发布于: Nov 30, 2022
【概要】数据可视化怎么做?重要洞见如何提取?在接下来的文章中我们会手把手教你如何操作。
数据可视化怎么做?重要洞见如何提取?在接下来的文章中我们会手把手教你如何操作。在部署这套架构之前,大家需要首先完成以下准备工作:
- 安装 Git。
- 在您的系统上安装 Amazon Serverless Application Model (Amazon SAM) CLI。关于更多操作说明,请参阅安装 Amazon SAM CLI。请使用以下代码,保证您安装的是最新版本:
sam --version
为了简化部署流程,本文将通过 Amazon CloudFormation 提供完整的基础设施即代码架构方案,您可以在 Forecast Visualization Automation Blogpost GitHub repo 上轻松获取相关代码。另外,我们还将使用 Amazon SAM 部署这套解决方案。
- 克隆这套 Git repo,详见以下代码:
大家可以通过 Forecast Visualization Automation Blogpost GitHub repo 获取相关代码。
- 导航至刚刚创建完成的 amazon-forecast-samples/ml_ops/visualization_blog 目录,并输入以下代码以启动解决方案部署:

在这一部分,Amazon SAM 将构建一套 CloudFormation 模板变更集。几秒之后,Amazon SAM 会提示您部署 CloudFormation 栈。
- 为栈部署提供参数。本文使用以下参数;您也可以直接使用默认参数:
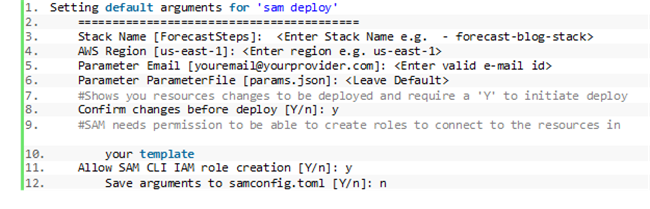
Amazon SAM 创建一套 Amazon CloudFormation 变更集,并要求确认。
- 输入 Y。
关于变更集的更多详细信息,请参阅使用变更集更新栈。
在成功部署之后,大家将看到以下输出结果:
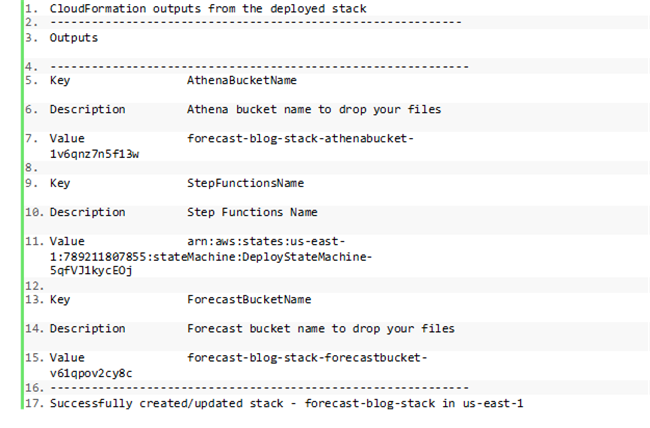
- 在 Amazon CloudFormation 控制台的 Outputs 选项卡上记录 ForecastBucketName 的值,我们将在测试步骤中使用该值。
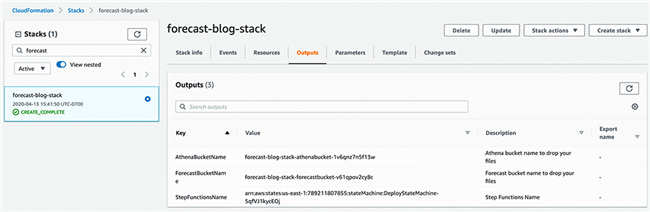
以下步骤概述了如何测试示例架构。要触发 Step Functions 工作流,大家需要将两个文件上传至新创建的 S3 存储桶:参数文件,以及时间序列训练数据集。
- 在克隆 GitHub repo 所在的同一目录中输入以下代码,将其中的 YOURBUCKETNAME 部分替换成我们之前在 Amazon CloudFormation Outputs 选项卡中复制到的值:

以上命令将复制 Lambda 函数用于配置您 Forecast API 调用的参数文件。
- 输入以下代码,执行时间序列数据集上传:
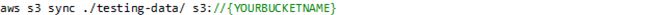
- 在 Step Functions 仪表板中,找到名为 DeployStateMachine-<random string>的状态机。
- 选择该状态机以查看工作流的执行情况。
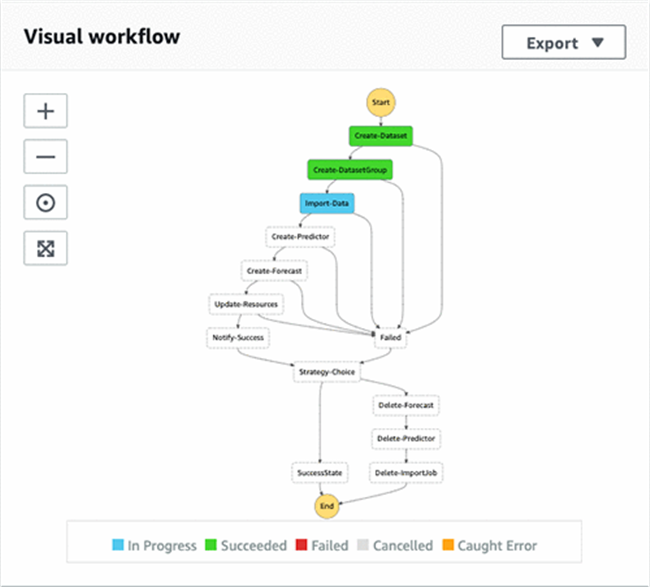
如以上截屏所示,全部成功执行的步骤(Lambda 函数)都处于绿色框体当中,蓝色框体表示步骤仍在进行当中,而所有无颜色框体则代表正等待执行的步骤。完成整个工作流中的所有步骤最多可能需要 2 个小时。
在工作流成功完成之后,您可以前往 Amazon S3 控制台并找到包含以下目录的 Amazon S3 存储桶:
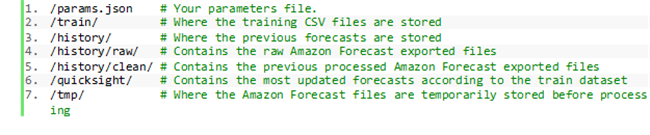
参数文件 params.json 中保存有从 Lambda 函数中调用 Forecast API 的属性。这些参数配置中包含的信息包括预测类型、预测器设置以及数据集设置,此外还有预测域、频率以及维度。关于 API 操作的更多详细信息,请参阅 Amazon Forecast Service。
现在,您的数据已经存在于 Amazon S3 当中,大家可以对结果进行可视化处理了。
要完成整个预测管道,我们还需要对数据进行查询与可视化。Athena 是一项交互式查询服务,可使用标准 SQL 轻松分析 Amazon S3 中的数据。QuickSight 则是一项基于云的快速商务智能服务,可通过数据可视化轻松帮助您获取洞见。要开始分析数据,您首先需要使用 Athena 作为数据源并将数据摄取至 QuickSight 当中。
如果您刚刚接触 Amazon Web Services,请设置 QuickSight 以创建一个 QuickSight 账户。如果您已经拥有 Amazon Web Services 账户,请订阅 QuickSight 服务以创建相应的新账户。
如果这是您第一次在 QuickSight 上使用 Athena,则需要向 QuickSight 授权权限以使用 Athena 查询 Amazon S3。关于更多详细信息,请参阅配合 Amazon QuickSight 使用 Athena 时的权限不足问题。
- 在 QuickSight 控制台上,选择 New Analysis。
- 选择 New Data Set。
- 选择 Athena。
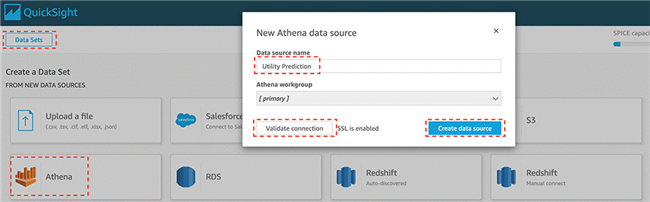
- 在 New Athena data source 窗口中的 Data source name 部分,输入一项名称,例如 Utility Prediction。
- 选择 Validate connection。
- 选择 Create data source。
这时次显示 Choose your table 窗口。
- 选择 Usecustom SQL。
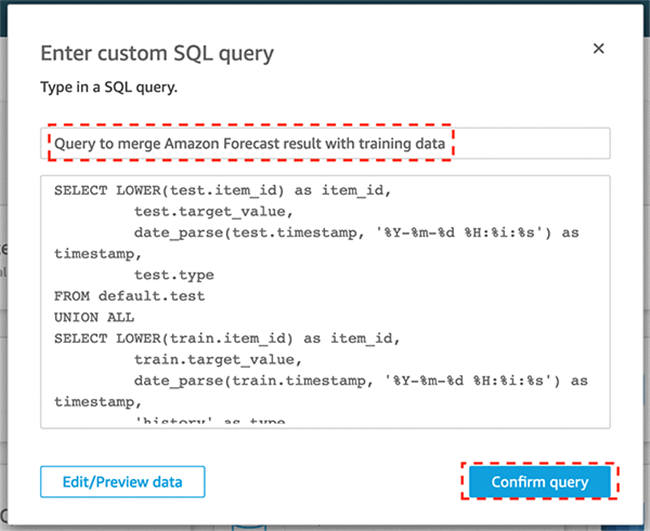
- 在 Enter custom SQL query 窗口中,输入您的查询名称,例如 Query to merge Forecast result with training data。
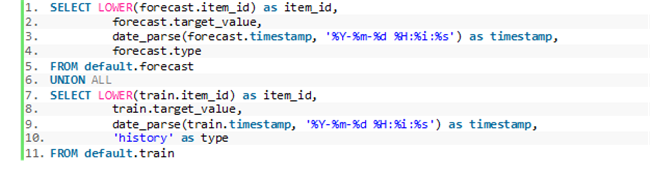
- 在查询文本框中输入以下代码:
现在,您可以选择将数据导入 SPICE 或者直接对数据执行查询了。
- 选择任一选项,而后选择 Visualize。
您将在 Fields list 之下看到以下字段:
- item_id
- target_value
- timestamp
- type
导出的预测结果将包含以下字段:
- item_id
- date
- 要求的分位数 (P10, P50, P90)
其中的 type 字段包含预测窗口的分位数类型 (P10, P50, P90) ,而 history 字段将作为训练数据的分位数。这一过程将通过自定义查询完成,以确保在历史数据与导出的预测结果之间保持统一的历史界线。
大家可以使用 CreateForecast API 可选参数调用 ForecastType,借此实现分位数自定义。在本文的用例中,您可以在 Amazon S3 中的 params.json 文件下完成这项配置。
- 在 X axis 部分,选择 timestamp。
- 在 Value 部分,选择 target_value。
- 在 Color 部分,选择 type。
在参数当中,我们指定了 72 小时范围。要对结果进行可视化,大家需要以每小时一次的频率对时间戳字段进行聚合。
- 在 timestamp下拉菜单中,选择 Aggregate 与 Hour。
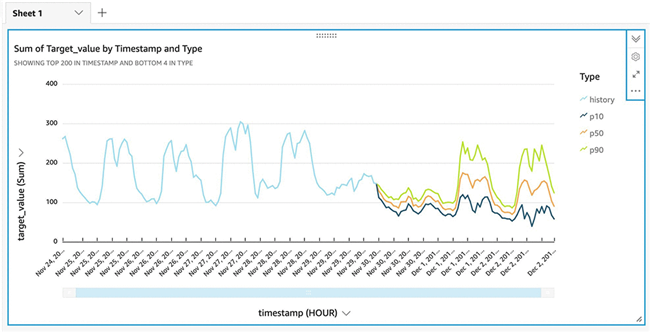
以下截屏所示,为您的最终预测结果。图中所示为分位数 P10、P50m 以及 P90 的预测结果,以及与之对应的概率预测。
每个组织都能够从更准确的预测当中受益,从而更好地预测产品需求、优化计划与供应链动态等等。预测需求是一项艰巨的任务,而机器学习技术能够显著缩小预测与现实之间的差距。
本文向大家展示了如何创建可重复、基于 AI 的自动预测生成流程。大家还了解到如何使用无服务器技术建立机器学习运营管道,并使用托管分析服务通过数据查询与可视化以提取重要洞见。
相关文章