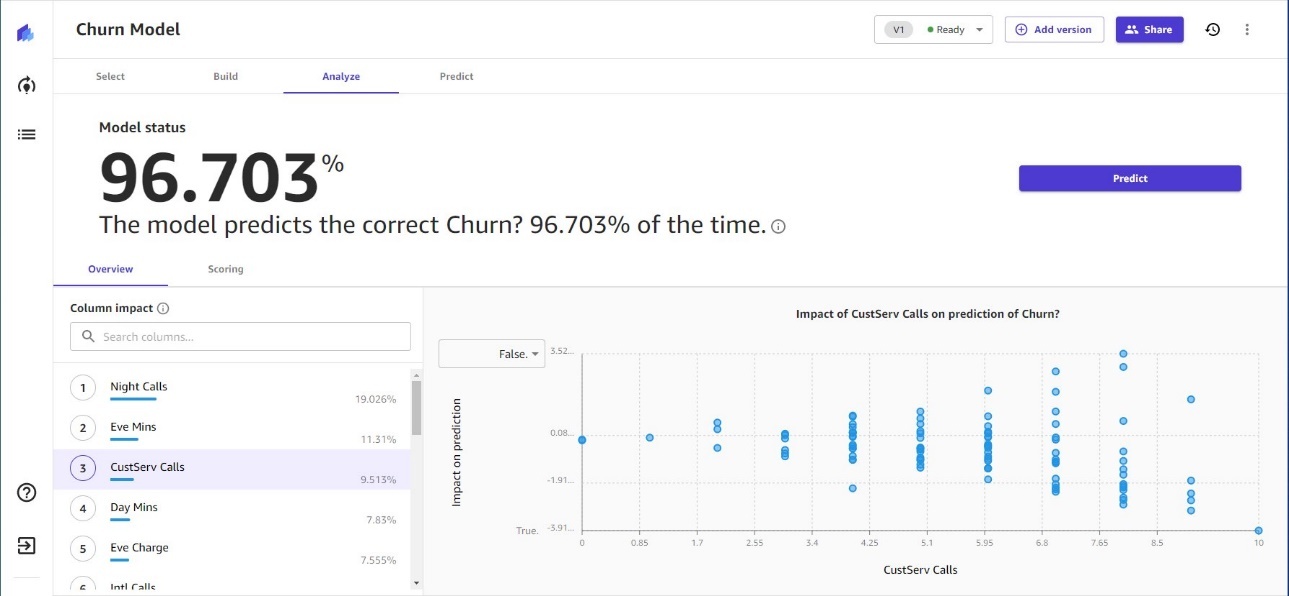
构建模型后,Canvas 会提供详细的模型精度指标和特征可解释性。
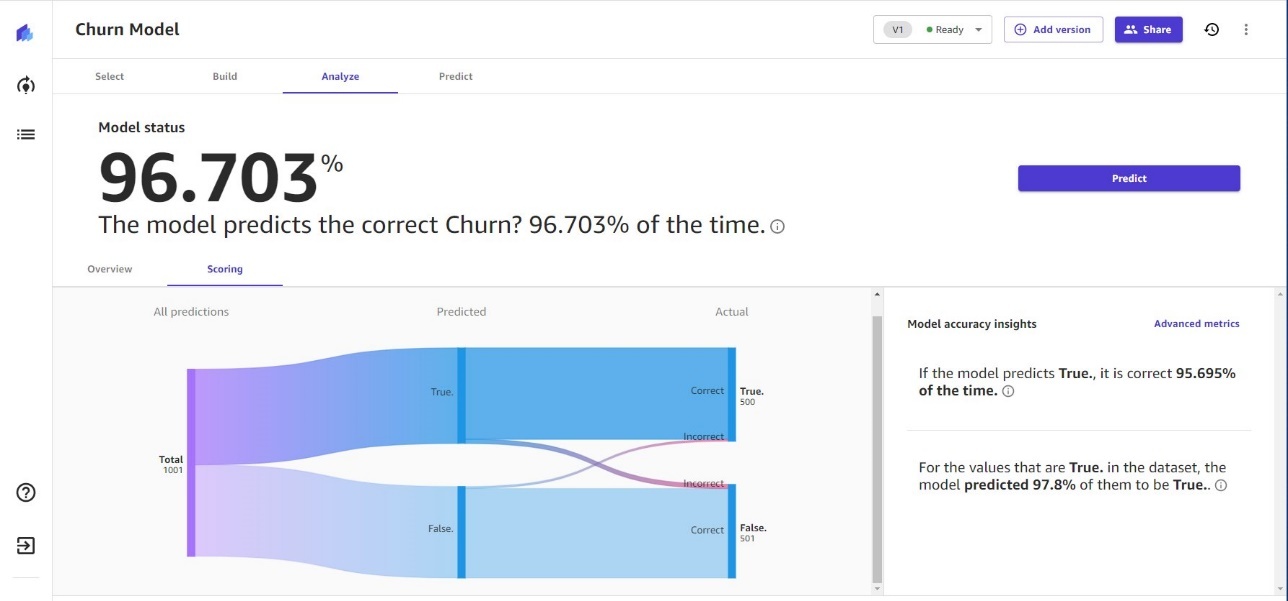
Canvas还提供了一张Sankey图表,描述了数据从一个值流向另一个值,包括误报和假阴性。
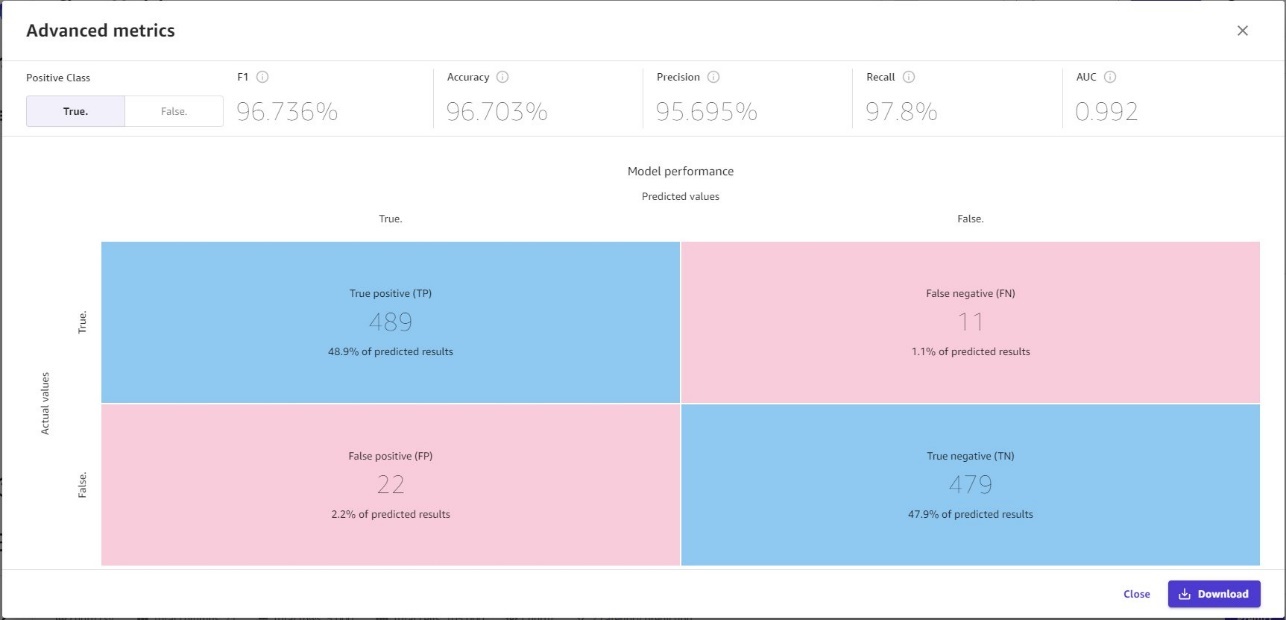
对于有兴趣分析更高级指标的用户,Canvas 提供结合了精度和召回率的 F1 分数、量化模型在整个数据集中做出正确预测的次数的准确度指标,以及用于衡量模型在数据集中区分类别的效果的曲线下区域 (AUC)。
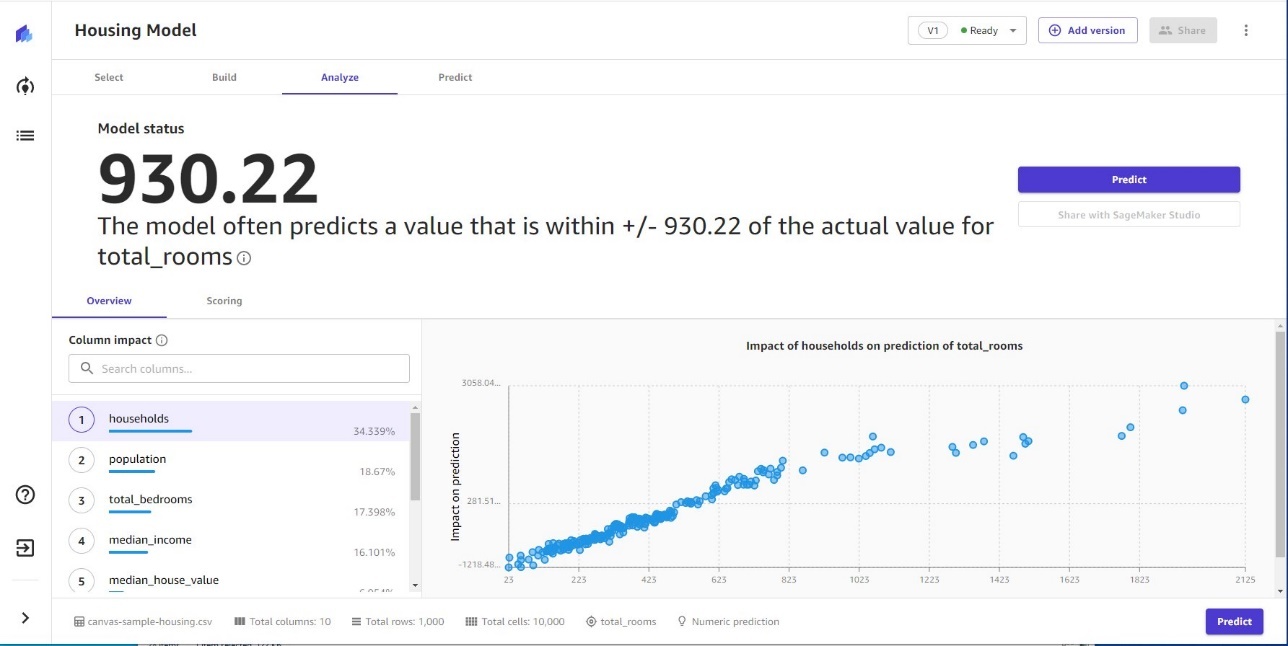
模型预测
使用Canvas,您可以通过分析不同特征值对模型准确性的影响,通过交互式假设分析,对经过训练的模型进行实时预测。
此外,您可以对任何验证数据集进行整体批量预测。可以预览和下载这些预测以供下游应用程序使用。
共享和协作
Canvas 允许您与数据科学团队共享模型以进行审查、反馈和更新,从而继续机器学习之旅。您可以使用

此外,数据科学家可以与Canvas用户共享在
结论
立即开始使用 Canvas,利用机器学习来实现业务成果,而无需编写一行代码。从 C
作者简介
 Shyam Srinivasan
是 亚马逊云科技 低代码/无代码机器学习产品团队的成员。他关心通过科技让世界变得更美好,也喜欢参与这段旅程。在业余时间,夏姆喜欢长途奔跑、环游世界以及与家人和朋友一起体验新文化。
Shyam Srinivasan
是 亚马逊云科技 低代码/无代码机器学习产品团队的成员。他关心通过科技让世界变得更美好,也喜欢参与这段旅程。在业余时间,夏姆喜欢长途奔跑、环游世界以及与家人和朋友一起体验新文化。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。