我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 DeepSpeed 加速 PyTorch,使用基于英特尔哈瓦那高迪的 DL1 EC2 实例训练大型语言模型
训练具有数十亿个参数的大型语言模型 (LLM) 可能具有挑战性。除了设计模型架构外,研究人员还需要为分布式训练设置最先进的训练技术,例如混合精度支持、梯度累积和检查点。对于大型模型,训练设置更具挑战性,因为单个加速器设备中的可用内存限制了仅使用数据并行度训练的模型的大小,并且使用模型并行训练需要对训练代码进行额外的修改。诸如
在这篇文章中,我们对基于英特尔哈瓦那高迪的
训练设置
分布式培训研讨会说明了设置分布式训练集群的步骤。研讨会展示了使用 亚马逊云科技 Batch 的分布式训练设置,尤其是在完全托管的集群上启动大规模容器化训练任务的多节点并行任务功能。更具体地说,使用 DL1 实例创建了一个完全托管的 亚马逊云科技 Batch 计算环境。容器从
使用 DeepSpeed 进行预训练
Habana
所有这些功能都在 B
预训练(第 1 阶段)扩展结果
对于大规模预训练大型模型,我们主要关注解决方案的两个方面:训练性能(以训练时间衡量)和达成完全融合解决方案的成本效益。接下来,我们以 BERT 1.5B 预训练为例,深入研究这两个指标。
扩展性能和训练时间
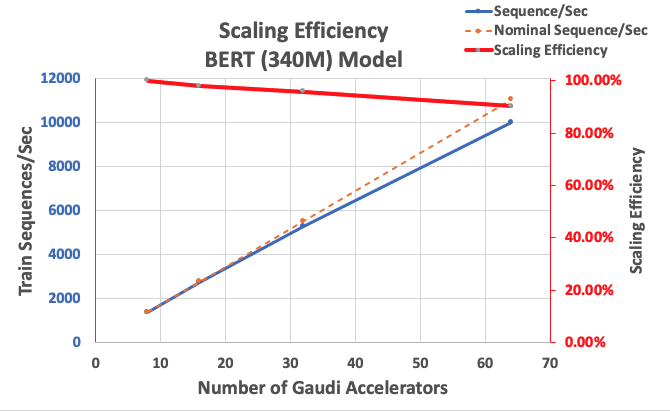
我们首先衡量 BERT Large 实现的性能,以此作为可扩展性的基准。下表列出了从 1-8 个 dl1.24xlarge 实例(每个实例有八个加速器设备)测得的每秒序列吞吐量。我们使用单实例吞吐量作为基准,测量了跨多个实例扩展的效率,这是理解性价比训练指标的重要杠杆。
| Number of Instances | Number of Accelerators | Sequences per Second | Sequences per Second per Accelerator | Scaling Efficiency |
| 1 | 8 | 1,379.76 | 172.47 | 100.0% |
| 2 | 16 | 2,705.57 | 169.10 | 98.04% |
| 4 | 32 | 5,291.58 | 165.36 | 95.88% |
| 8 | 64 | 9,977.54 | 155.90 | 90.39% |
下图说明了扩展效率。
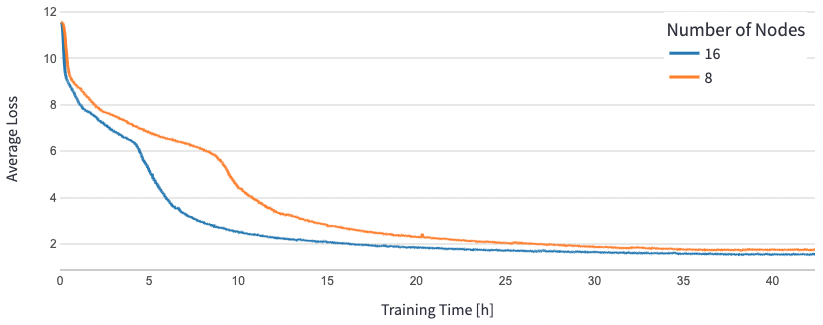
对于 BERT 1.5B,我们在参考存储库中修改了模型的超参数以保证收敛。每个加速器的有效批次大小设置为 384(以实现最大内存利用率),微批次为每步 16 个,梯度累积为 24 步。8 个和 16 个节点分别使用了 0.0015 和 0.003 的学习率。通过这些配置,我们在大约 25 小时内在 8 个 dl1.24xlarge 实例(64 个加速器)上实现了 BERT 1.5B 第 1 阶段预训练的趋同,在 16 个 dl1.24xlarge 实例(128 个加速器)上实现了 15 小时的收敛。下图显示了当我们扩大加速器数量时,平均损失与训练周期数的函数。
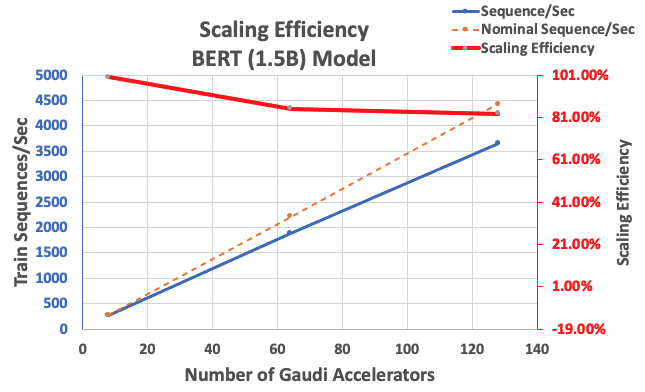
通过前面描述的配置,我们在单个实例中使用 8 个加速器获得了 85% 的强扩展效率,使用 128 个加速器获得了 83% 的强扩展效率。下表汇总了这些参数。
| Number of Instances | Number of Accelerators | Sequences per Second | Sequences per Second per Accelerator | Scaling Efficiency |
| 1 | 8 | 276.66 | 34.58 | 100.0% |
| 8 | 64 | 1,883.63 | 29.43 | 85.1% |
| 16 | 128 | 3,659.15 | 28.59 | 82.7% |
下图说明了扩展效率。
结论
在这篇文章中,我们评估了哈瓦那 SynapseAI v1.5/v1.6 对 DeepSpeed 的支持,以及它如何帮助在哈瓦那高迪加速器上扩展 LLM 训练。15亿个参数的BERT模型的预训练花了16个小时才汇聚到由128个高迪加速器组成的集群上,扩展能力强度为85%。我们鼓励您看看 A
作者简介




 Pierre-Yves Aquilanti
是亚马逊网络服务框架机器学习解决方案主管,他帮助开发业界最好的基于云的机器学习框架解决方案。他的背景是高性能计算,在加入 亚马逊云科技 之前,Pierre-Yves 曾在石油和天然气行业工作。Pierre-Yves 来自法国,拥有里尔大学计算机科学博士学位。
Pierre-Yves Aquilanti
是亚马逊网络服务框架机器学习解决方案主管,他帮助开发业界最好的基于云的机器学习框架解决方案。他的背景是高性能计算,在加入 亚马逊云科技 之前,Pierre-Yves 曾在石油和天然气行业工作。Pierre-Yves 来自法国,拥有里尔大学计算机科学博士学位。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。