我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用配备 Apache Iceberg 的亚马逊 Athena 加速交易数据湖上的数据科学特征工程
结合雅典娜的功能,Apache Iceberg 为数据科学家提供了简化的工作流程,无需复制或重新创建整个数据集即可创建新的数据功能。您可以在 Athena 上使用标准 SQL 创建功能,而无需使用任何其他服务进行功能工程。数据科学家可以减少准备和复制数据集所花费的时间,转而专注于数据特征工程、实验和大规模数据分析。
在这篇文章中,我们回顾了使用具有 Apache Iceberg 开放表格式的 Athena 的好处,以及它如何简化数据科学家的常见特征工程任务。我们将演示 Athena 如何转换 Apache Iceberg 格式的现有表,然后在不重新创建或复制数据集的情况下添加列、删除列和修改表中的数据,并使用这些功能在 Apache Iceberg 表上创建新功能。
解决方案概述
数据科学家通常习惯于处理大型数据集。数据集通常以 JSON、CSV、ORC 或
雅典娜引入了
Athena Iceberg UPDATE 操作在同一事务中将 Apache Iceberg 位置删除文件和新更新的行写入数据文件。您可以通过单个 UPDATE 语句对记录进行更正。
随着 Athena 引擎版本 3 的发布,Apache Iceberg 表的功能得到了增强,支持诸如
先决条件
使用雅典娜引擎版本 3 设置雅典娜工作组,以便在 Apache Iceberg 表中使用 CTAS 和 MERGE 命令。要将现有 Athena 引擎升级到 Athena 工作组中的版本 3,请按照
数据集
为了进行演示,我们使用了一个 Apache Parquet 表,该表包含过去几年中存储在 S3 存储桶中的数百万条随机分布的虚拟销售数据记录。
s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/
。
下表显示了
customer_
orders 表格的布局。
| Column Name | Data Type | Description |
| orderkey | string | Order number for the order |
| custkey | string | Customer identification number |
| orderstatus | string | Status of the order |
| totalprice | string | Total price of the order |
| orderdate | string | Date of the order |
| orderpriority | string | Priority of the order |
| clerk | string | Name of the clerk who processed the order |
| shippriority | string | Priority on the shipping |
| name | string | Customer name |
| address | string | Customer address |
| nationkey | string | Customer nation key |
| phone | string | Customer phone number |
| acctbal | string | Customer account balance |
| mktsegment | string | Customer market segment |
进行功能工程
作为数据科学家,我们希望通过将计算得出的每位客户的一年总购买量和现有数据 集中每位客户的一年平均购买量相加来对客户订单数据进行
ampledb 数据库中创建了 customer_ord
ers 表,如以下 DDL 命令
所示。(您可以使用任何现有的数据集并按照本文中提到的步骤进行操作。)
customer_order
s 数据集以 Parquet 格式生成并存储在 S3 存储桶位置
s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/
中。这张桌子不是 Apache Iceberg 牌桌。
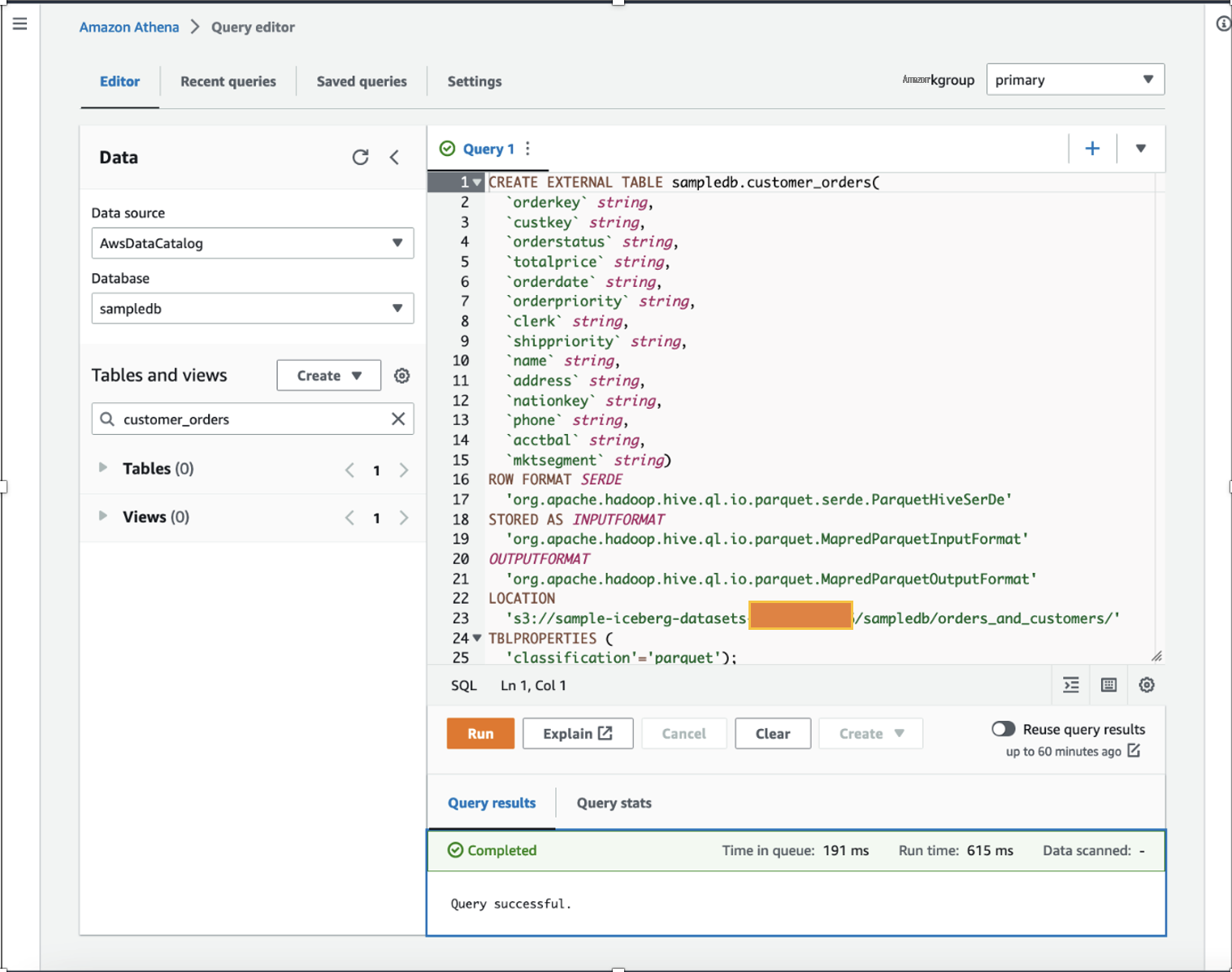
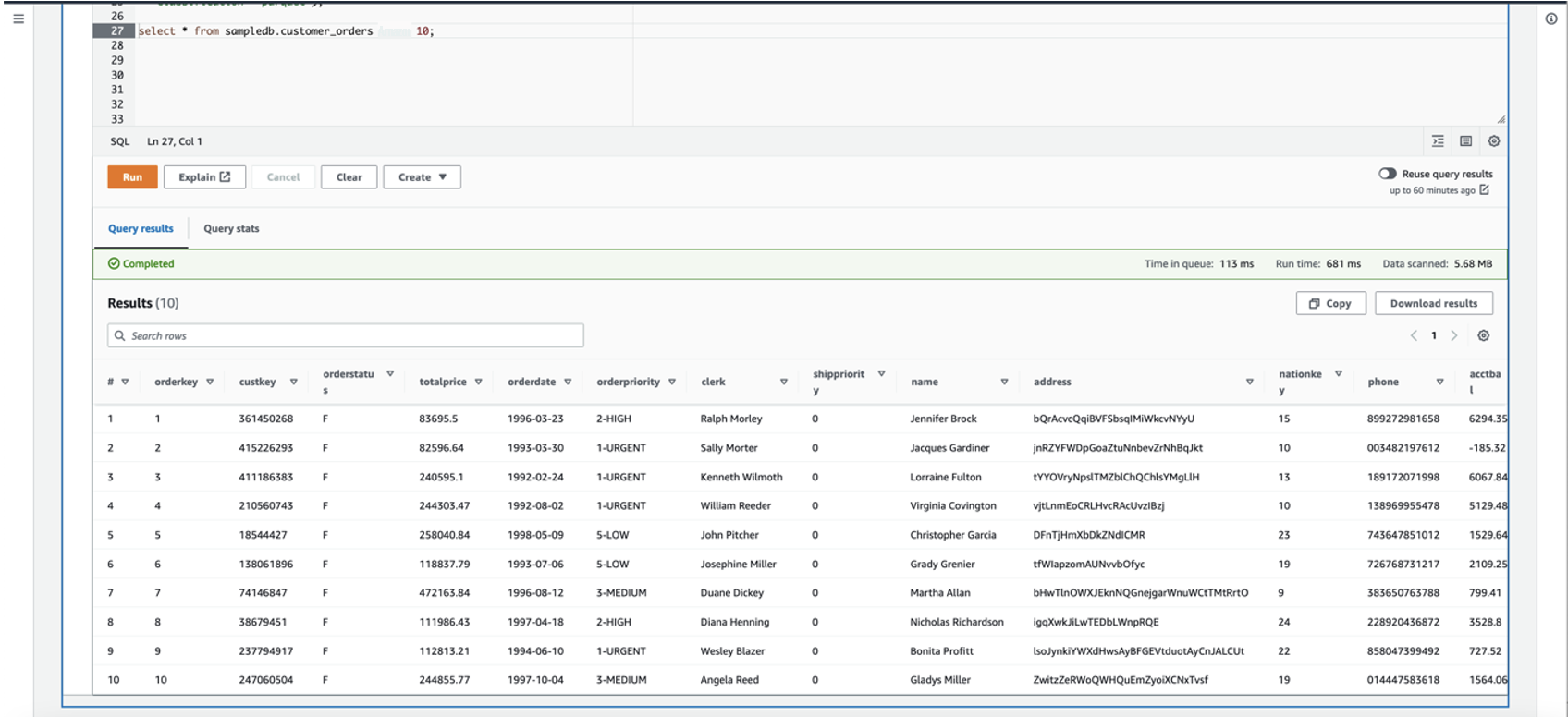
通过运行查询来验证表中的数据:
我们希望在此表格中添加新功能,以更深入地了解客户销售情况,从而加快模型训练速度并获得更多有价值的见解。要向数据集添加新功能,请将 c
ustomer_
orders 雅典娜表转换为 雅典娜上的 Apache Iceberg 表。
发出
在这样做的同时,还添加了一项新功能,用于获取每位客户在过去一年(数据集的最大年份)中的总购买金额。
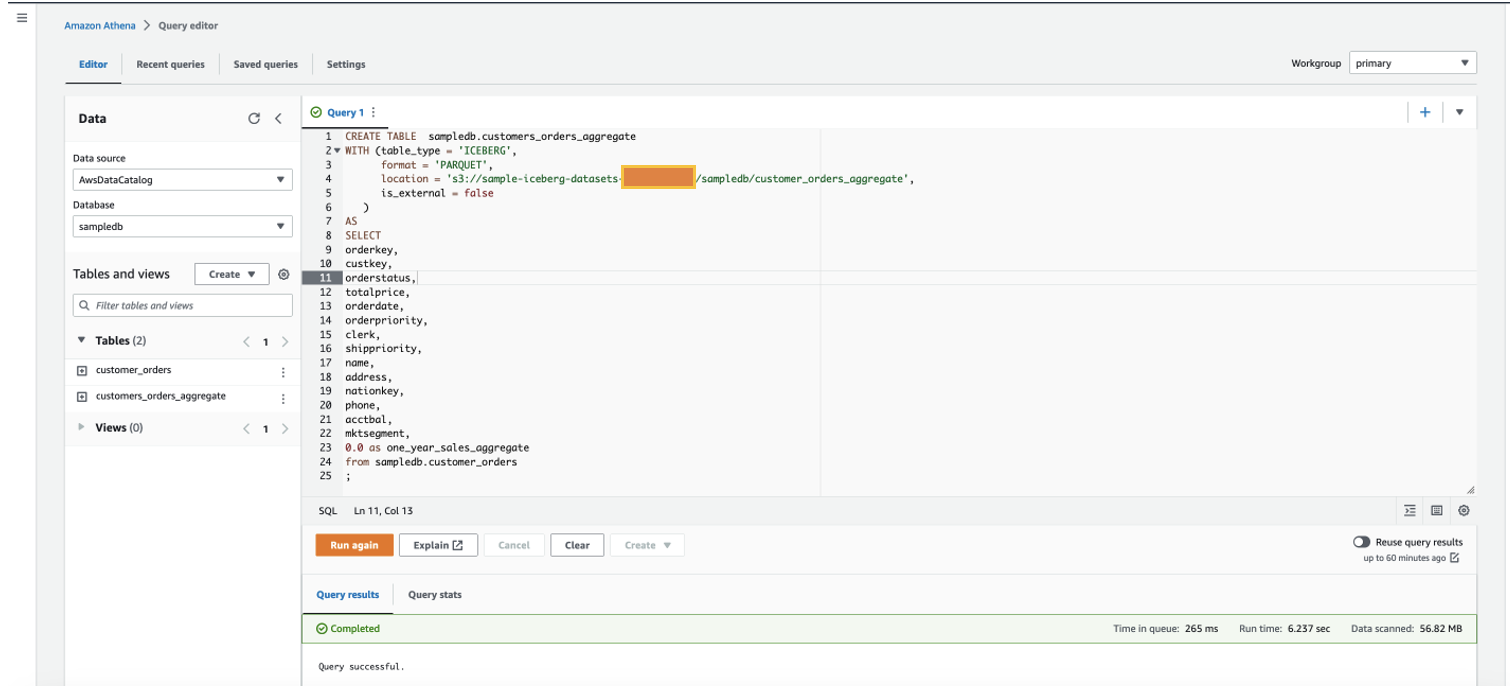
在以下 CTAS 查询中,添加了一个名为
one_year_sales_agg
regate 的新列,其默认值为
双
精度数据类型的
0.0
, 并将 table_type 设置为 ICE BERG:
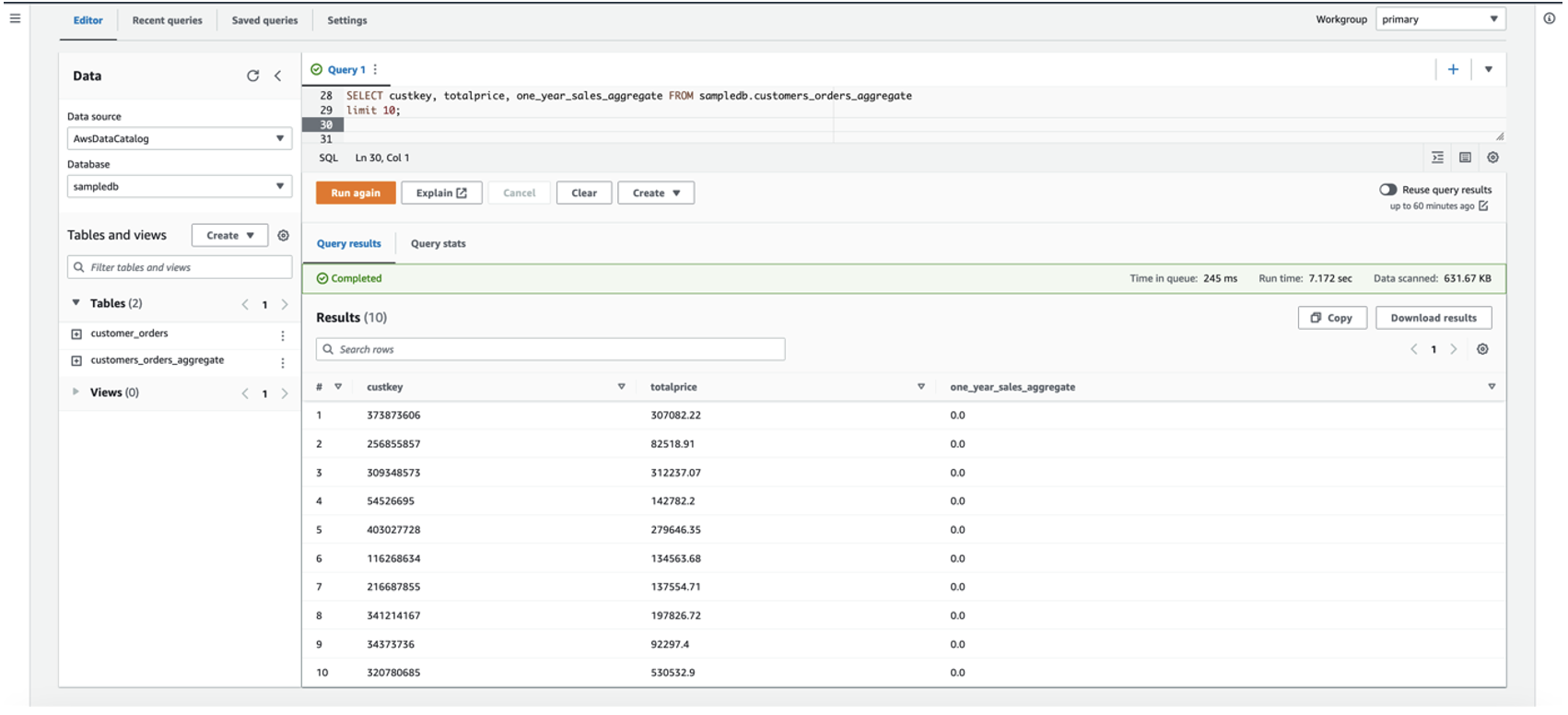
发出以下查询以验证 Apache Iceberg 表中的数据,其中新列
one_year_sales_
aggregate 值为 0.0:
我们想 在数据集中填充新功能
one_year_sales_agg
regate 的值,以根据每位客户在过去一年(数据集的最大年份)的购买量来获得他们的总购买金额。
使用 Athena 向 Apache Iceberg 表发出 MERGE 查询语句,填充 one_year_sales_aggregate 功能的值:
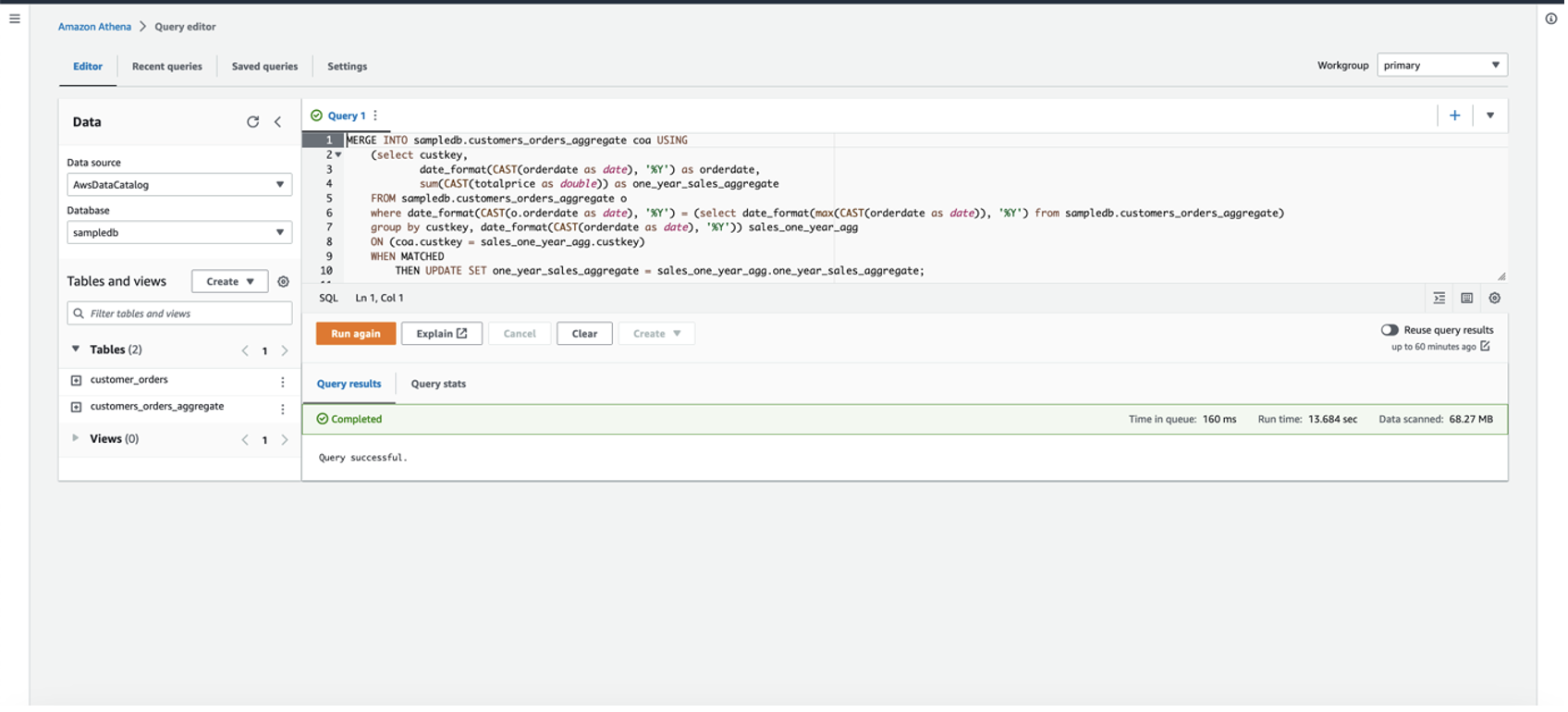
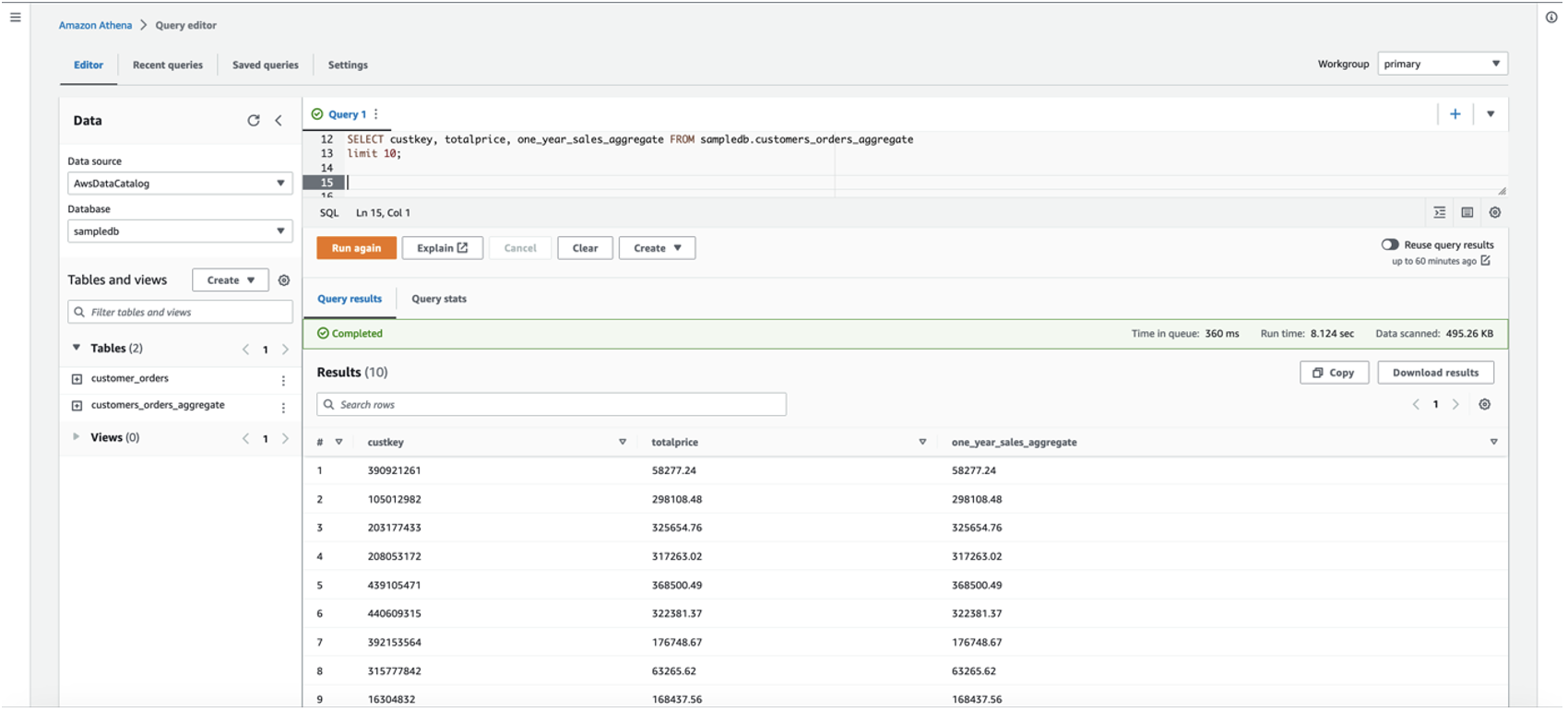
发出以下查询以验证过去一年中每位客户总支出的更新值:
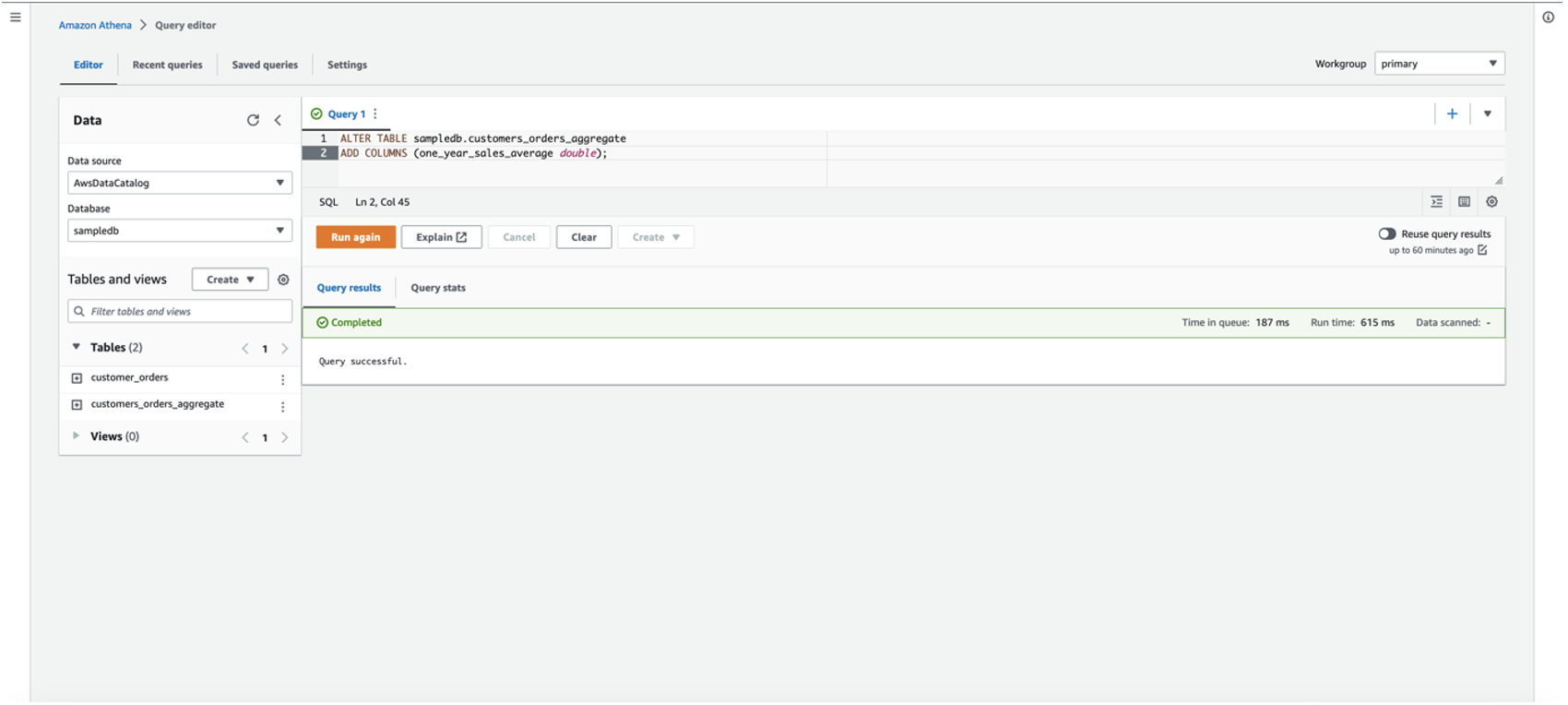
我们决定在现有的 Apache Iceberg 表中添加另一项功能,以计算和存储每位客户在过去一年的平均购买金额。发出 ALTER 查询语句,为功能
one_year_sales_
average 的现有表中添加新列:
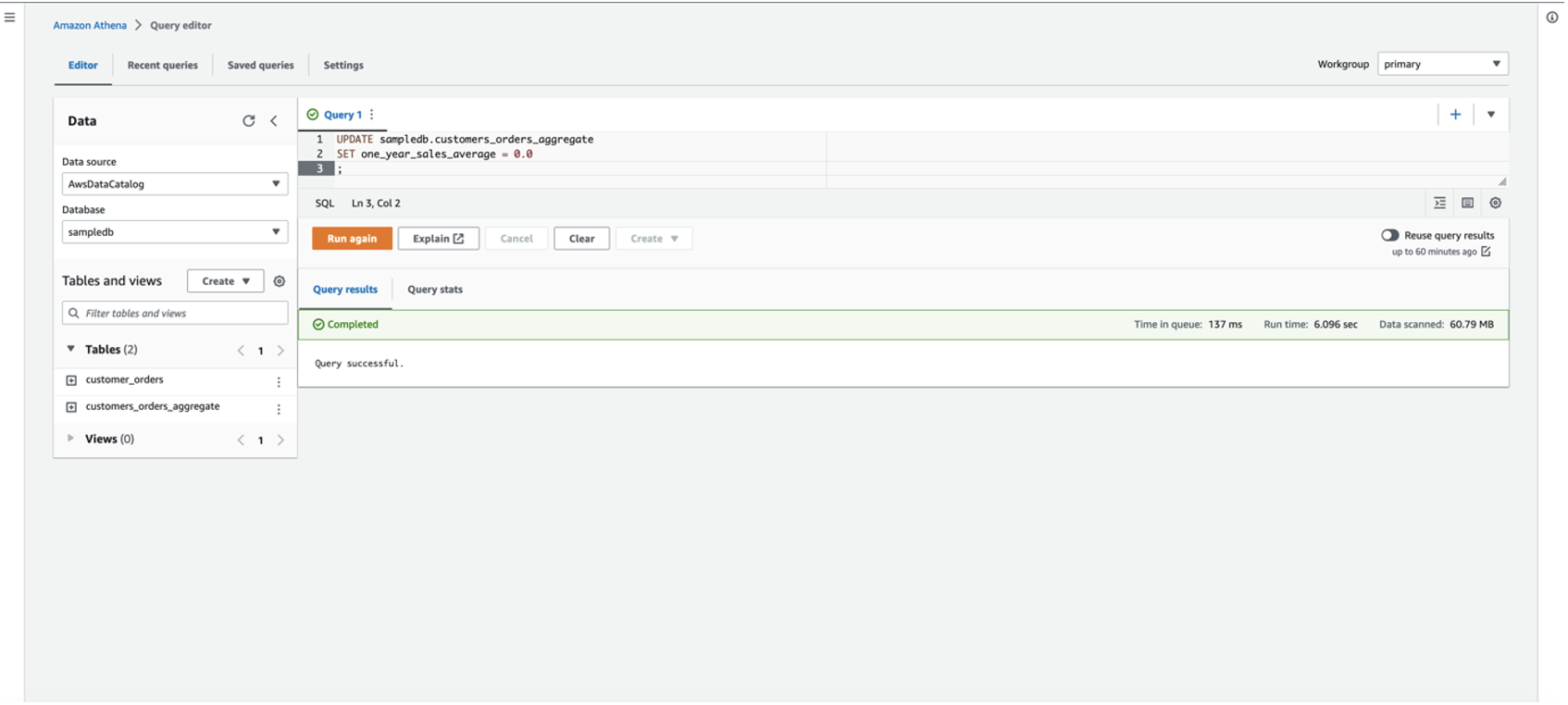
在填充此新功能的值之前,您可以将
one_year_sales_
average 功能的默认值设置为 0.0。
在雅典娜上使用相同的 Apache Iceberg 表,发出更新查询语句,将新功能的值填充为 0.0:
发出以下查询,验证过去一年中每位客户平均支出的更新值是否设置为
0.0:
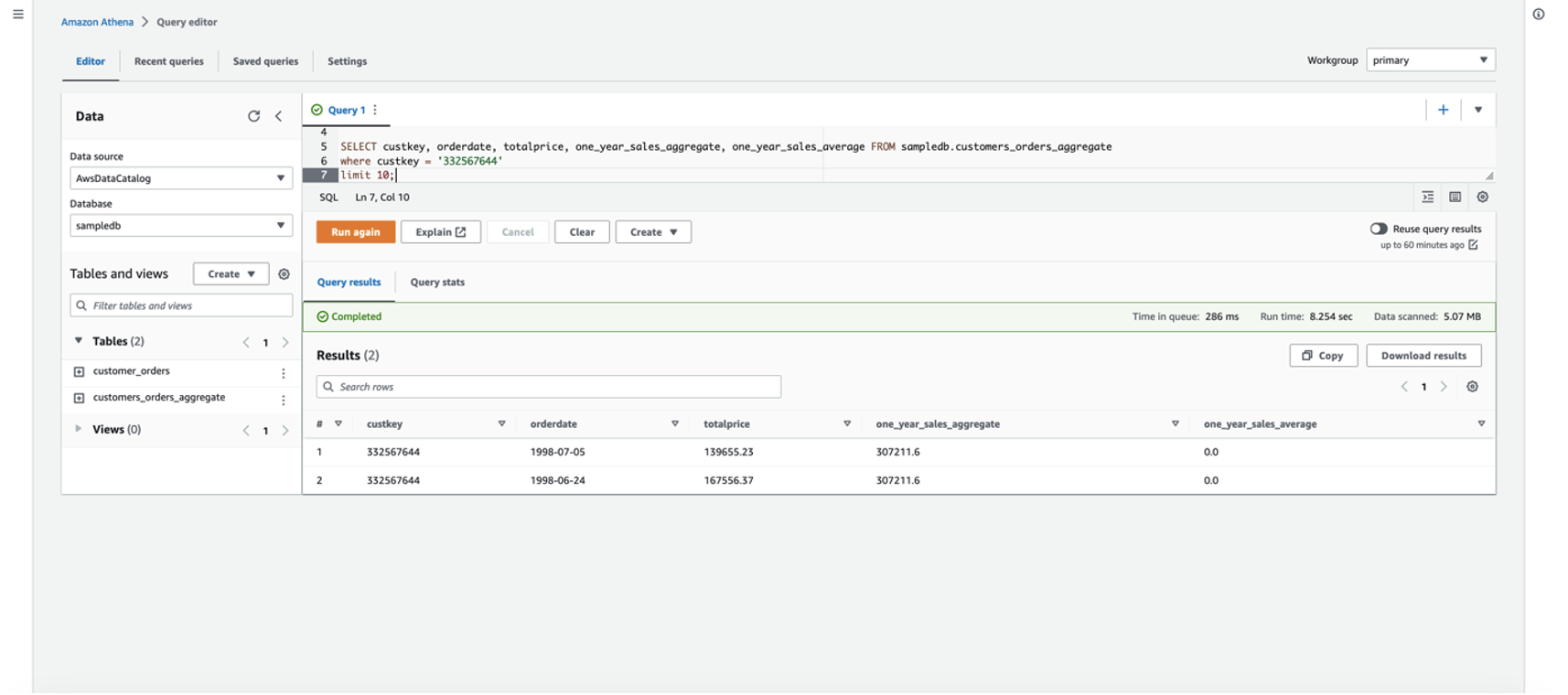
现在,我们要 在数据集中填充新功能
one_year_sales_
average 的值,以根据每位客户在过去一年(数据集的最大年份)的购买量获得平均购买金额。
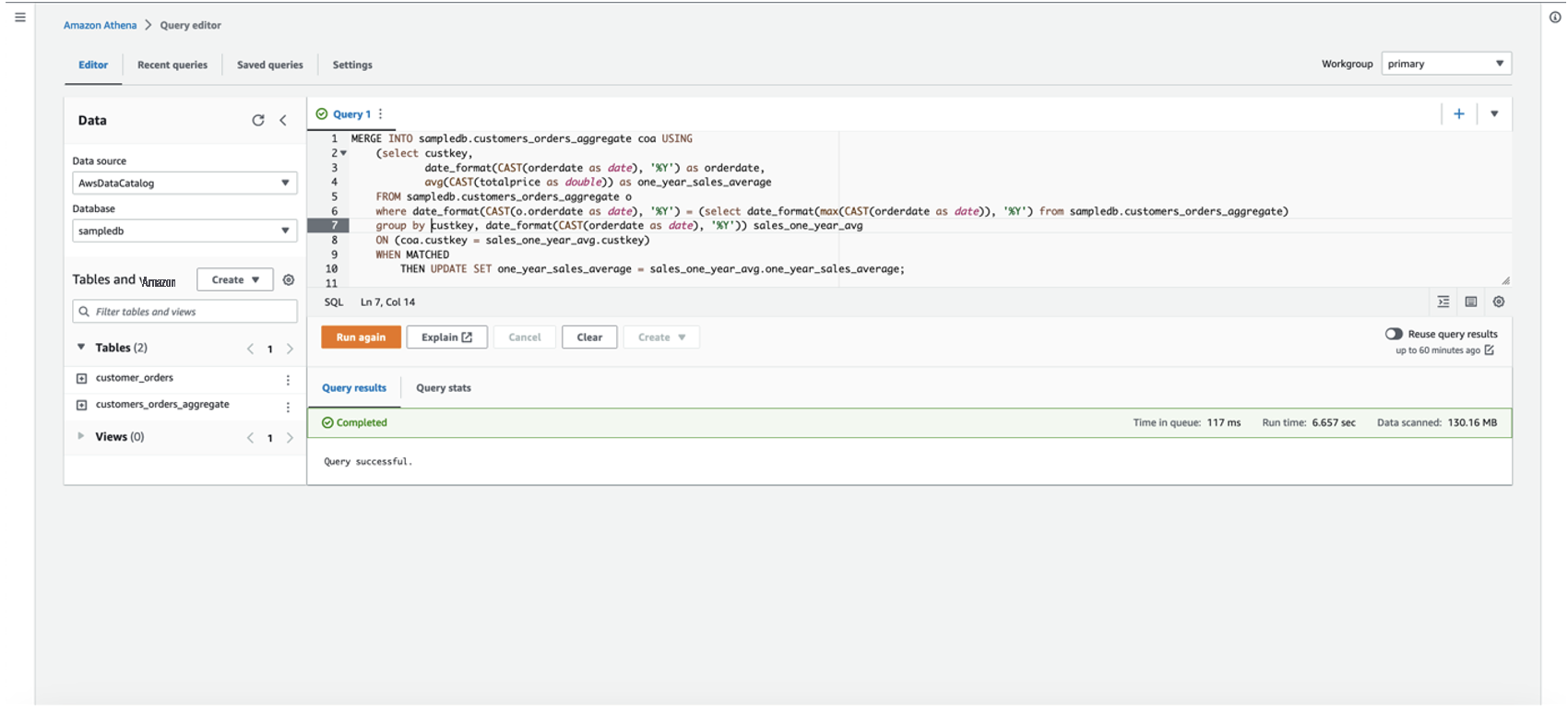
使用雅典娜引擎向雅典娜上的现有 Apache Iceberg 表发出 MERGE 查询语句,以填充 one_year_sales_average 功能的值:
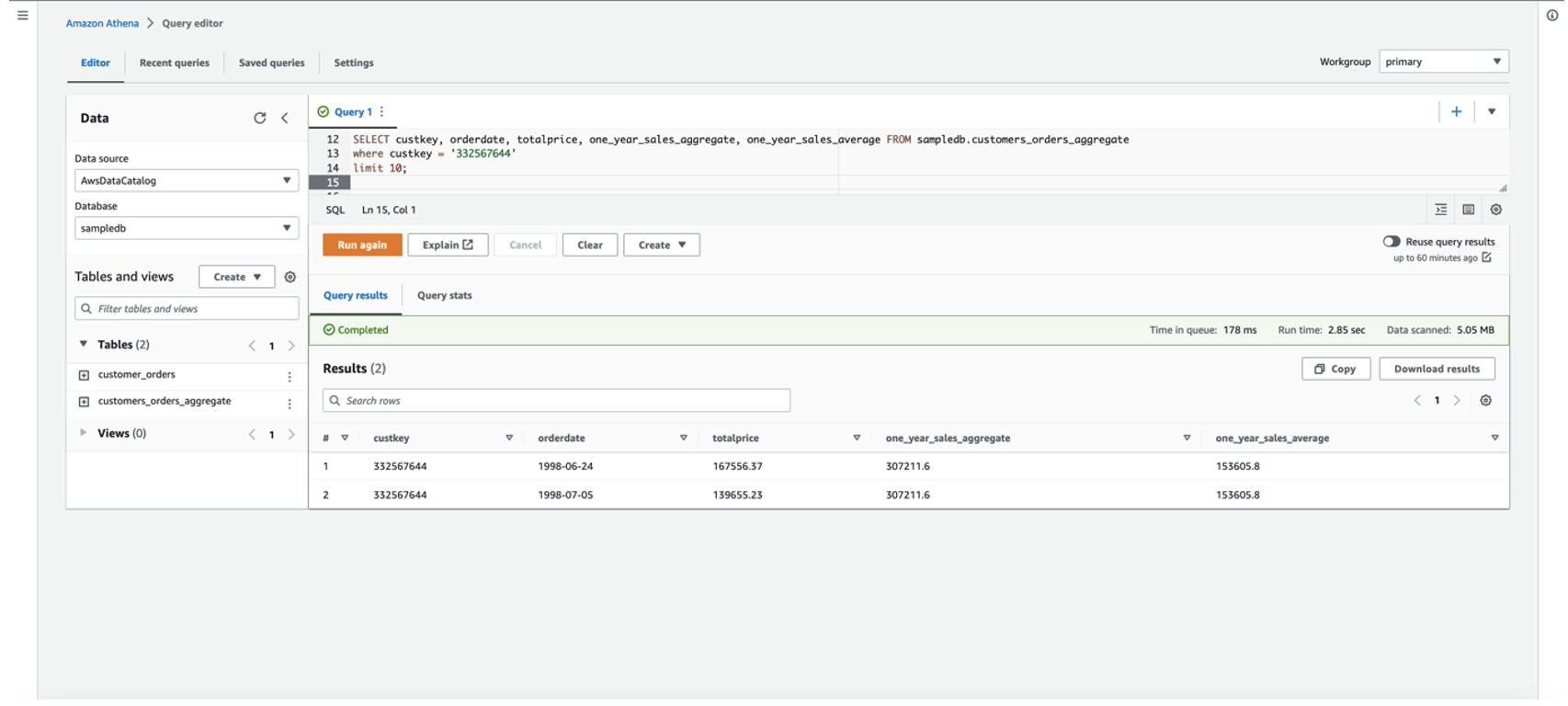
发出以下查询以验证每位客户平均支出的最新值:
向数据集添加其他数据特征后,数据科学家通常会开始训练 ML 模型并使用 Amazon Sagemaker 或等效工具集进行推断。
结论
在这篇文章中,我们演示了如何使用雅典娜和 Apache Iceberg 进行功能工程。我们还演示了使用 CTAS 查询从 Apache Parquet 格式的现有数据集在雅典娜上创建 Apache Iceberg 表,使用 ALTER 查询在雅典娜的现有 Apache Iceberg 表中添加新功能,以及使用 UPDATE 和 MERGE 查询语句更新现有列的特征值。
我们鼓励您使用 CTAS 查询来快速高效地创建表,并使用 MERGE 查询语句一步同步表,以便在使用 Athena 和 Apache Iceberg 转换功能时简化数据准备和更新任务。如果您有意见或反馈,请将其留在评论部分。
作者简介




*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。